Deep Learning Dynamics: An Ablation Study on MNIST
تفاصيل العمل
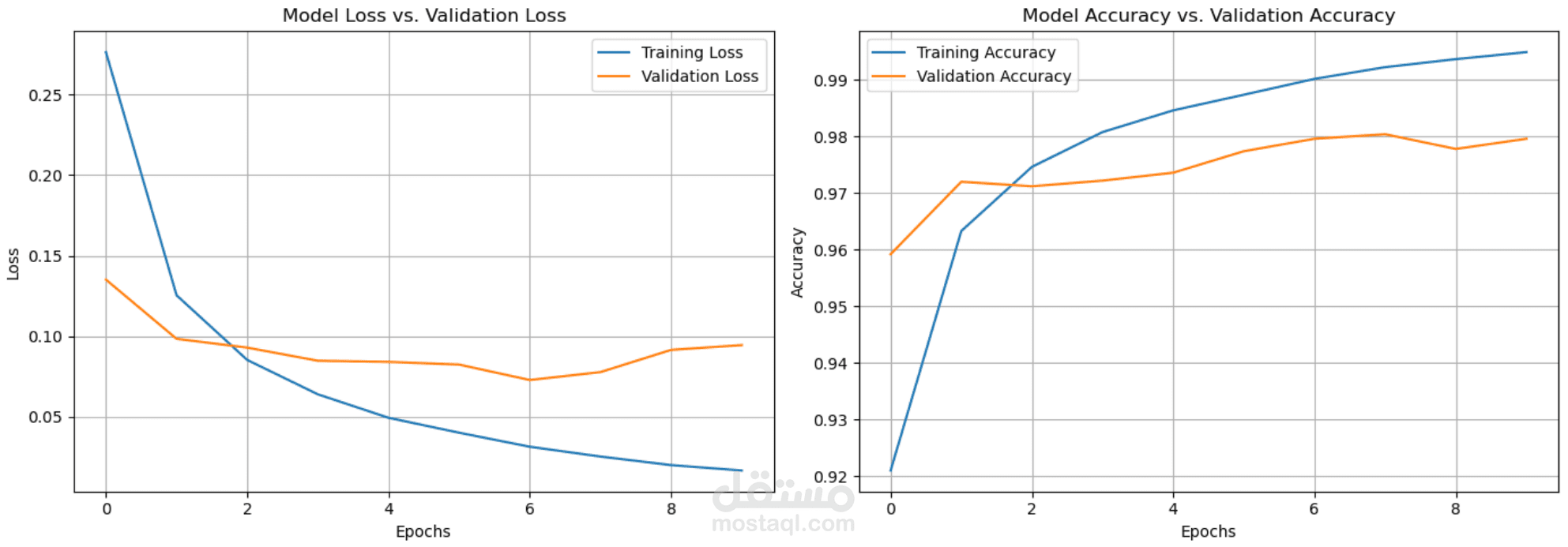
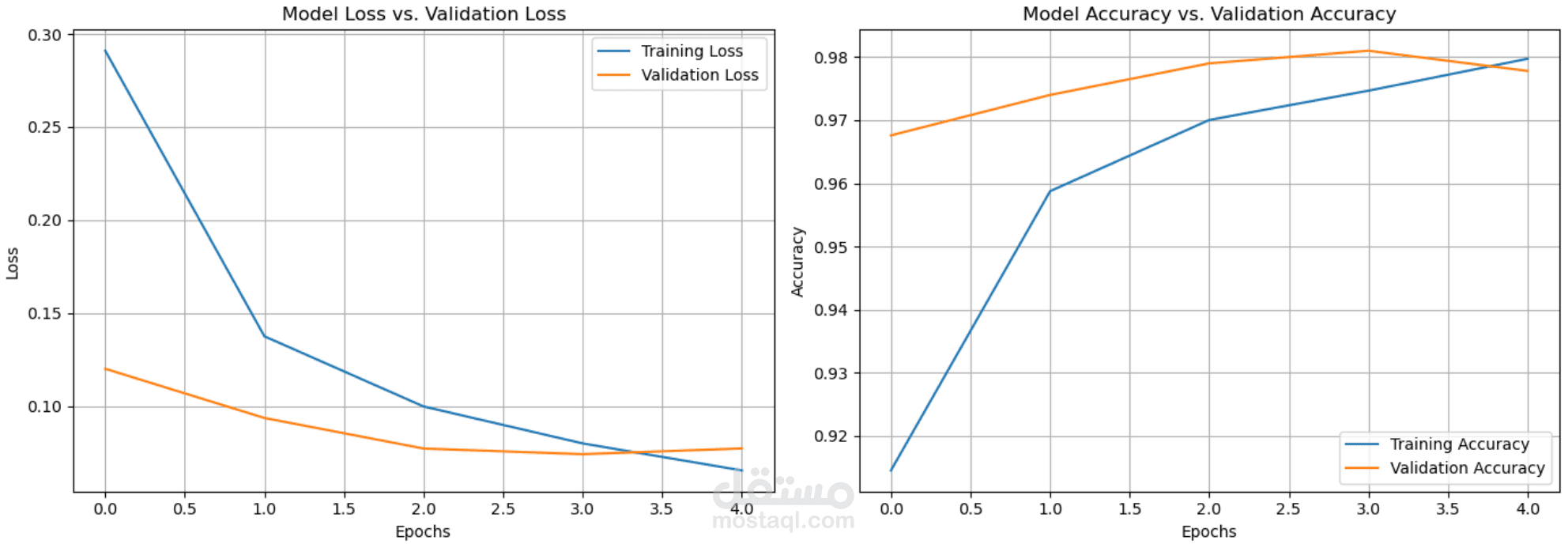
A hands-on experimental study focused on the internal behavior and training dynamics of Artificial Neural Networks. Using the MNIST dataset, the project systematically investigates how architectural choices and hyperparameters influence model convergence, stability, and generalization through rigorous ablation testing.
Key Contributions:Systematic Ablation Testing: Conducted controlled experiments to isolate the effects of optimizers (SGD vs. Adam), batch sizes, and activation functions ($ReLU$, $Sigmoid$, $Tanh$) on gradient flow.Behavioral Analysis: Evaluated the trade-offs between training duration and generalization, specifically identifying the "elbow point" where regularization (Dropout, L2) becomes critical to prevent overfitting.Implementation & Benchmarking: Built, trained, and evaluated all model variants from scratch to visualize loss landscapes and accuracy plateaus, prioritizing deep-dive understanding over simple metric optimization
Tech Stack: Python, TensorFlow/PyTorch, NumPy, Matplotlib, Scikit-learn.