تنفيذ End-to-End Data Engineering Pipeline مع Data Warehouse و Incremental Loading
تفاصيل العمل
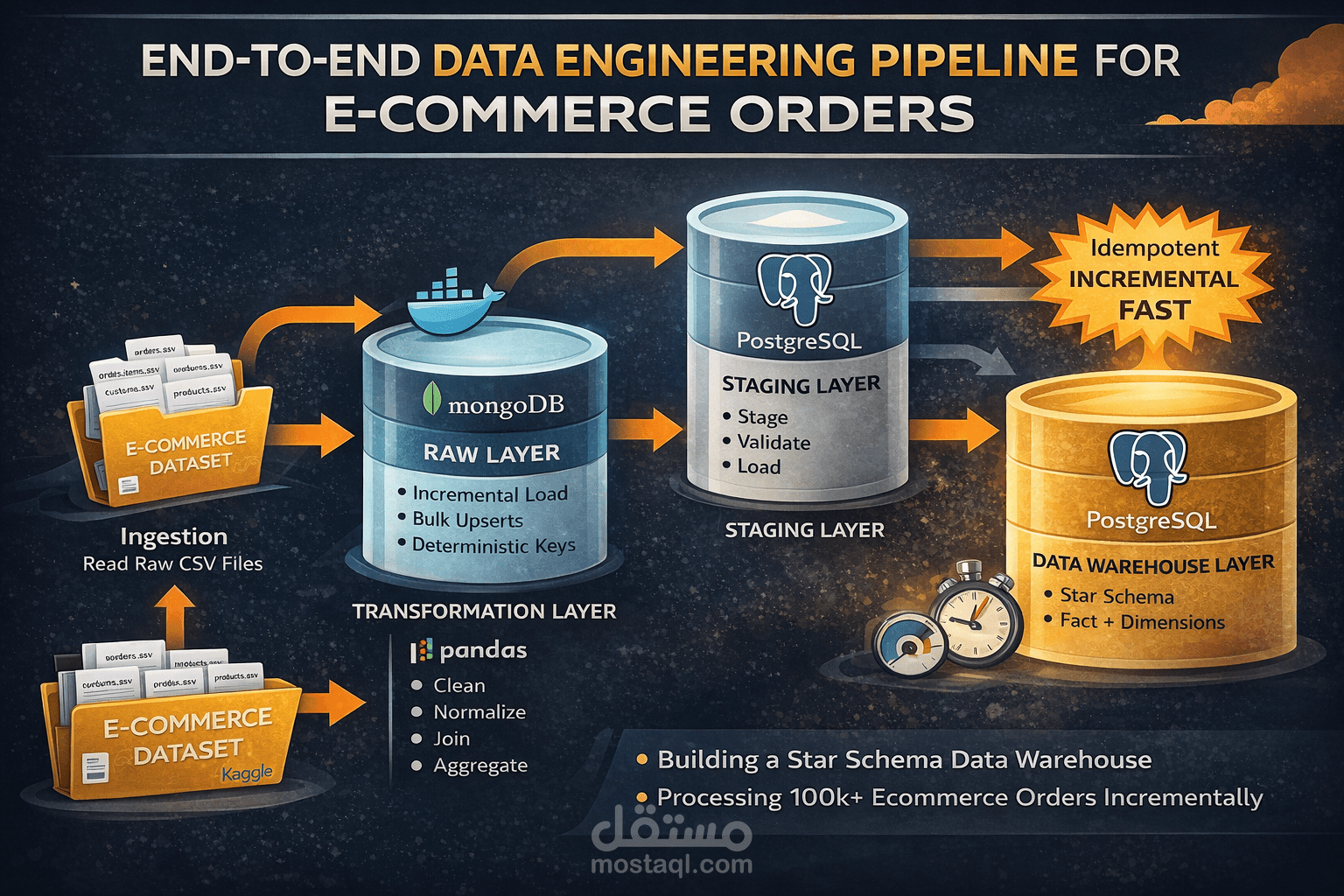

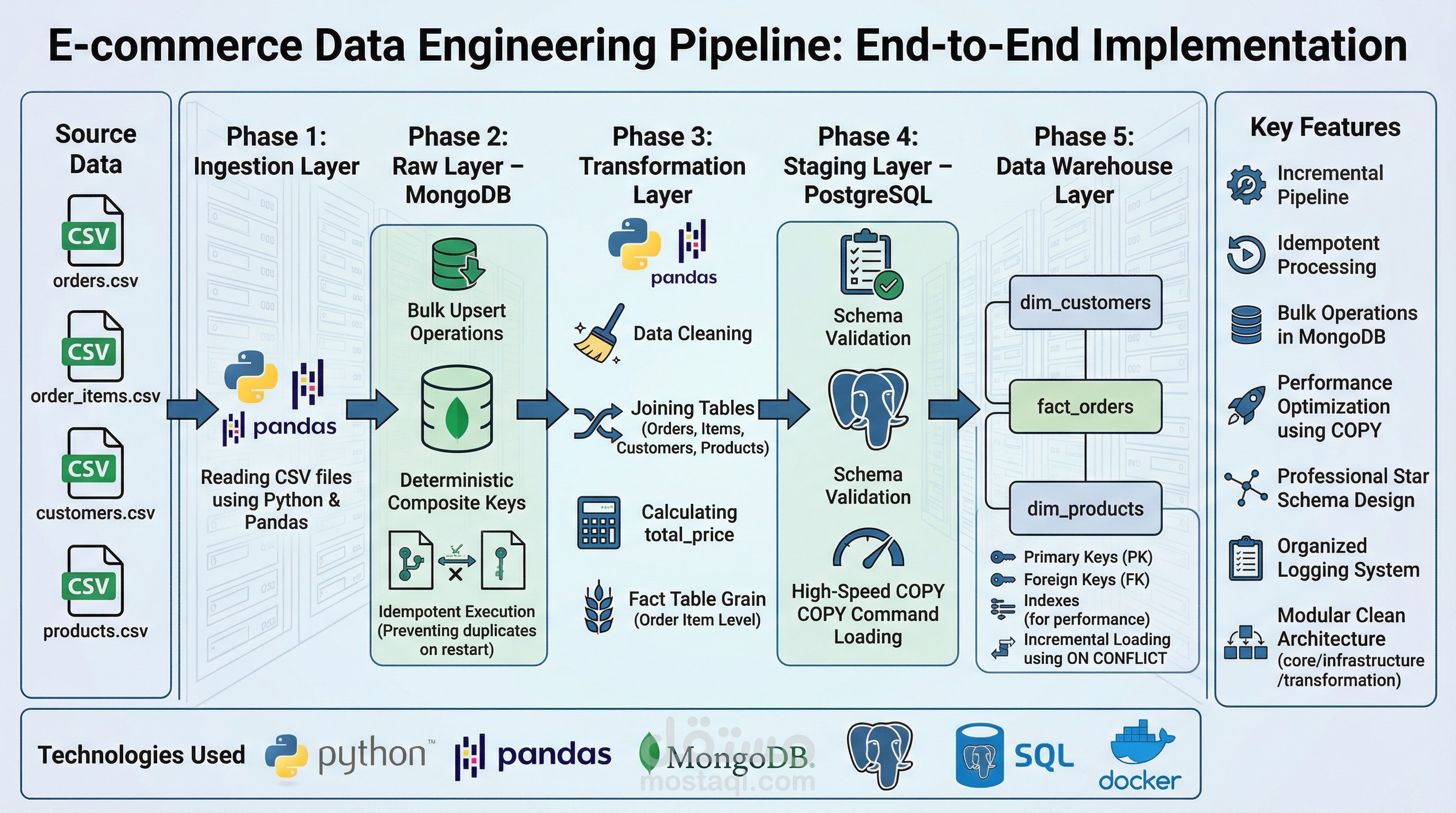
هذا المشروع عبارة عن تنفيذ عملي متكامل لـ Data Engineering Pipeline يعالج بيانات تجارة إلكترونية حقيقية من البداية وحتى بناء Data Warehouse تحليلي جاهز للاستخدام.
الهدف لم يكن كتابة سكريبت بسيط، بل بناء Architecture تشبه بيئة الشركات.
مراحل التنفيذ:
أولاً: Ingestion Layer
تم قراءة ملفات CSV الخاصة بـ orders و order_items و customers و products باستخدام Python و Pandas.
ثانياً: Raw Layer – MongoDB
تم تخزين البيانات الخام داخل MongoDB باستخدام Bulk Upsert بدل insert التقليدي.
تم بناء Deterministic Composite Keys لضمان Idempotent Execution وعدم تكرار البيانات عند إعادة تشغيل الـ pipeline.
