بناء نموذج تعلم آلة لتجميع وتصنيف البيانات
تفاصيل العمل

المنهجية المتبعة في المشروع:
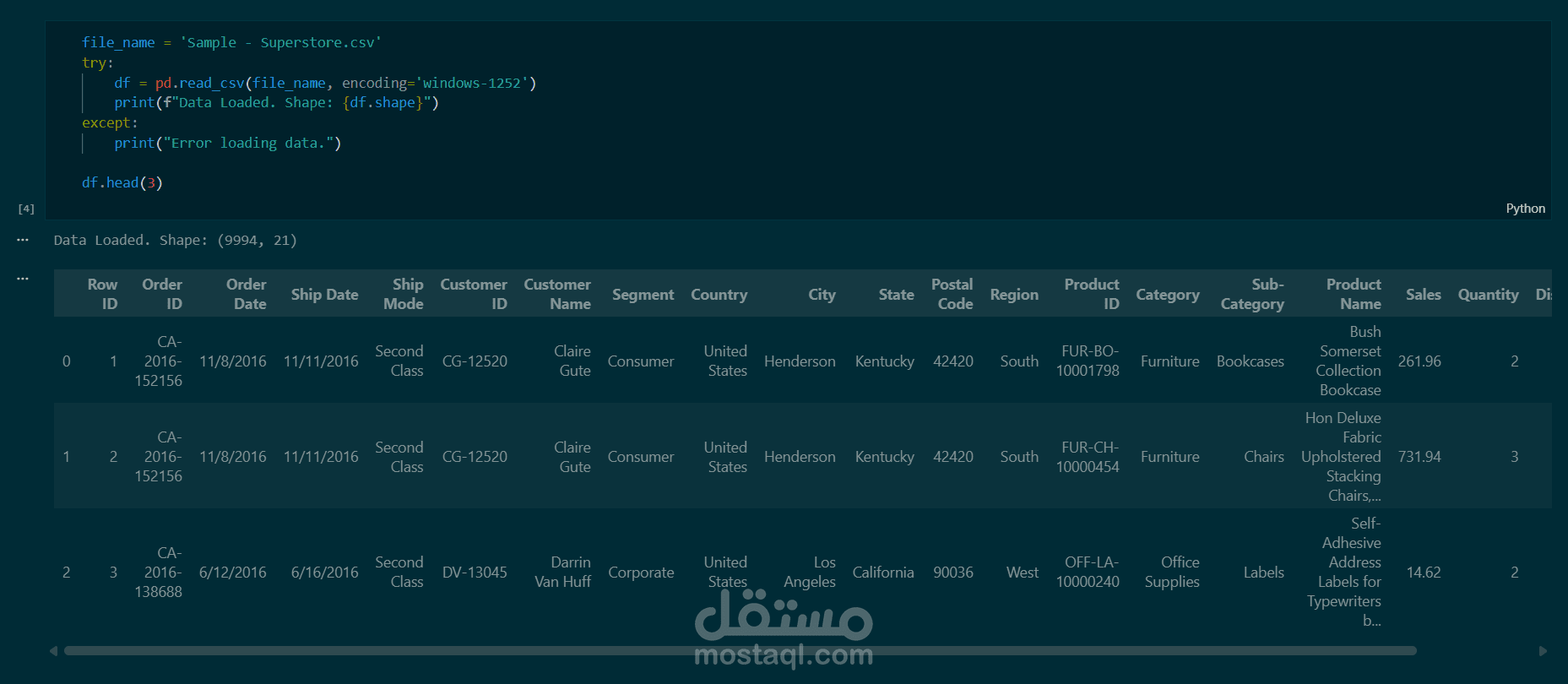
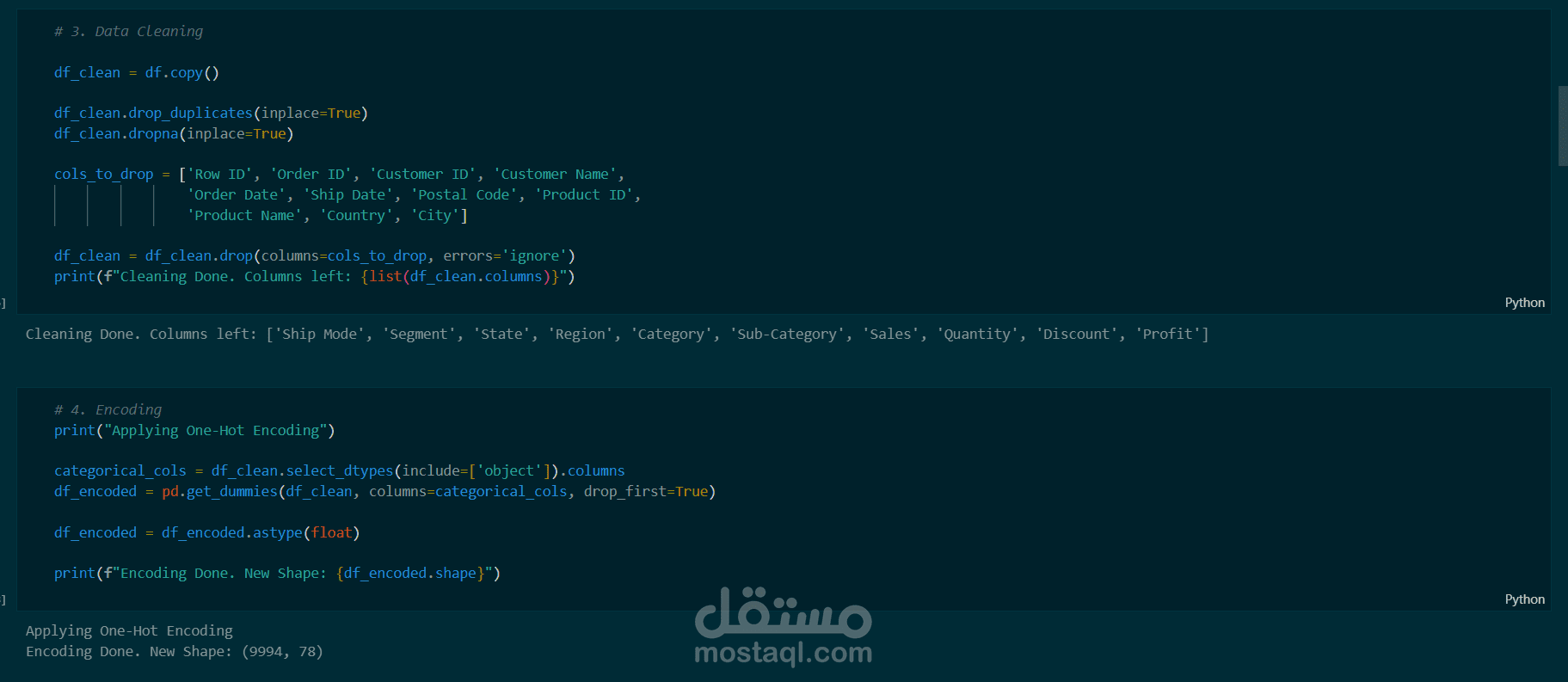
