نظام تصنيف النصوص غير اللائقة باستخدام تقنيات معالجة اللغات الطبيعية
تفاصيل العمل
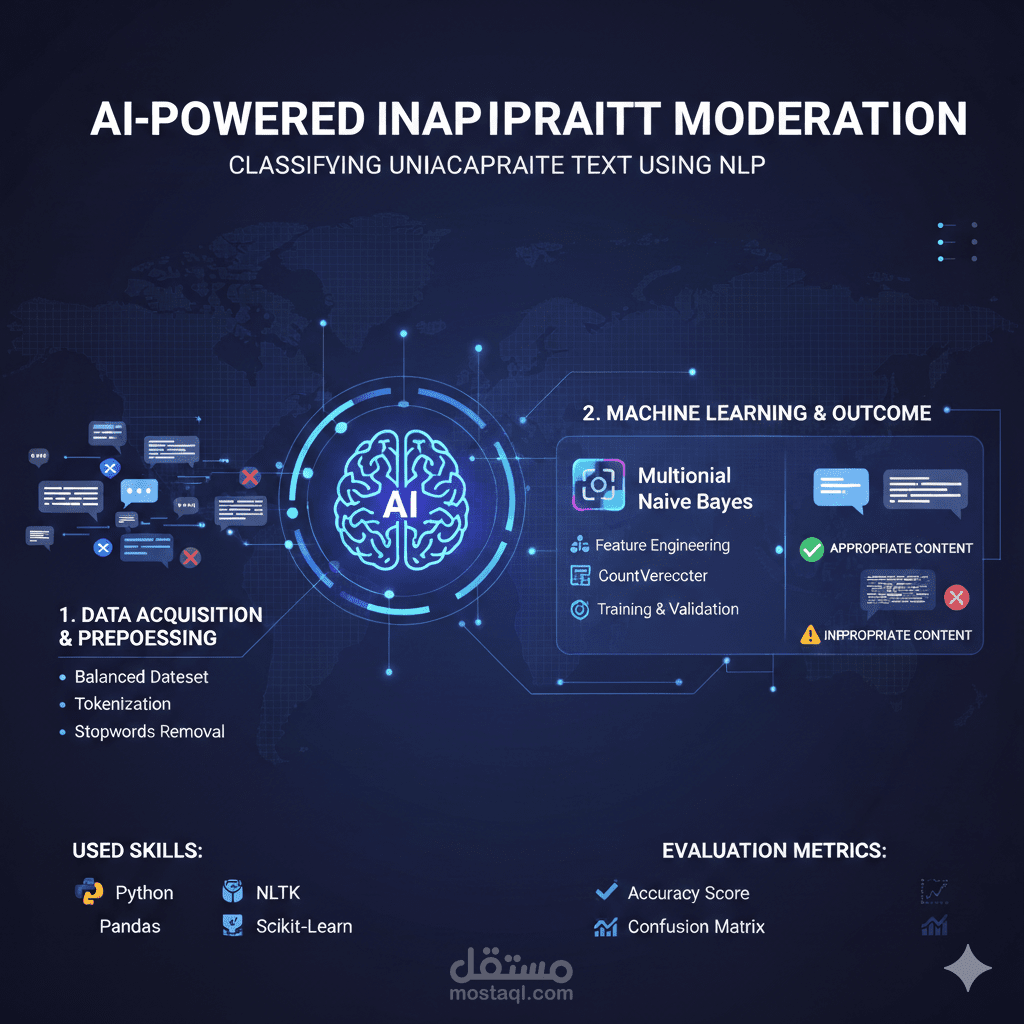


1. يهدف هذا المشروع إلى بناء أداة ذكاء اصطناعي قادرة على التمييز التلقائي بين النصوص "اللائقة" والنصوص "غير اللائقة" (المسيئة أو الحادة). صُمم النظام ليكون بمثابة "حارس رقمي" يمكن استخدامه في منصات التواصل الاجتماعي، المنتديات، أو تطبيقات الدردشة لحماية المستخدمين من خطاب الكراهية والمحتوى المسيء.
2. آلية العمل الفنية (Technical Workflow)
يمر المشروع بعدة مراحل هندسية دقيقة لضمان جودة التصنيف:
مرحلة معالجة البيانات (Data Preprocessing): تبدأ بتنظيف النصوص الخام عن طريق إزالة "الضجيج" مثل الروابط (URLs)، علامات الترقيم، والأرقام، مع توحيد حالة الحروف وتصفية الكلمات الشائعة التي لا تحمل قيمة تصنيفية (Stopwords).
تمثيل النصوص (Text Vectorization): تحويل الكلمات إلى لغة رياضية يفهمها الكمبيوتر باستخدام تقنية (Count Vectorization)، حيث يتم تحويل كل نص إلى مصفوفة من الأرقام تعبر عن تكرار الكلمات.
التعلم الآلي (Machine Learning): يعتمد المشروع على خوارزمية Multinomial Naive Bayes، وهي واحدة من أقوى الخوارزميات في تصنيف النصوص، حيث تتعلم الأنماط اللغوية التي تميز المحتوى غير اللائق عن غيره.
3. أبرز المميزات (Key Features)
دقة التصنيف: يتم تدريب النموذج على مجموعة بيانات متوازنة (Balanced Dataset)، مما يعني أنه قادر على التعرف على كلا النوعين من النصوص بكفاءة متساوية دون انحياز.
السرعة والكفاءة: اختيار خوارزمية Naive Bayes يجعل النظام سريعاً جداً في اتخاذ القرار، مما يسمح بفحص آلاف التعليقات في أجزاء من الثانية.
التقييم الشامل: لا يكتفي المشروع بالتصنيف فقط، بل يقدم تقارير أداء دقيقة تشمل "مصفوفة الارتباك" (Confusion Matrix) لمعرفة مواضع الخطأ وتحسينها مستقبلاً.