Loan Default Prediction System | تحليل وتقييم مخاطر الائتمان
تفاصيل العمل

هذا المشروع عبارة عن نظام متكامل يهدف إلى دعم المؤسسات المالية والبنوك في إدارة Credit Risk (المخاطر الائتمانية). يعمل النظام على التنبؤ باحتمالية تعثر المقترضين عن السداد قبل اتخاذ قرار الموافقة على منح القرض، مما يساهم في تقليل الخسائر المالية.
المميزات التقنية (Technical Features)
1. بناء النموذج (Model Building)
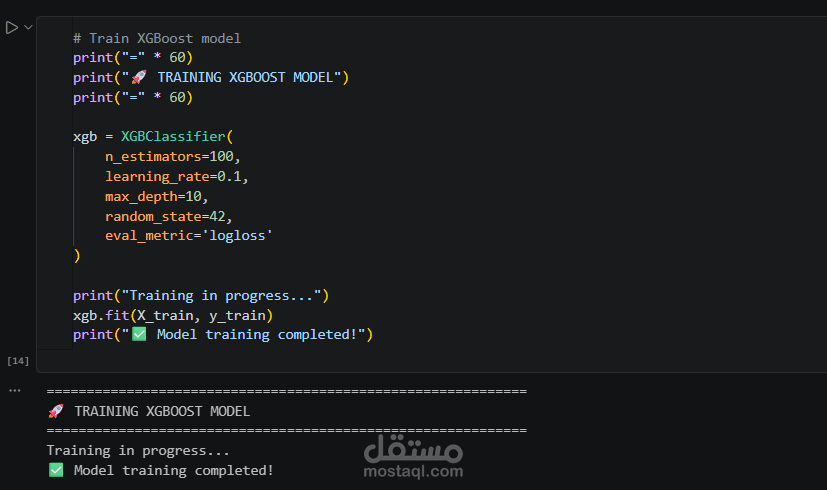
تم استخدام خوارزمية XGBoost Classifier، وهي من أقوى خوارزميات Supervised Learning المعروفة بكفاءتها العالية في التعامل مع البيانات الجدولية.
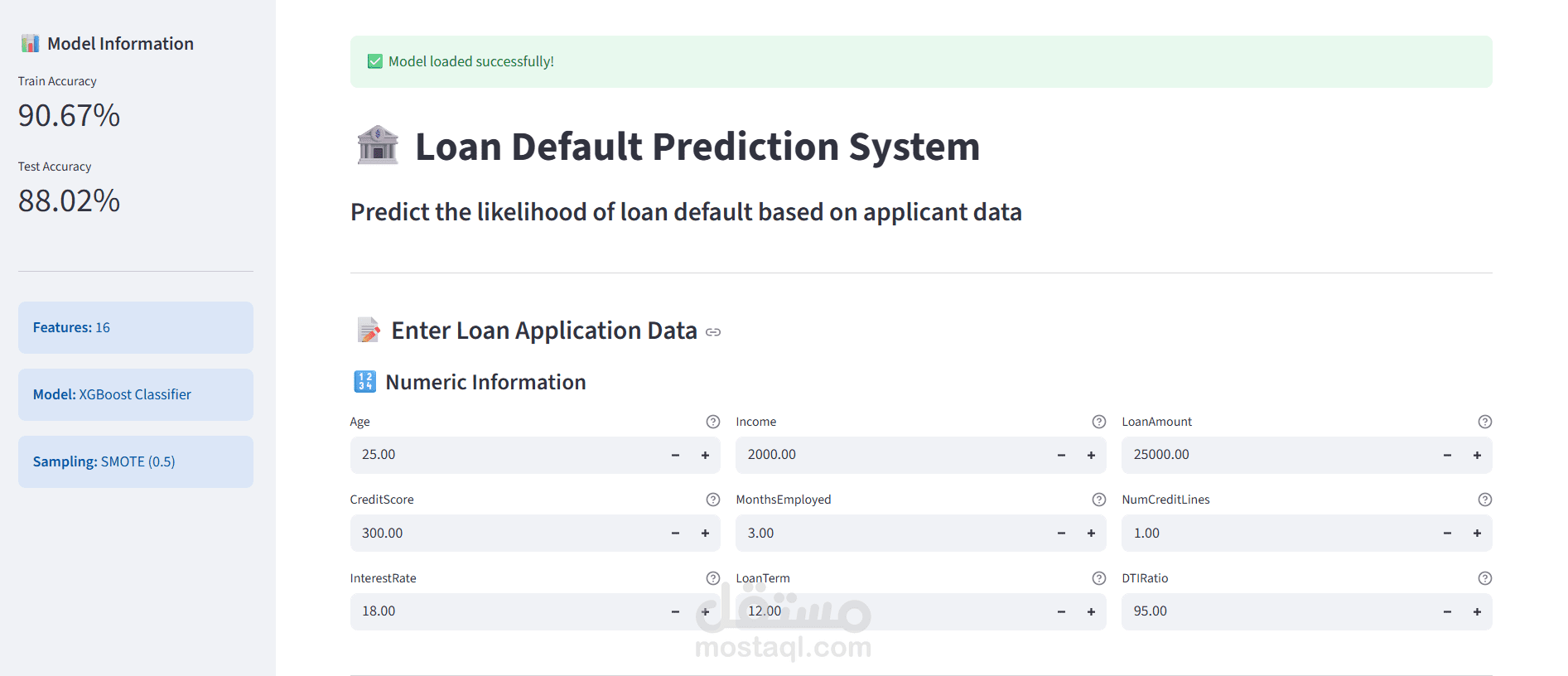
حقق النموذج دقة تصل إلى 88% في عملية الـ Prediction (التوقع).
