bookscraping
تفاصيل العمل
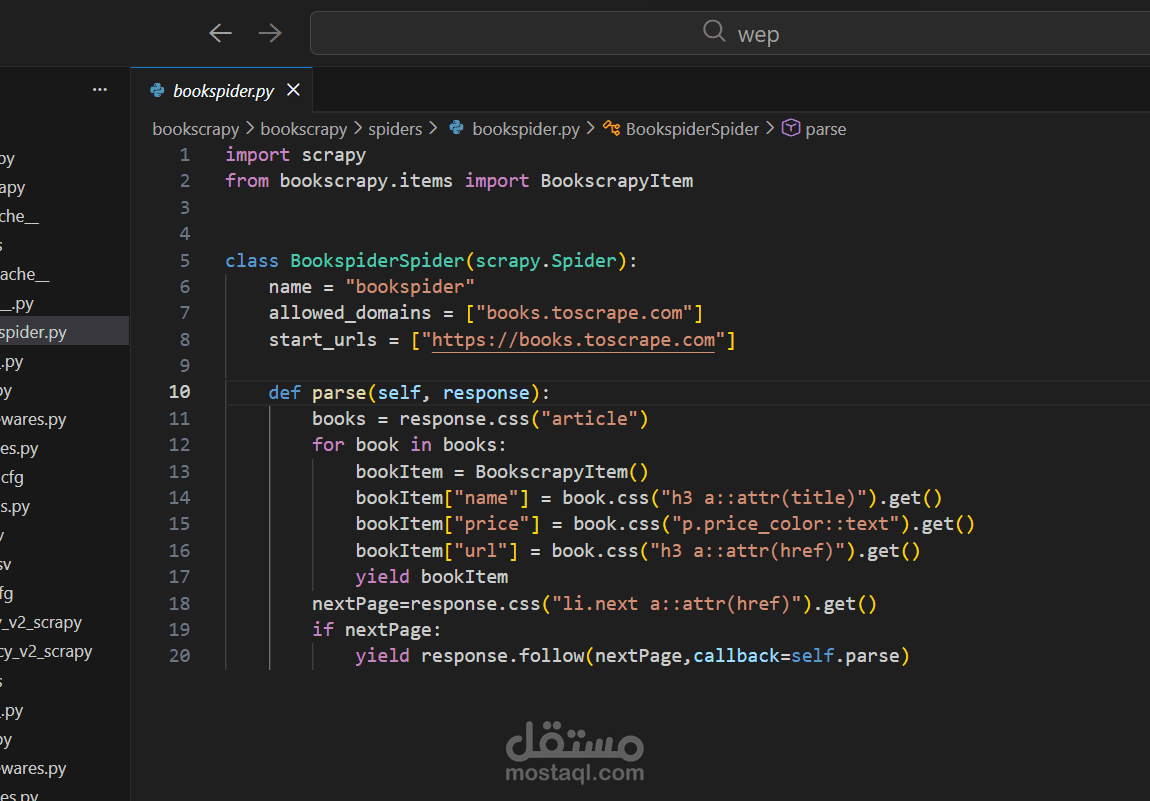
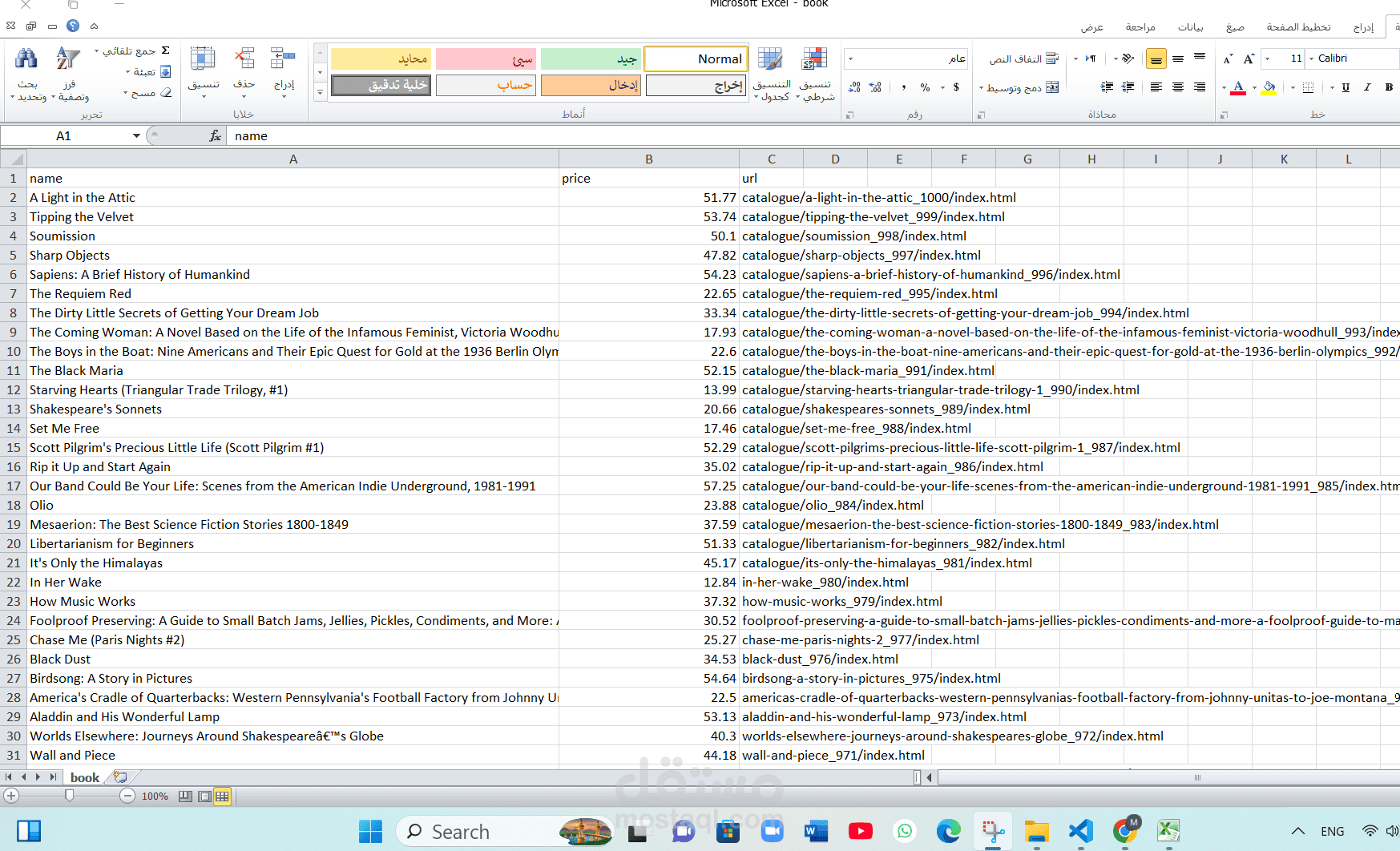
قمت بتطوير نظام متكامل لاستخراج البيانات من منصات الكتب والمكتبات الرقمية الكبرى. يهدف المشروع إلى تجميع قاعدة بيانات شاملة للكتب، تشمل التفاصيل الفنية والأدبية، مع تنظيمها في ملفات مهيكلة (Structured Data) تدعم عمليات تحليل السوق، مقارنة الأسعار، أو بناء تطبيقات المكتبات الرقمية.
البيانات التي يتم استخراجها:
معلومات الكتاب الأساسية: (عنوان الكتاب، اسم المؤلف، دار النشر، سنة النشر).
التصنيف والمحتوى: (النوع الأدبي، وصف ملخص للكتاب، عدد الصفحات).
بيانات التسعير والتقييم: (السعر الحالي، العملة، متوسط تقييم القراء، عدد المراجعات).
المعرفات الدولية: (رقم الـ ISBN، كود الـ SKU).
روابط الوسائط: (رابط صورة الغلاف بجودة عالية، رابط شراء الكتاب).
الميزات التقنية:
تجاوز العقبات: استخدام تقنيات متقدمة للتعامل مع المواقع التي تتطلب تصفحاً عميقاً (Pagination) أو التي تحتوي على حماية ضد البوتات.
السرعة والكفاءة: استخدام إطار عمل Scrapy لضمان سحب آلاف العناوين في دقائق معدودة مع الحفاظ على استقرار العملية.
معالجة النصوص: استخدام مكتبات Python لتنظيف النصوص المستخرجة من الرموز الغريبة وتنسيقها بشكل لائق للقراءة.
تعدد الصيغ: إمكانية تصدير البيانات النهائية بصيغ متعددة مثل (Excel, CSV, JSON, SQL) لتناسب احتياجات أي نظام برمجي.
الأدوات المستخدمة:
Language: Python.
Framework: Scrapy / BeautifulSoup (حسب طبيعة الموقع).
Automation: Selenium (في حال وجود محتوى تفاعلي أو جافا سكريبت معقد).
Data Handling: Pandas (لتنظيف وفلترة قوائم الكتب).
القيمة المضافة للمشروع:
يساعد هذا النظام أصحاب دور النشر، الباحثين، وأصحاب المتاجر الإلكترونية في تجميع محتوى ضخم لمواقعهم في وقت قياسي، بدلاً من إدخال البيانات يدوياً، مما يضمن دقة البيانات وتوفير آلاف الساعات من العمل البشري.