تطوير موديل nlp لوصف الصور عن طريق captions
تفاصيل العمل

المشكلة:
توليد تعليقات نصية تلقائية للصور (Image Captioning) باستخدام التعلم العميق. المشروع يستخدم مجموعة بيانات Flickr8k (1000 صورة للتدريب السريع) مع مقارنة ثلاثة معماريات: RNN، LSTM، و Transformer. التحدي يشمل استخلاص الميزات البصرية من الصور ودمجها مع نماذج متسلسلة لتوليد تعليقات دقيقة وطبيعية.
المهارات المستخدمة:
Computer Vision: ResNet50 (pre-trained) - استخلاص الميزات البصرية من الصور (7×7×2048 features)
معالجة اللغة الطبيعية (NLP): Tokenization، Text Preprocessing، Vocabulary Building (5000 كلمة)
معماريات Deep Learning:
RNN (Simple Recurrent Neural Network)
LSTM مع Dropout للتنظيم
Transformer مع Multi-head Attention و Positional Embeddings
Feature Engineering: إضافة <start> و <end> tokens، تحديد max caption length
TensorFlow/Keras: بناء وتدريب النماذج المعقدة
Optimization: Adam optimizer، Sparse Categorical Crossentropy loss
Python: Pipeline متكامل من تحميل البيانات حتى الاستنتاج
Data Caching: حفظ الميزات المستخرجة في pickle files لتسريع التدريب
Temperature Sampling: تحسين تنوع التعليقات المولدة
النتائج المحققة:
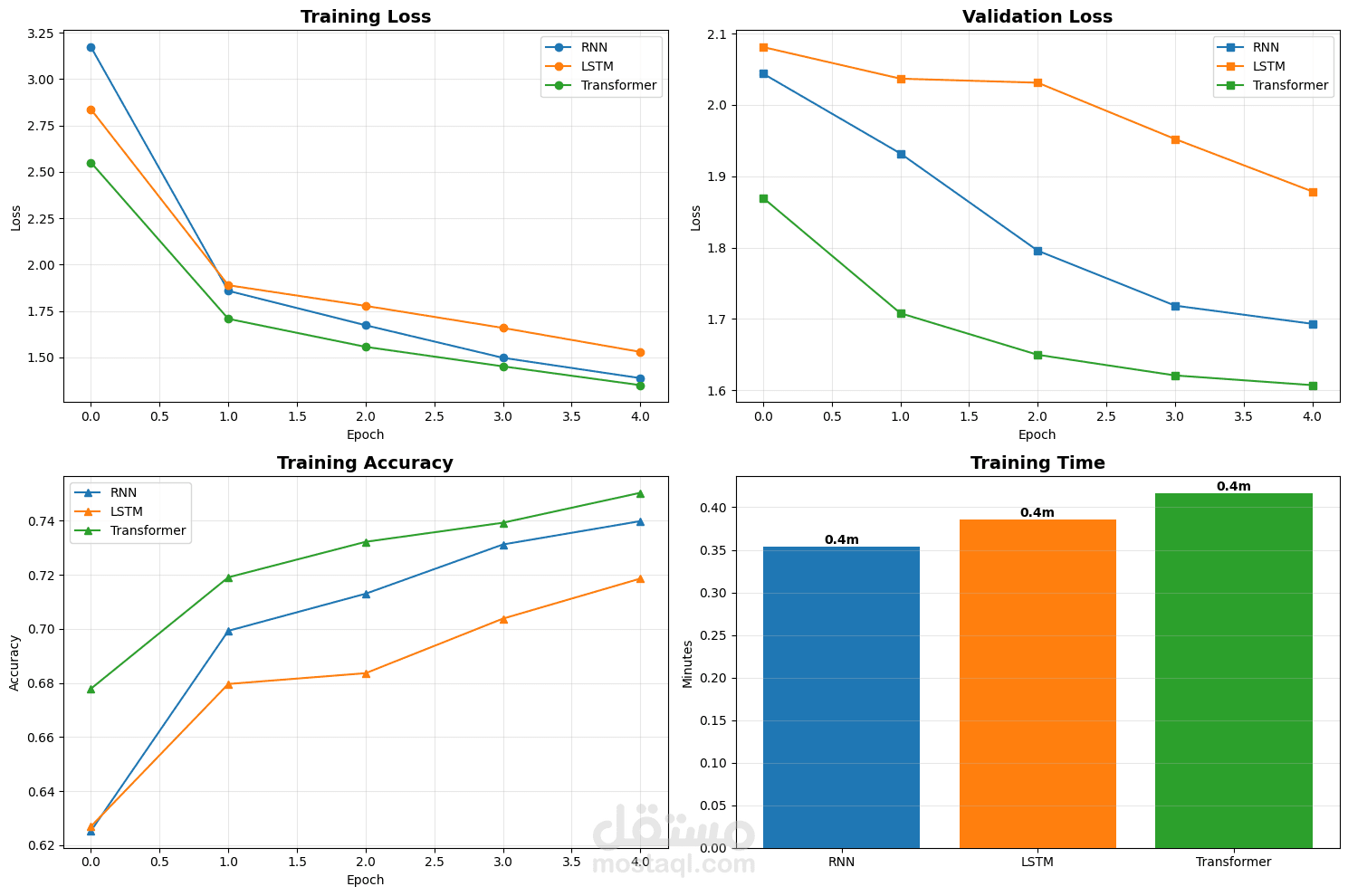
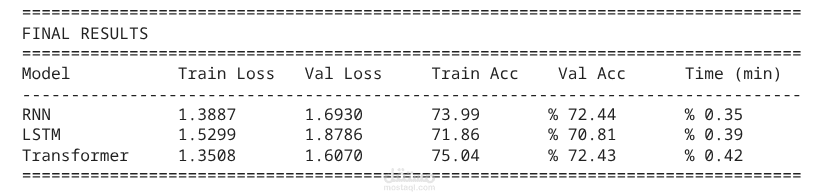
- أفضل أداء للـ Transformer: دقة 75.60% على التدريب و73.11% على التحقق
- تنفيذ ناجح لثلاثة نماذج مختلفة مع مقارنة شاملة
- معالجة فعالة للتحديات: ملفات مفقودة، أوقات تدريب طويلة، Overfitting
- تقليل زمن استخلاص الميزات بشكل كبير عبر الـ Caching
- Pipeline كامل من preprocessing حتى inference
- أقل Validation Loss للـ Transformer (1.5804) مقارنة بـ RNN و LSTM
- أوقات تدريب متقاربة (0.3-0.4 دقيقة) على المجموعة الفرعية