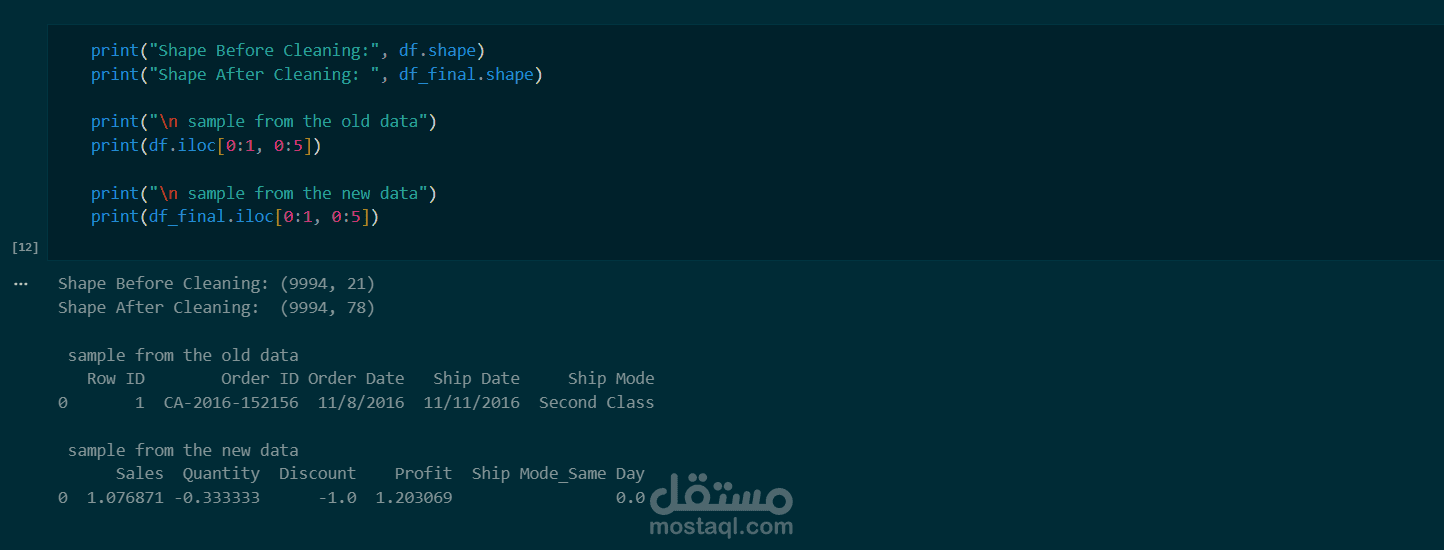
تجهيز البيانات (Data Preprocessing): تنظيف البيانات وحذف الأعمدة غير المؤثرة، وتطبيق One-Hot Encoding لتحويل البيانات النصية إلى رقمية.
