بناء نموذج توقع قبول القرض للبنوك
تفاصيل العمل
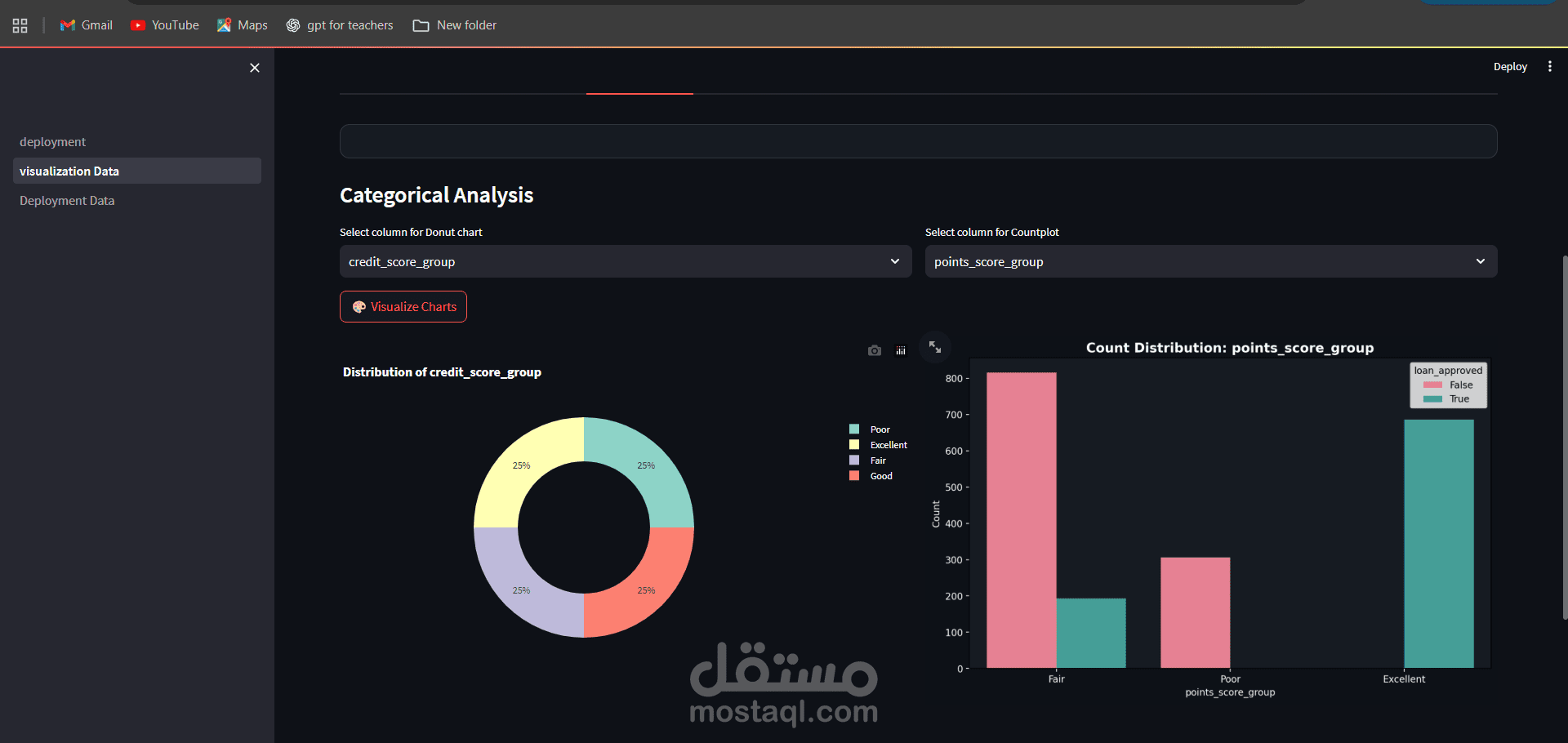
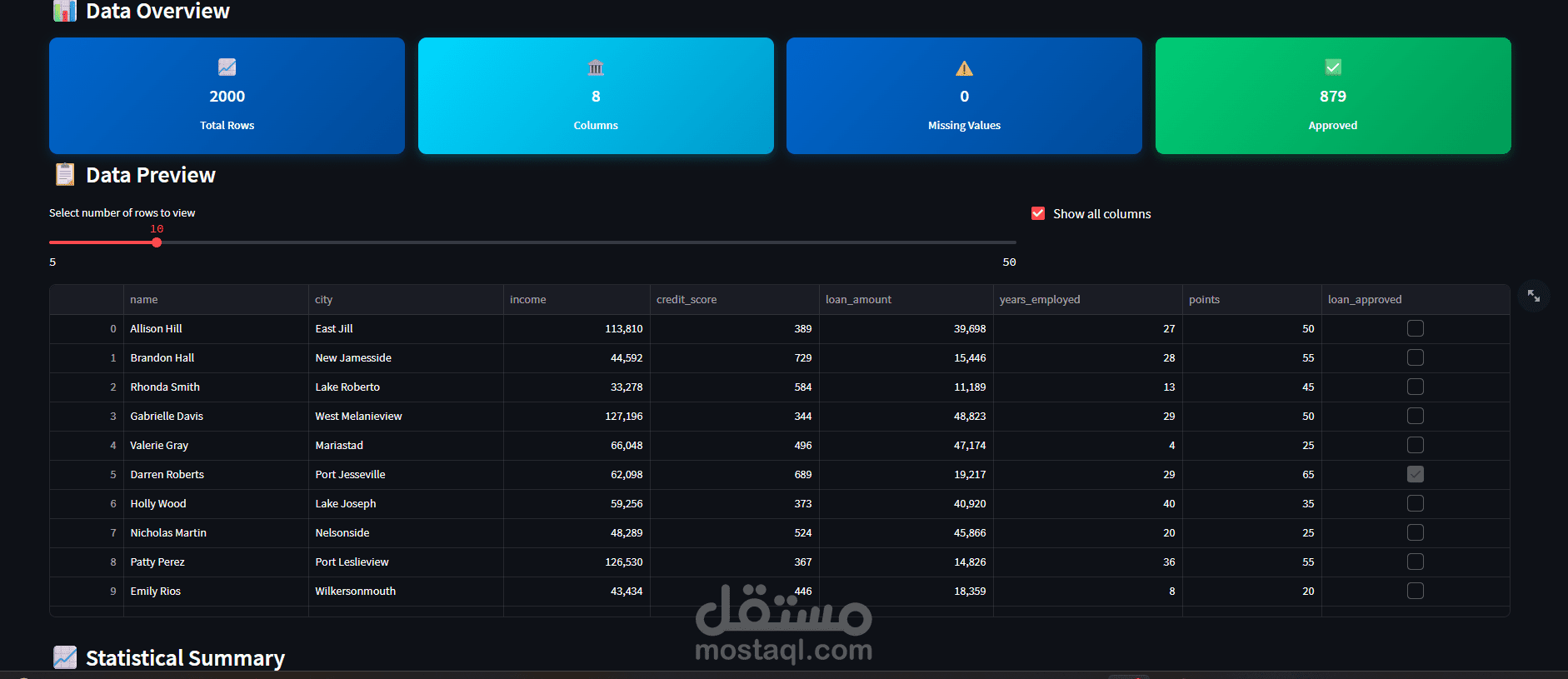
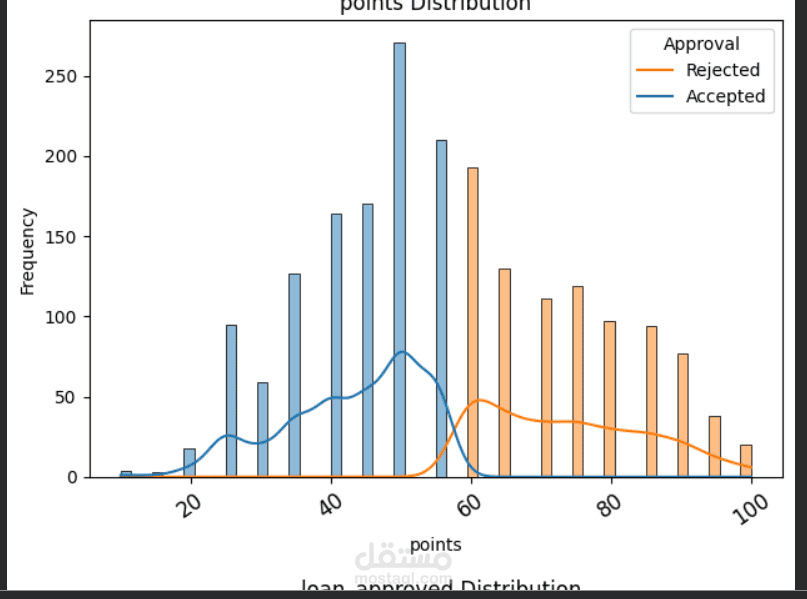
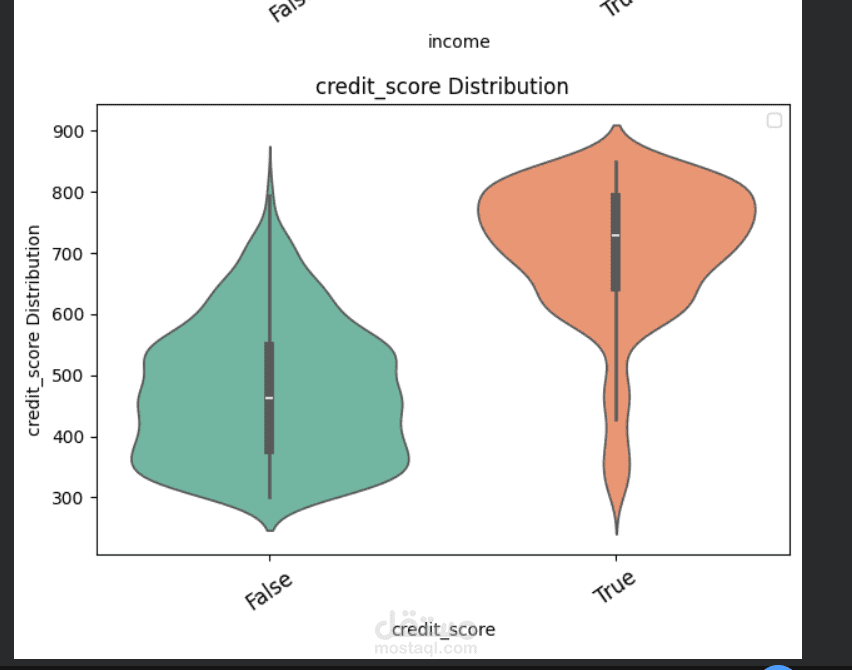
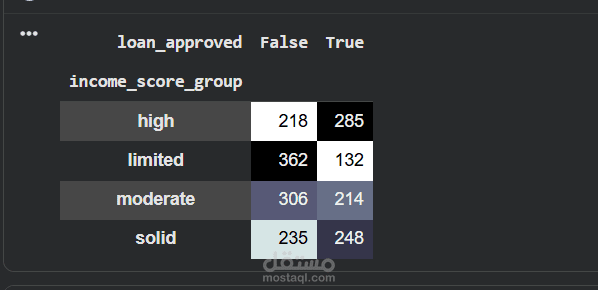
يهدف هذا المشروع إلى تطوير نموذج تعلم آلى قادر على التنبؤ باحتمالية قبول أو رفض طلب القرض بناءً على بيانات العملاء مثل الدخل، الحالة الوظيفية، التاريخ الائتمانى، والخصائص المالية الأخرى. يساعد هذا النموذج المؤسسات المالية على اتخاذ قرارات أسرع وأكثر دقة، وتقليل المخاطر المرتبطة بمنح القروض للعملاء غير المؤهلين.
يركز المشروع على بناء Pipeline متكامل يشمل تحليل البيانات، معالجة القيم المفقودة، هندسة الخصائص، تدريب عدة نماذج تعلم آلى، وتحسين الأداء للوصول إلى أفضل نموذج قادر على التنبؤ بدقة عالية.
ما تم تنفيذه فى المشروع
إجراء تحليل استكشافى شامل للبيانات (EDA) لفهم خصائص العملاء والعوامل المؤثرة على قبول القرض
معالجة البيانات المفقودة والقيم الشاذة لضمان جودة البيانات
تنفيذ Feature Engineering لاستخراج الخصائص الأكثر تأثيراً
تحويل البيانات الفئوية إلى بيانات رقمية باستخدام Encoding
تدريب عدة نماذج تعلم آلى مثل:
Logistic Regression
Random Forest
Gradient Boosting
XGBoost
تحسين أداء النماذج باستخدام Hyperparameter Tuning
تقييم النماذج باستخدام مقاييس مثل:
Accuracy
Precision
Recall
F1-score