Customer Segmentation using DBSCAN & PCA (Unsupervised Learning Project)
تفاصيل العمل
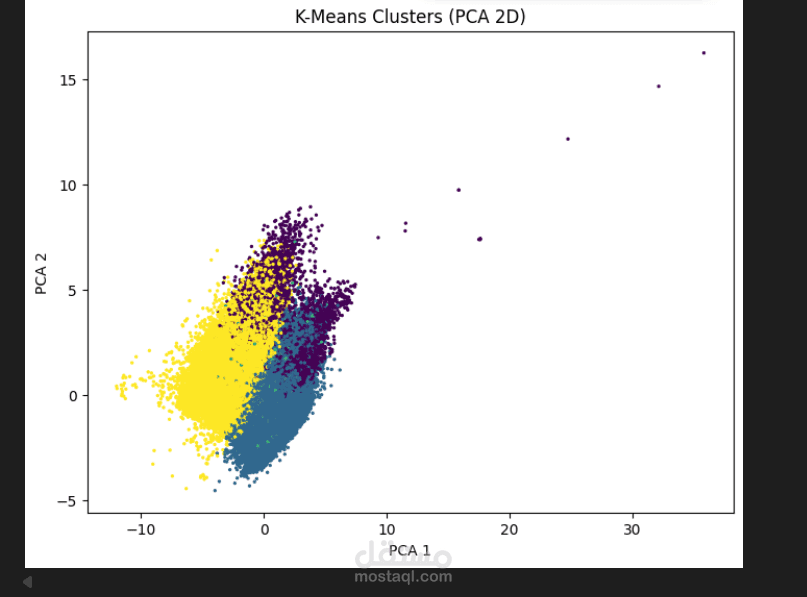
Performed an advanced unsupervised learning analysis to identify meaningful customer segments based on booking behavior.
The preprocessing pipeline included:
• Missing value handling
• Duplicate removal
• Outlier detection using IQR
• One-Hot Encoding
• Feature scaling using StandardScaler
• Dimensionality reduction using PCA
Two clustering algorithms were evaluated:
• K-Means
• DBSCAN
Evaluation Metrics:
• Silhouette Score
• Davies–Bouldin Index
Results:
DBSCAN significantly outperformed K-Means by producing more compact and well-separated clusters (Silhouette ≈ 0.247 vs 0.048). It also successfully detected noise points and handled irregular cluster shapes.
This project demonstrates practical expertise in clustering evaluation, dimensionality reduction, and real-world customer behavior analysis.