Reinforcement-Learning
تفاصيل العمل
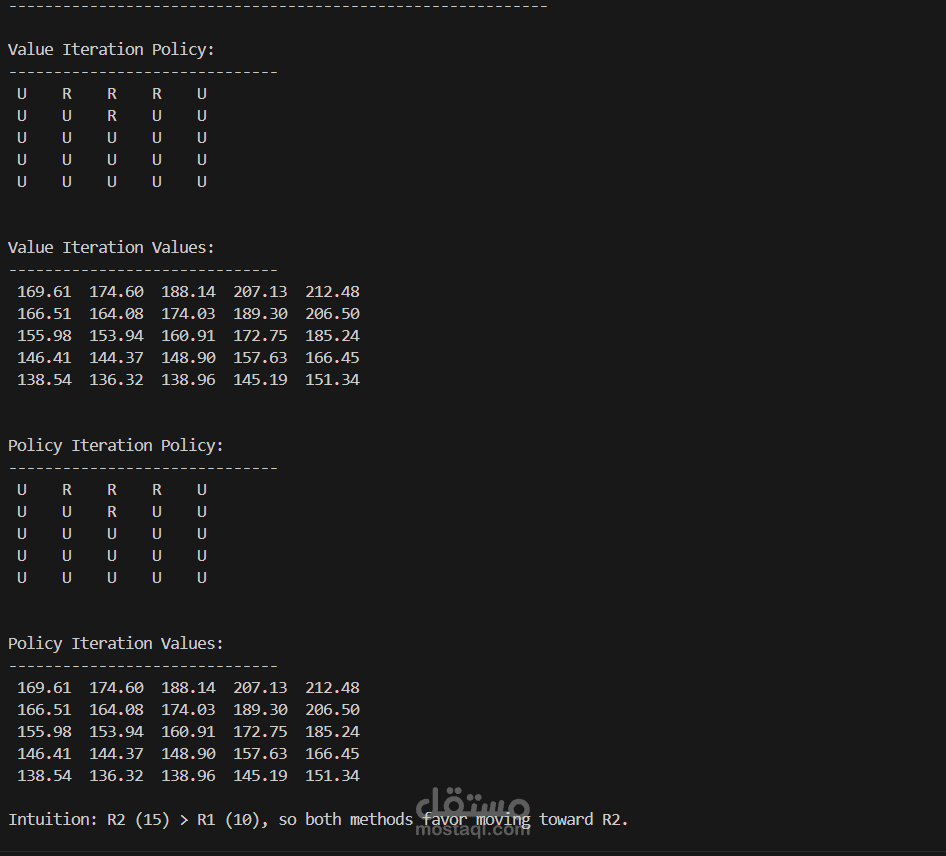
مشروع يطبق مفاهيم التعلم المعزز (Reinforcement Learning) لحل بيئة شبكية (Grid World) باستخدام خوارزميتي Value Iteration و Policy Iteration من إطار Markov Decision Processes (MDP).
يقوم النظام بحساب:
دوال القيم (Value Functions) لكل حالة
السياسات المثلى (Optimal Policies)
اتجاه الحركة الأمثل لكل خلية في البيئة
ويعرض النتائج في صورة:
مصفوفات قيم عددية لكل حالة
مصفوفات سياسات توضح أفضل حركة (U, D, L, R)
مقارنة بين نتائج Value Iteration و Policy Iteration
تحليل سلوكي لقرارات الوكيل (Agent Behavior)
أهداف المشروع:
فهم عملي لمفاهيم MDP
تطبيق خوارزميات RL الكلاسيكية
المقارنة بين خوارزميات التخطيط (Planning Algorithms)
تحليل السياسات واتجاهات القرار
بناء نموذج لاتخاذ القرار الأمثل (Optimal Decision Making)
المفاهيم والتقنيات المستخدمة:
Reinforcement Learning (RL)
Markov Decision Process (MDP)
Value Iteration Algorithm
Policy Iteration Algorithm
State Space Representation
Reward Modeling
Agent-Environment Interaction
Decision Making Systems