Smart Study Assistant: Automated PDF Processing
تفاصيل العمل
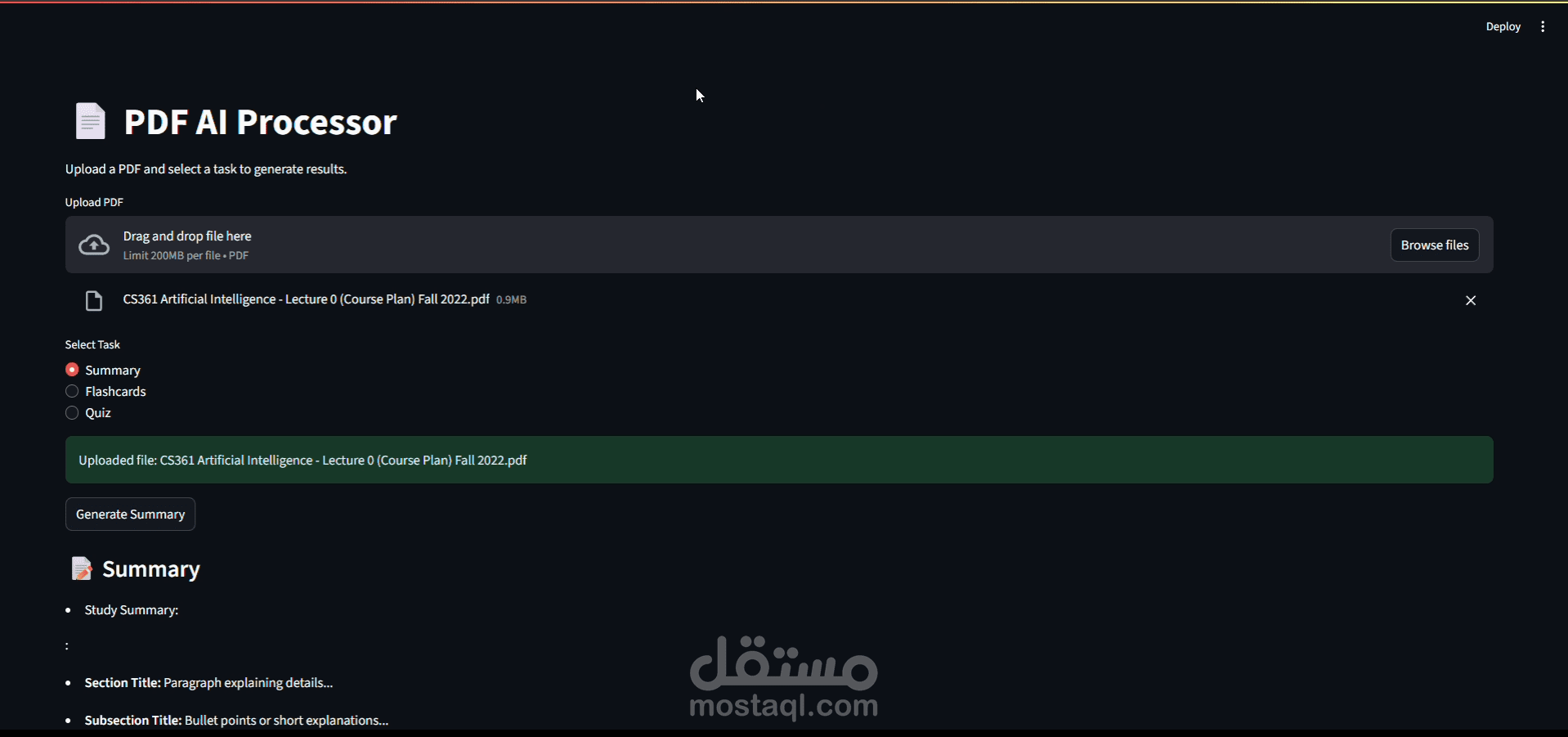
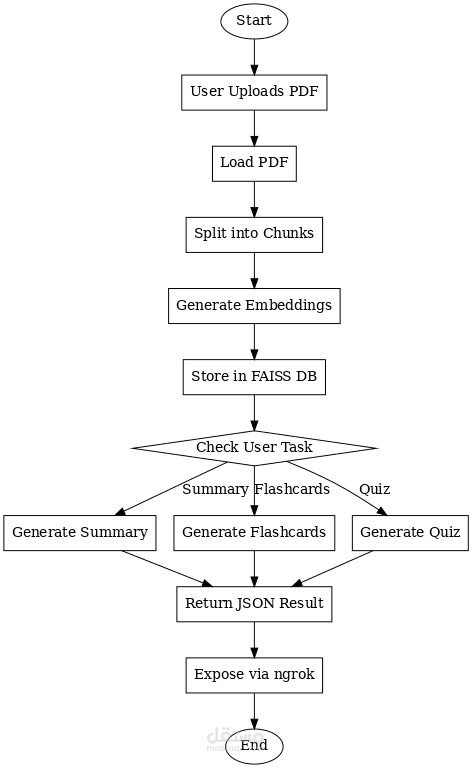
Project Overview:
Developed a robust backend pipeline designed to transform static PDF documents into interactive learning materials. The system leverages Retrieval-Augmented Generation (RAG) principles to process, store, and analyze data efficiently.
Technical Workflow:
Data Ingestion: Automated PDF loading and text extraction.
Text Processing: Implemented a recursive chunking strategy to prepare text for LLM processing.
Vector Storage: Integrated FAISS DB for high-performance similarity search after generating high-dimensional embeddings.
Dynamic Task Handling: A decision-making logic that routes user requests to generate tailored outputs: Summaries, Flashcards, or Interactive Quizzes.
API Delivery: Results are structured in JSON format and exposed via ngrok for seamless external integration and testing.