تطوير موديل تعلم عميق للتعرف على الأرقام المكتوبة يدويًا على طوابع البريد
تفاصيل العمل
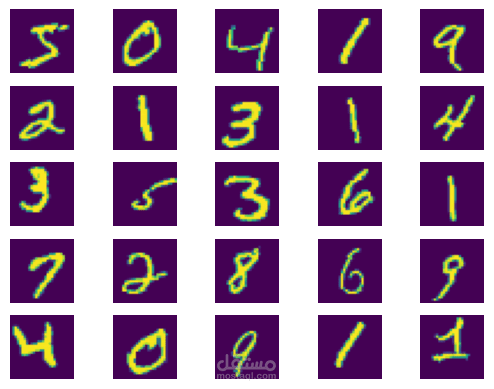
المشكلة:
تصنيف الأرقام المكتوبة بخط اليد (0-9) باستخدام مجموعة بيانات الأرقام البريدية (Postal Digits Dataset).
المجموعة تحتوي على صور بالأبيض والأسود للأرقام المكتوبة يدوياً بأحجام وأنماط كتابة مختلفة. التحدي يكمن في التعامل مع تنوع أساليب الكتابة اليدوية، الضوضاء في الصور، والاختلافات في سُمك وشكل الأرقام، وبناء معمارية CNN قادرة على التعميم بشكل جيد على أرقام جديدة.
المهارات المستخدمة:
Computer Vision: بناء وتدريب Convolutional Neural Networks من الصفر
معماريات CNN:
Convolutional Layers - استخلاص الميزات البصرية من الأرقام المكتوبة يدوياً
MaxPooling Layers - تقليل الأبعاد والحفاظ على الميزات المهمة
Batch Normalization - تسريع التدريب وتحسين الاستقرار
Dropout - منع Overfitting
Flatten و Dense Layers - التصنيف النهائي للأرقام (10 فئات)
Image Preprocessing: Normalization (pixel values 0-1)، Reshaping، معالجة الصور الرمادية
TensorFlow/Keras: بناء نماذج CNN متعددة الطبقات لتصنيف الأرقام
Optimization: Adam optimizer، Sparse Categorical Crossentropy loss
Regularization: Dropout، Early Stopping لتحسين التعميم
Python: Pipeline كامل من تحميل البيانات حتى التقييم والاستنتاج
Model Evaluation: Accuracy، Confusion Matrix، Classification Report لتحليل الأخطاء
النتائج المحققة:
دقة عالية في تصنيف الأرقام المكتوبة يدوياً تتراوح بين 95-98% على بيانات الاختبار.
بناء معمارية CNN فعالة وخفيفة مع 3-5 طبقات Convolutional.
التعامل الناجح مع تنوع أساليب الكتابة اليدوية المختلفة.
معالجة Overfitting عبر Dropout وEarly Stopping.
تحليل الأخطاء باستخدام Confusion Matrix لتحديد الأرقام الأكثر تشابهاً (مثل 4 و 9، أو 3 و 8).
فهم عميق لكيفية عمل Filters في استخلاص ميزات الحواف والمنحنيات من الأرقام.
كود منظم ومُعلق بشكل احترافي مع توثيق كامل.
تحقيق دقة تدريب 98-99% ودقة تحقق 95-98% مع زمن تدريب سريع 5-10 دقائق والنموذج يحتوي على حوالي 100K-300K معامل.