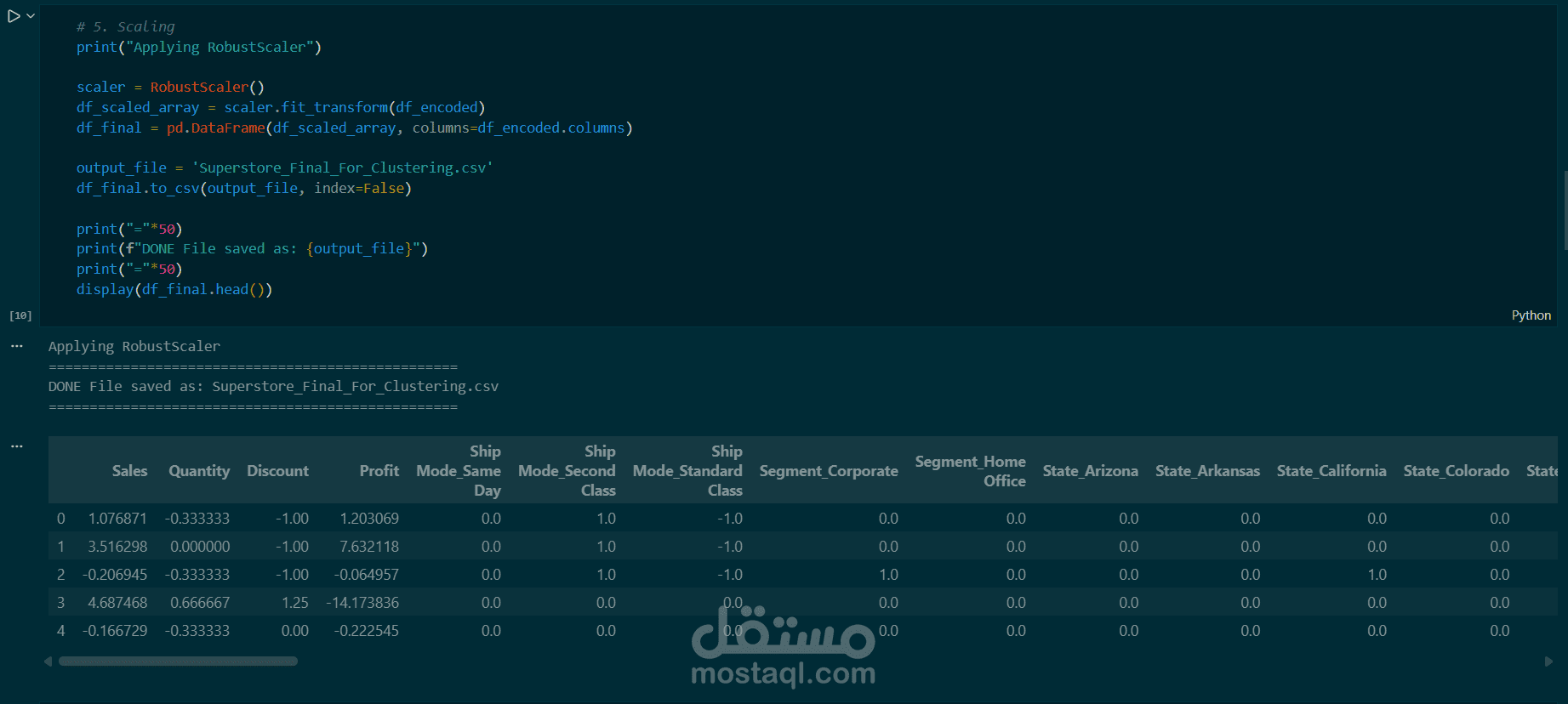
معالجة القيم الشاذة: استخدام RobustScaler لعمل Scaling للبيانات، وهو اختيار دقيق للتعامل مع القيم المتطرفة في بيانات المبيعات.
