Loan Approval Prediction
تفاصيل العمل
مشروع تعلم آلي يهدف إلى التنبؤ بما إذا كان طلب القرض سيتم قبوله أو رفضه بناءً على البيانات الديموغرافية للمتقدم، البيانات المالية، والتاريخ الائتماني.
? نظرة عامة
يعتمد المشروع على تحليل أكثر من 45,000 طلب قرض وبناء نماذج تصنيف (Classification Models) للتنبؤ بحالة الموافقة. تم تدريب ومقارنة عدة خوارزميات تشمل:
Support Vector Machine (SVM)
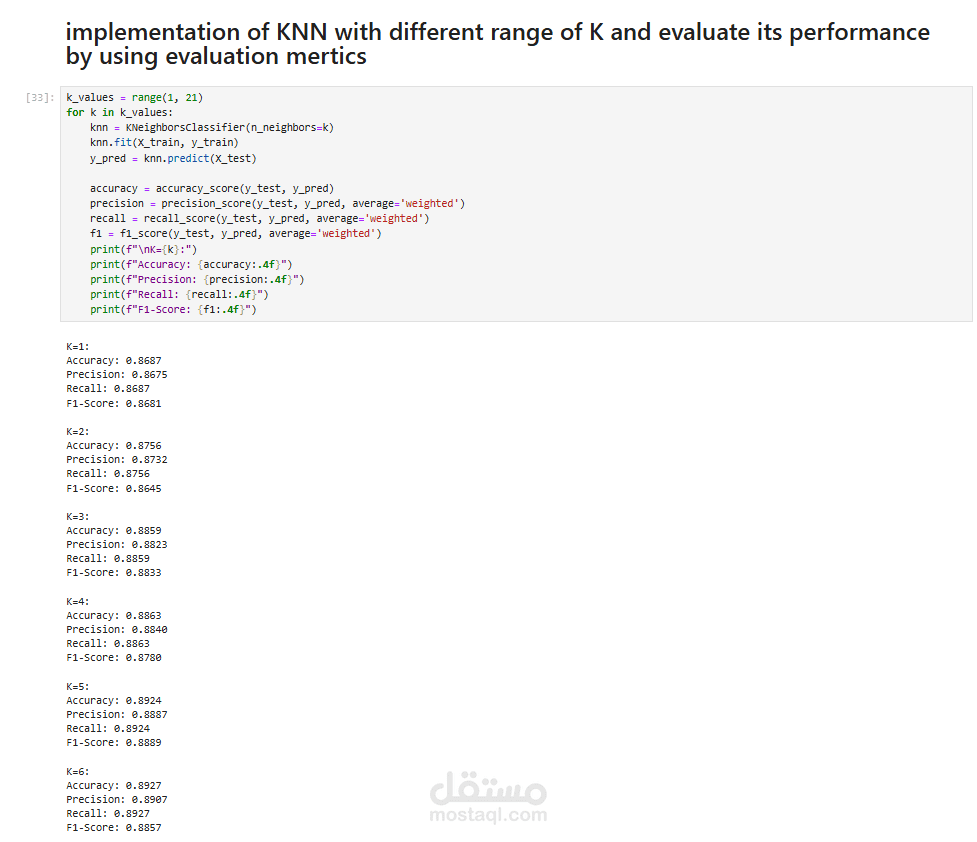
K-Nearest Neighbors (KNN)
Naive Bayes
Decision Tree
وحقق كل من SVM و Decision Tree أفضل أداء بدقة وصلت إلى 92%.
