Developing ML Model - تطوير موديل تعلم آلة
تفاصيل العمل
وصف المشروع
المشكلة:
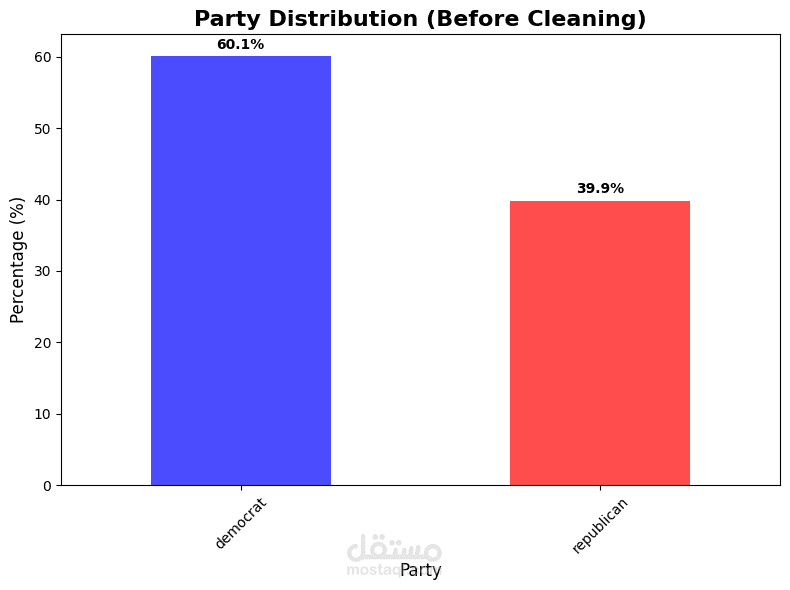
التنبؤ بالانتماء الحزبي (ديمقراطي/جمهوري) لأعضاء الكونجرس الأمريكي بناءً على سجلات تصويتهم على 16 قضية سياسية. البيانات تحتوي على 435 سجل تصويت مع قيم مفقودة وتسميات غير متسقة، مما يتطلب تنظيفاً دقيقاً ومعالجة ذكية.
المهارات المستخدمة:
معالجة البيانات: Pandas، NumPy - تنظيف البيانات، معالجة القيم المفقودة، ترميز البيانات الفئوية
تصور البيانات: Matplotlib، Seaborn - تحليل الأنماط والعلاقات
نماذج Machine Learning:
Logistic Regression
Random Forest