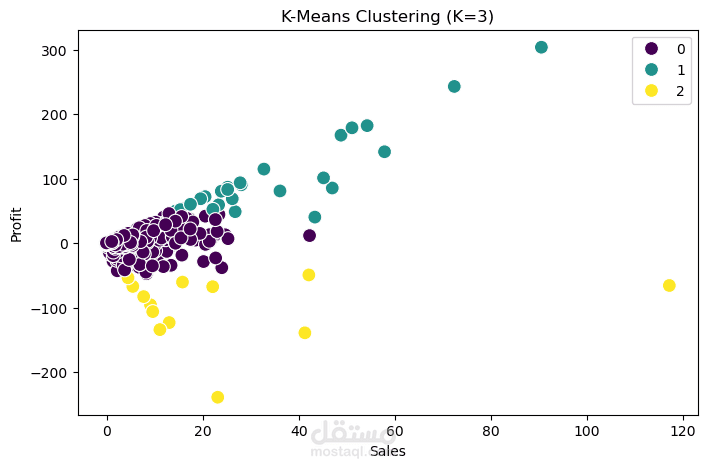
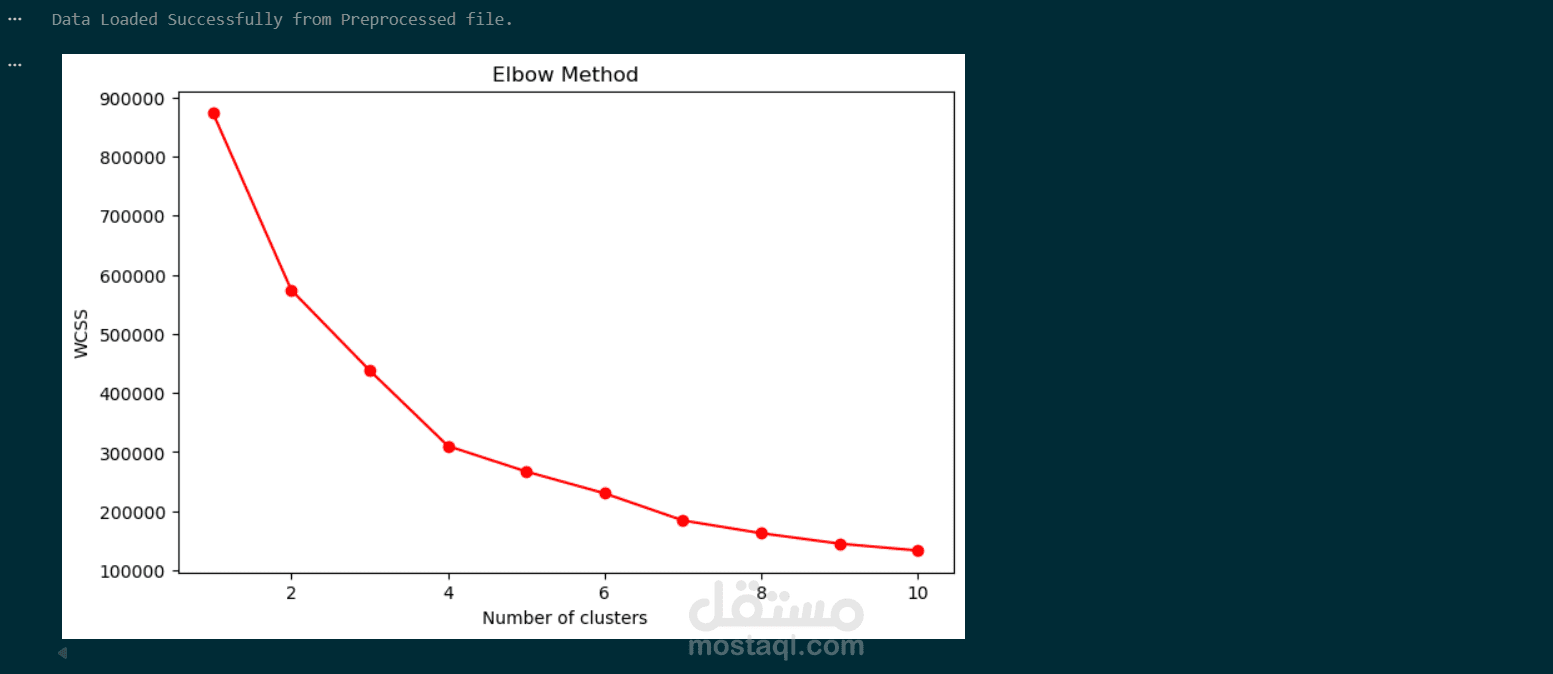
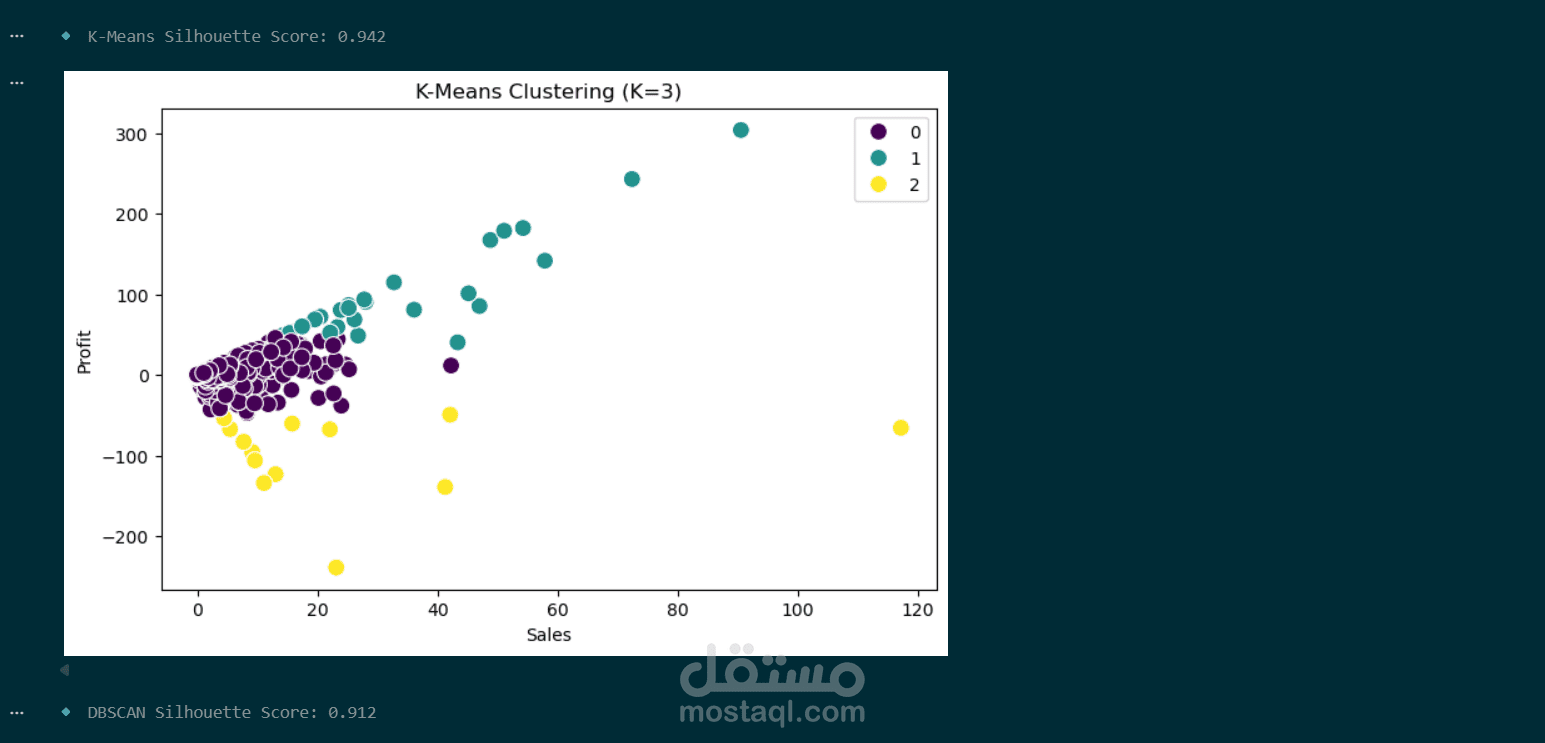