? سير العمل (Workflow)
1️⃣ استكشاف البيانات (Data Exploration):
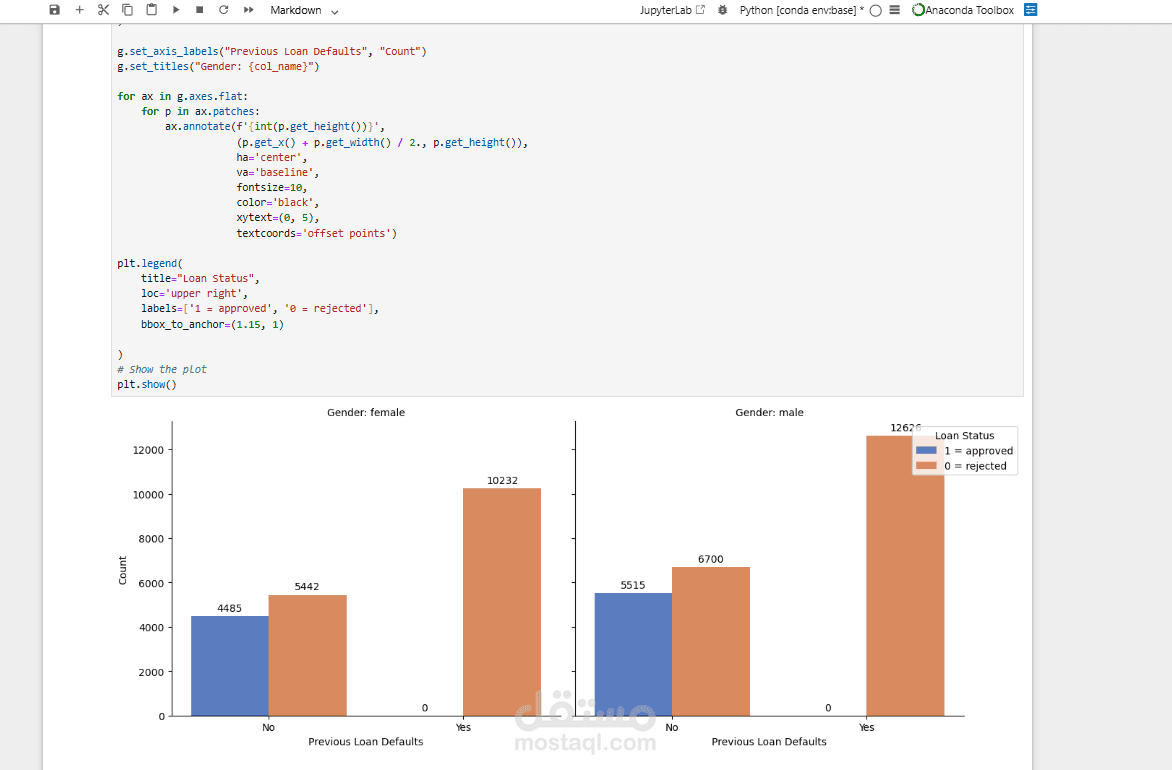
تحليل وتصور توزيع الخصائص المختلفة، ودراسة العلاقات والارتباطات بين المتغيرات المؤثرة في قرار الموافقة على القرض.
2️⃣ المعالجة المسبقة (Preprocessing):
معالجة القيم الشاذة (Outliers)
ترميز المتغيرات الفئوية (Encoding)
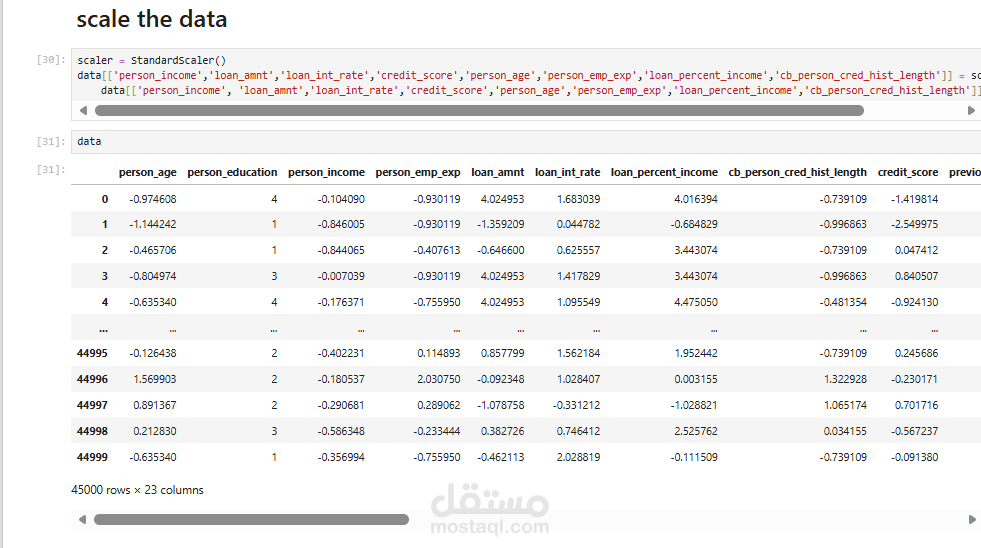
توحيد وتقييس المتغيرات الرقمية (Scaling)
3️⃣ تدريب النماذج (Model Training):
اختبار أربع خوارزميات تصنيف مختلفة مع إجراء ضبط للمعاملات (Hyperparameter Tuning) لتحسين الأداء.
4️⃣ التقييم (Evaluation):
مقارنة أداء النماذج باستخدام مقاييس:
Accuracy
Precision
Recall
F1-Score
? النتائج
أفضل النماذج:
SVM (باستخدام RBF Kernel) و Decision Tree بدقة بلغت 92%.
أهم الخصائص المؤثرة:
الدرجة الائتمانية (Credit Score)
قيمة القرض
دخل المتقدم
حالات التعثر السابقة
?️ التقنيات المستخدمة
Python – pandas – scikit-learn – seaborn – matplotlib – plotly