Support Vector Machine (SVM)
XGBoost
تقييم النماذج: Accuracy، Precision، Recall، F1-Score، Cross-Validation
ضبط المعاملات: Hyperparameter Tuning لتحسين الأداء
Python: تنفيذ الخوارزميات وبناء Pipeline كامل
النتائج المحققة:
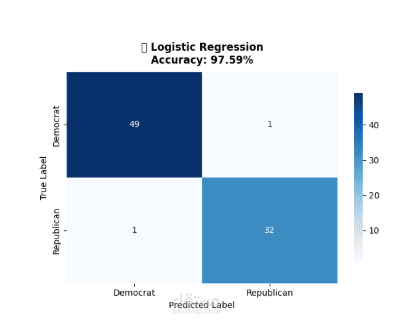
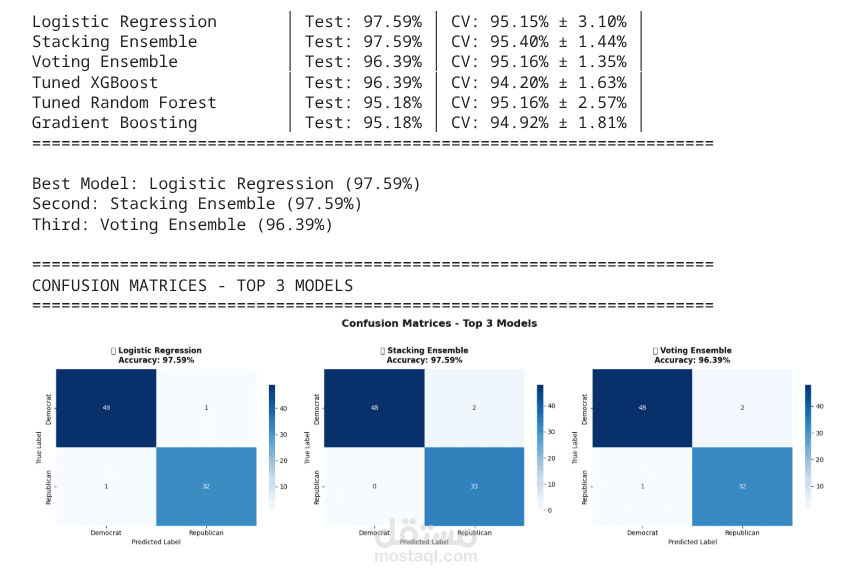
- دقة ممتازة في النموذج الصغير بعد تنظيف فعال للبيانات
- مقارنة شاملة بين 4 نماذج مختلفة
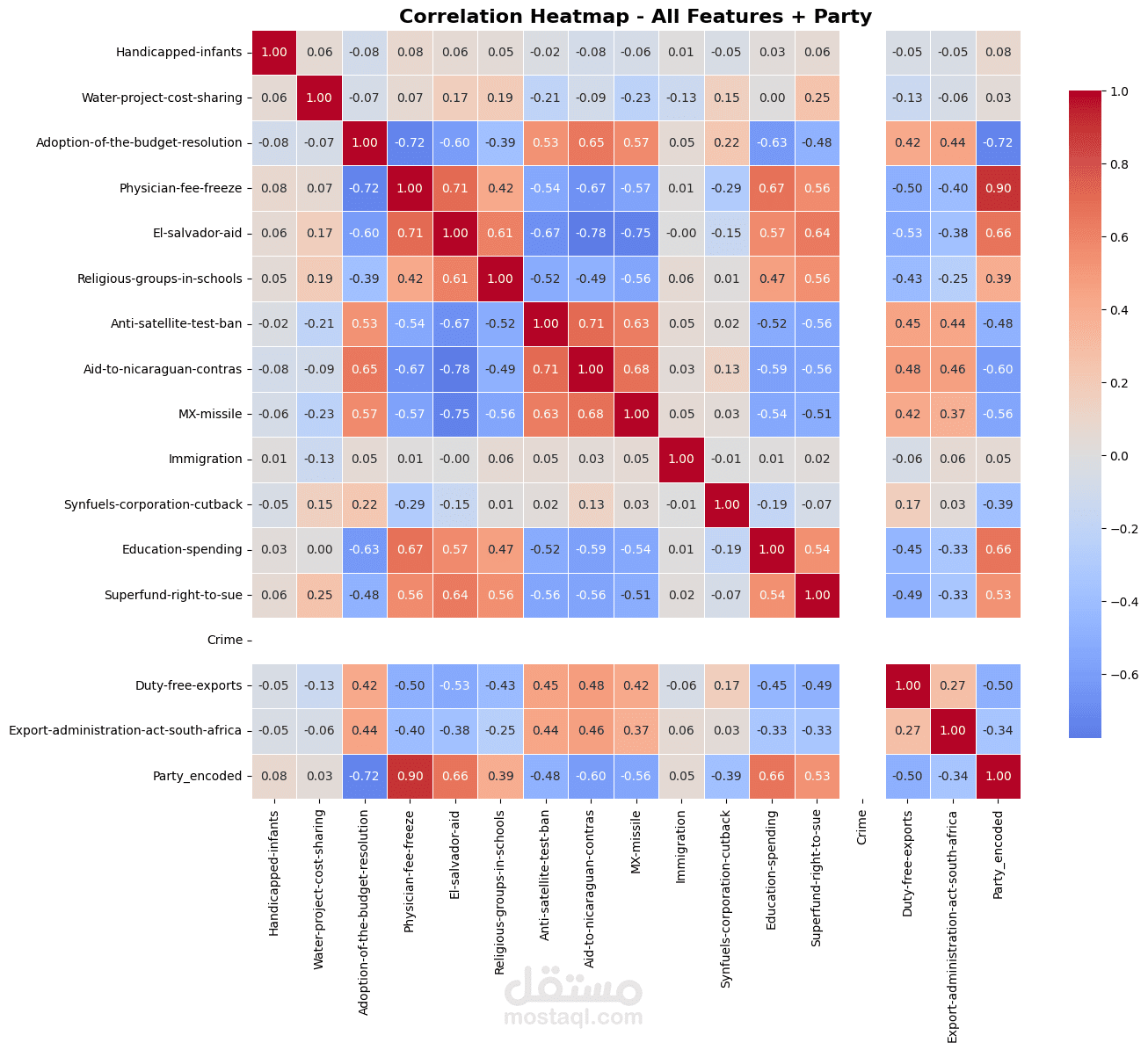
- تحليل الميزات الأكثر تأثيراً في التنبؤ بالانتماء الحزبي
- كود نظيف ومنظم مع توثيق كامل
- تحقيق دقة تنافسية مع تطبيق best practices في Machine Learning