Diabetes health Indicator
تفاصيل العمل
Diabetes Health Indicators – Machine Learning Project
The Diabetes Health Indicators project is a supervised machine learning initiative aimed at early detection of diabetes using real-world clinical data. By analyzing routine health indicators, the system identifies patients at risk of diabetes, supporting timely intervention and improved healthcare outcomes.
Project Highlights:
Objective: Develop and evaluate machine learning models to accurately predict diabetes while prioritizing high recall and F1-score, minimizing missed diagnoses.
Data Processing: Cleaned and preprocessed clinical data (31 → 28 features), handled missing values via median/mode imputation, removed duplicates, standardized numerical features, and applied one-hot encoding to categorical variables.
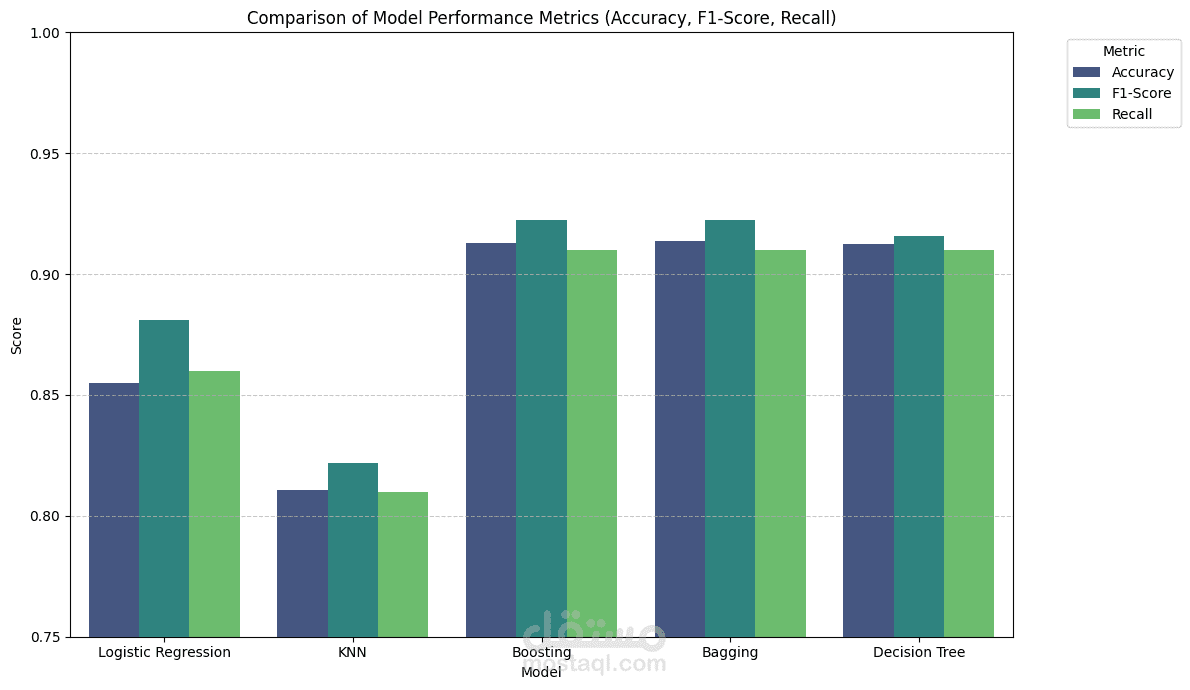
Models Evaluated: Logistic Regression, K-Nearest Neighbors (KNN), Decision Tree, Gradient Boosting, and Random Forest (Bagging).
Evaluation Metrics: Accuracy, Precision, Recall, F1-Score, ROC-AUC, Confusion Matrix.
Key Results:
Best Model: Random Forest achieved the highest F1-score (~0.923) and ROC-AUC (>0.94), demonstrating excellent balance between precision and recall.
Insights: HbA1c and postprandial glucose emerged as the strongest predictors; physical activity negatively correlates with diabetes risk.
Ensemble methods outperformed simpler classifiers, confirming the effectiveness of tree-based models for clinical prediction.
Visualizations Included: ROC curves, correlation heatmaps, and confusion matrices for comprehensive model evaluation.
This project provides a robust and reliable framework for early diabetes detection, demonstrating the potential of machine learning to support critical healthcare decision-making and improve patient outcomes.