تحديد العدد الأمثل للمجموعات: استخدام طريقة Elbow Method لتحديد أن أفضل عدد للـ Clusters هو 3.
بناء النماذج والمقارنة:
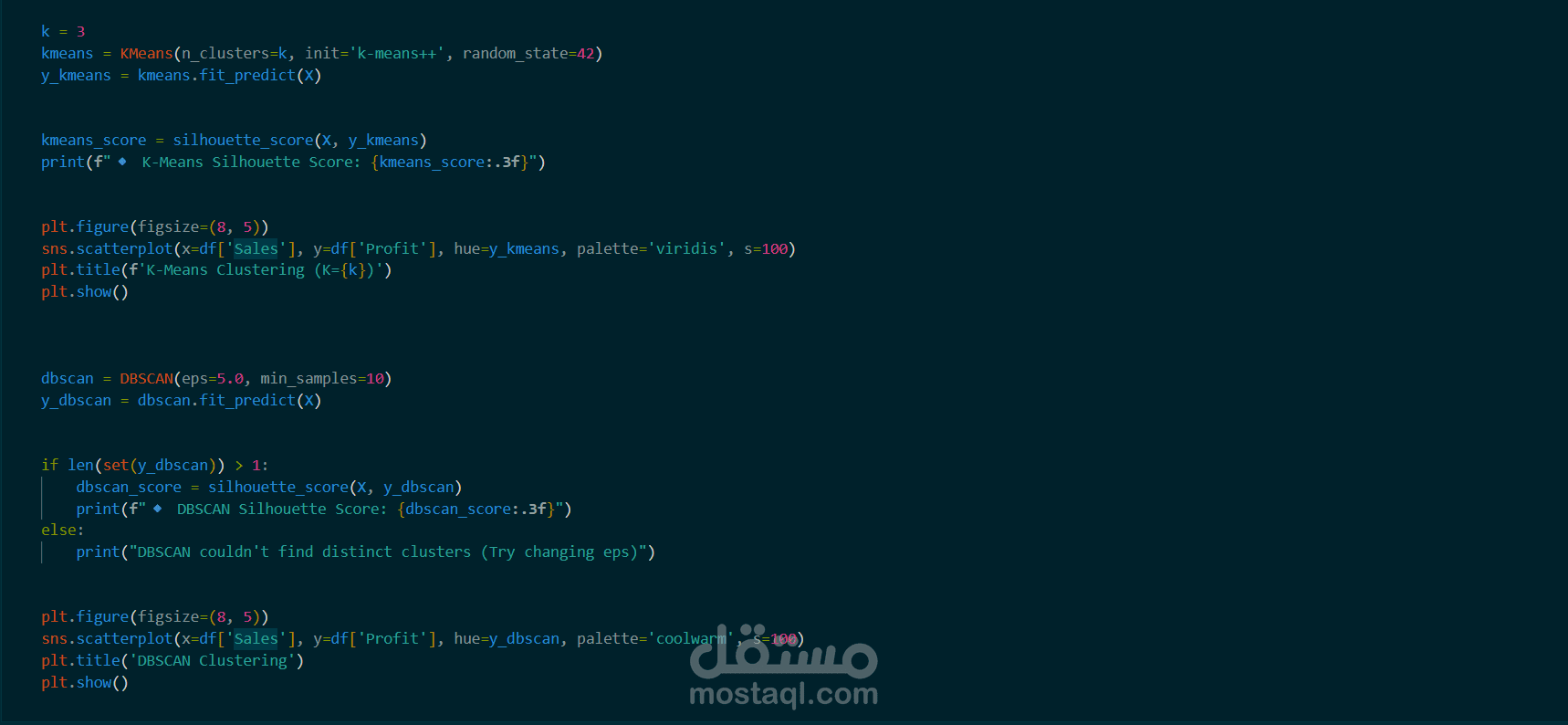
تطبيق خوارزمية K-Means (حقق دقة فصل Silhouette Score = 0.94).
