Data analysis for literature books
تفاصيل العمل
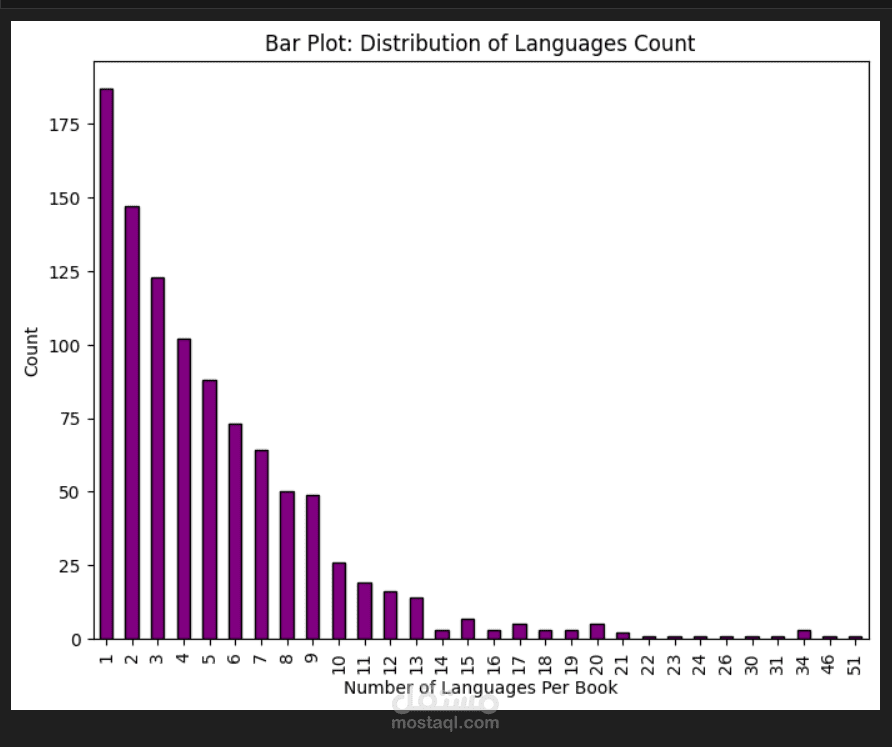
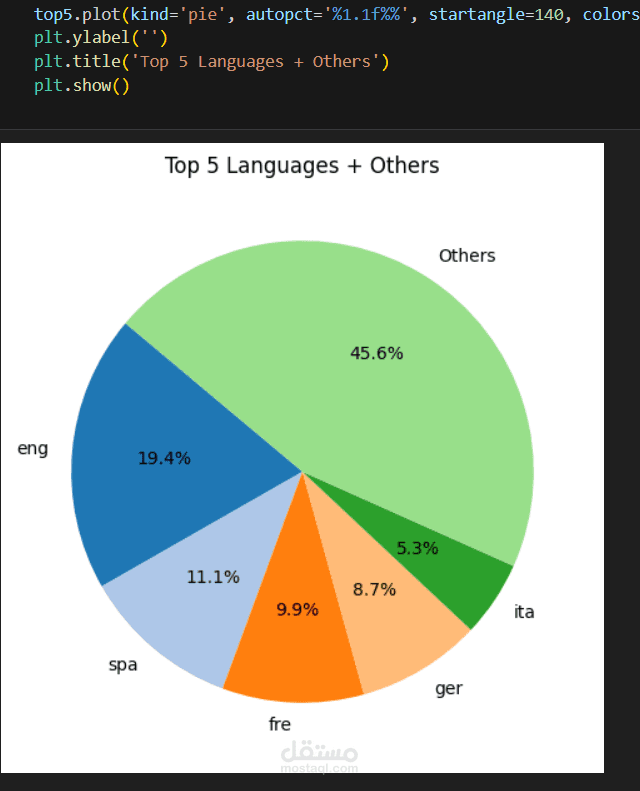
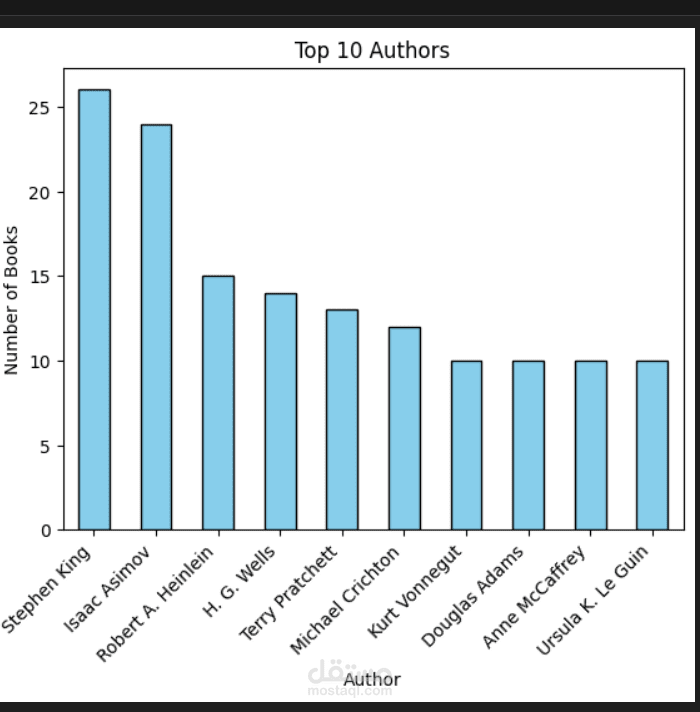
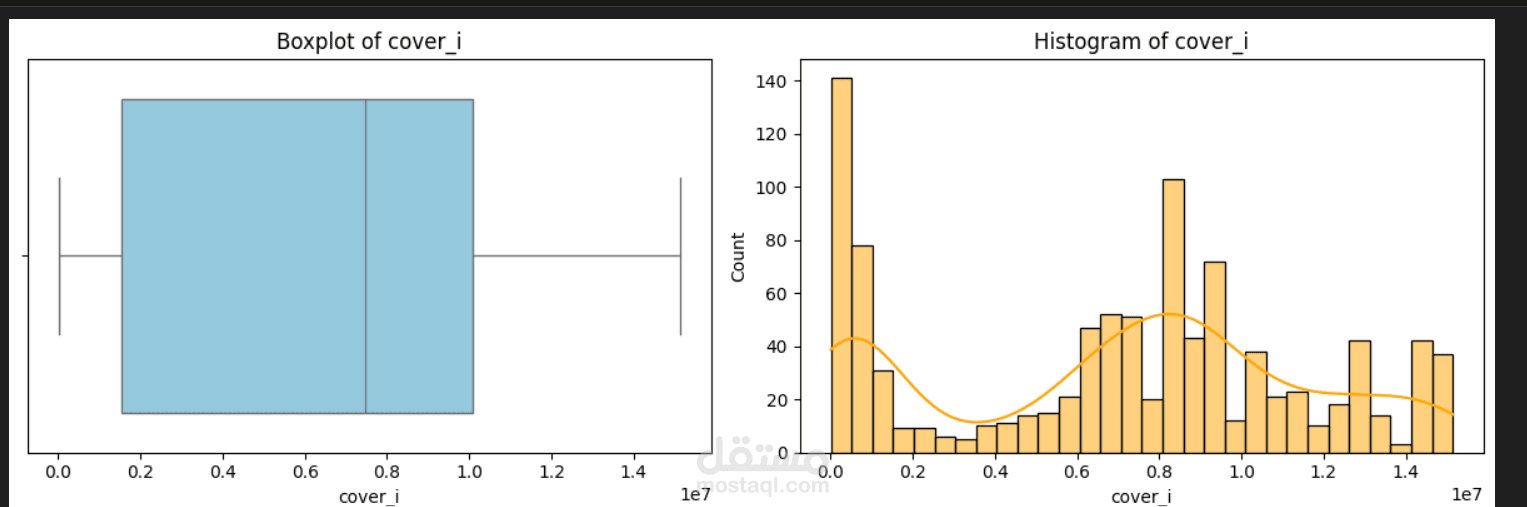

قمت بتنفيذ مشروع لاستخراج وتحليل بيانات 1000 كتاب علمي من خلال واجهة برمجة التطبيقات الخاصة بموقع Open Library باستخدام Python.
يهدف المشروع إلى جمع بيانات الكتب ومعالجتها وتحليلها لاستخراج رؤى مفيدة حول النشر، المؤلفين، وعدد الطبعات.
المشكلة
الحاجة إلى مصدر منظم لبيانات الكتب العلمية يمكن استخدامه في التحليل الإحصائي ودراسة أنماط النشر، مع تحويل البيانات الخام إلى صيغة قابلة للتحليل.
الحل الذي قدمته
استخدام مكتبة requests لعمل Web Scraping عبر API
جمع 1000 كتاب باستخدام Pagination
تحويل البيانات إلى DataFrame باستخدام pandas
تنظيف البيانات ومعالجة القيم الناقصة
إجراء تحليل استكشافي للبيانات (EDA)
استخراج إحصائيات مثل:
عدد الطبعات
سنة أول نشر
اللغات المتاحة
تصدير البيانات إلى ملف CSV جاهز للاستخدام
التقنيات المستخدمة
Python
Pandas
NumPy
Matplotlib
Seaborn
REST API
النتائج
إنشاء قاعدة بيانات تحتوي على 1000 كتاب علمي
تحليل إحصائي شامل للبيانات الرقمية
تجهيز ملف CSV قابل للاستخدام في أي نظام تحليل بيانات
عرض البيانات بصريًا باستخدام الرسوم البيانية