2. معالجة البيانات (Data Preprocessing)
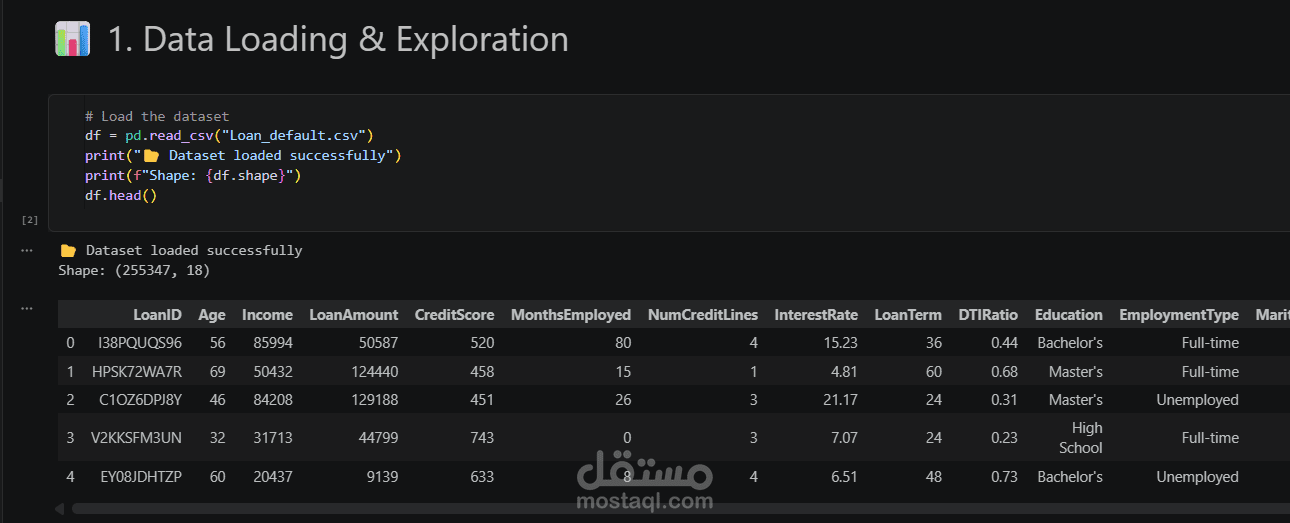
تم إجراء عمليات تنظيف وتجهيز للبيانات لضمان جودة المخرجات.
استخدمنا تقنية Label Encoding لتحويل البيانات الفئوية (Categorical Data) إلى قيم رقمية.
طبقنا Feature Scaling لتوحيد نطاقات القيم المختلفة، مما يضمن عدم انحياز النموذج لمتغير دون الآخر.
3. معالجة عدم توازن البيانات (Imbalance Handling)
لمواجهة مشكلة Data Imbalance (حيث يكون عدد المتعثرين أقل بكثير من الملتزمين بالسداد)، تم استخدام تقنية SMOTE.
تعمل هذه التقنية على توليد عينات اصطناعية للفئة الأقل عدداً (Oversampling) لتحسين قدرة النموذج على التعرف على حالات التعثر.
4. لوحة التحكم التفاعلية (Interactive Dashboard)
تم تطوير واجهة مستخدم احترافية باستخدام إطار عمل Streamlit.
تتيح الواجهة للمحللين الماليين إدخال بيانات العميل مثل Income (الدخل)، و Age (العمر)، و Credit Score، والحصول على نتيجة فورية توضح مستوى المخاطر.
الأدوات والمكتبات المستخدمة (Tech Stack)
Python: لغة البرمجة الأساسية، مع الاعتماد على مكتبات Pandas و NumPy لمعالجة المصفوفات والجداول.
Scikit-learn: لتنفيذ عمليات الـ Preprocessing وتقييم أداء النموذج.
XGBoost: المكتبة المتخصصة في بناء وتدريب النموذج الأساسي.
Streamlit: لعملية الـ Deployment وتحويل النموذج إلى تطبيق ويب تفاعلي.
Pickle: لعملية Model Serialization (حفظ النموذج) لاستخدامه مباشرة في بيئة الإنتاج.
يهدف هذا المشروع إلى تحويل البيانات المعقدة والأرقام المجردة إلى أداة تقنية سهلة الاستخدام، تساهم بفعالية في دعم اتخاذ القرارات المصرفية السليمة.