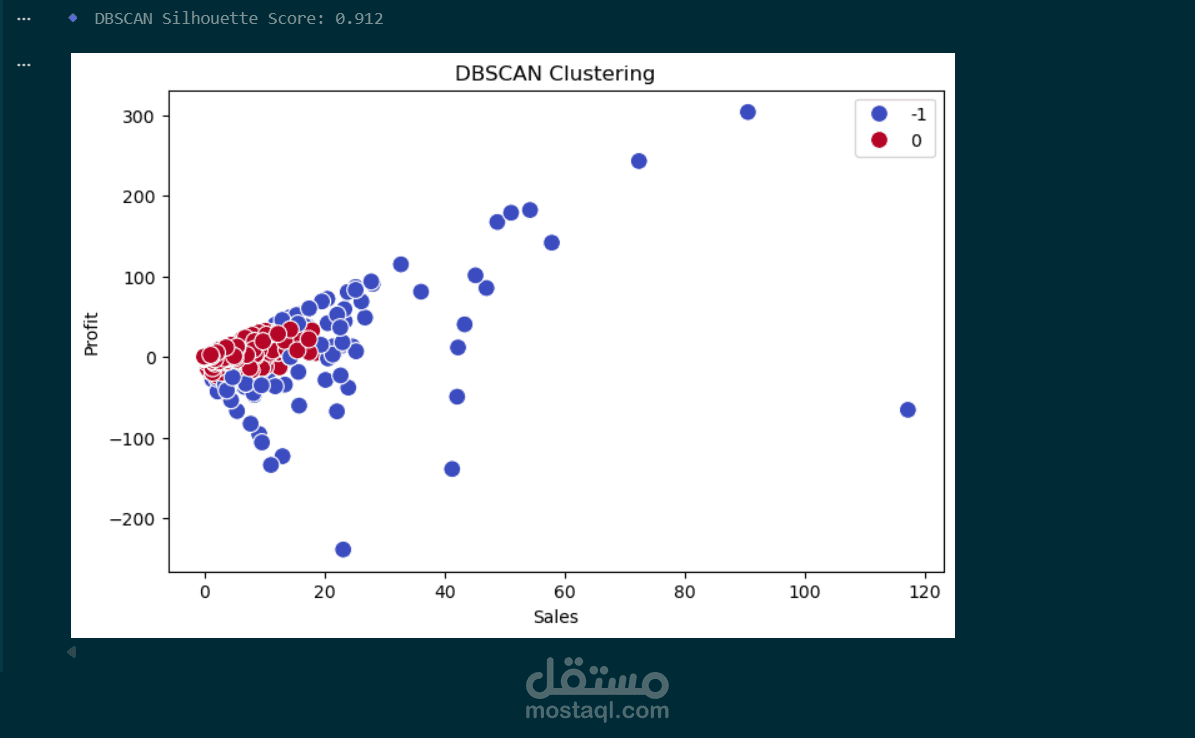
تطبيق خوارزمية DBSCAN لاكتشاف الكثافة والتعامل مع الـ Noise (حقق Score = 0.91).
التمثيل البصري: رسم النتائج لتوضيح العلاقة بين المبيعات (Sales) والأرباح (Profit) لكل شريحة عملاء.