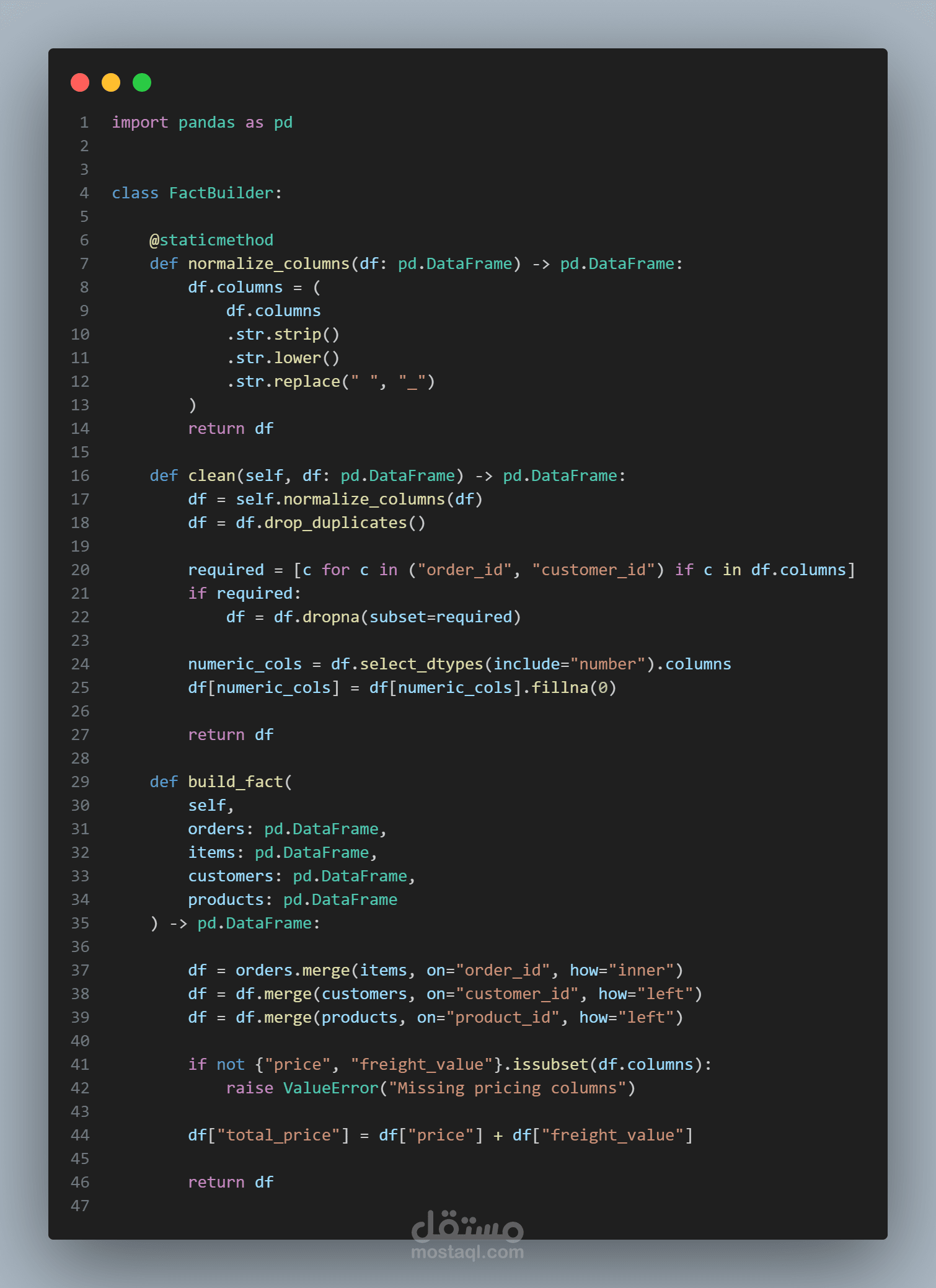
ثالثاً: Transformation Layer
تنظيف البيانات وتوحيد أسماء الأعمدة
إزالة التكرارات
دمج الجداول الأربعة
حساب total_price
معالجة القيم المفقودة
تحديد Grain واضح للـ Fact Table (Order Item Level)
رابعاً: Staging Layer – PostgreSQL
تم استخدام COPY Command لتحميل البيانات بسرعة عالية بدلاً من INSERT التقليدي.
تم تنفيذ Schema Validation قبل التحميل لضمان تطابق الأعمدة.
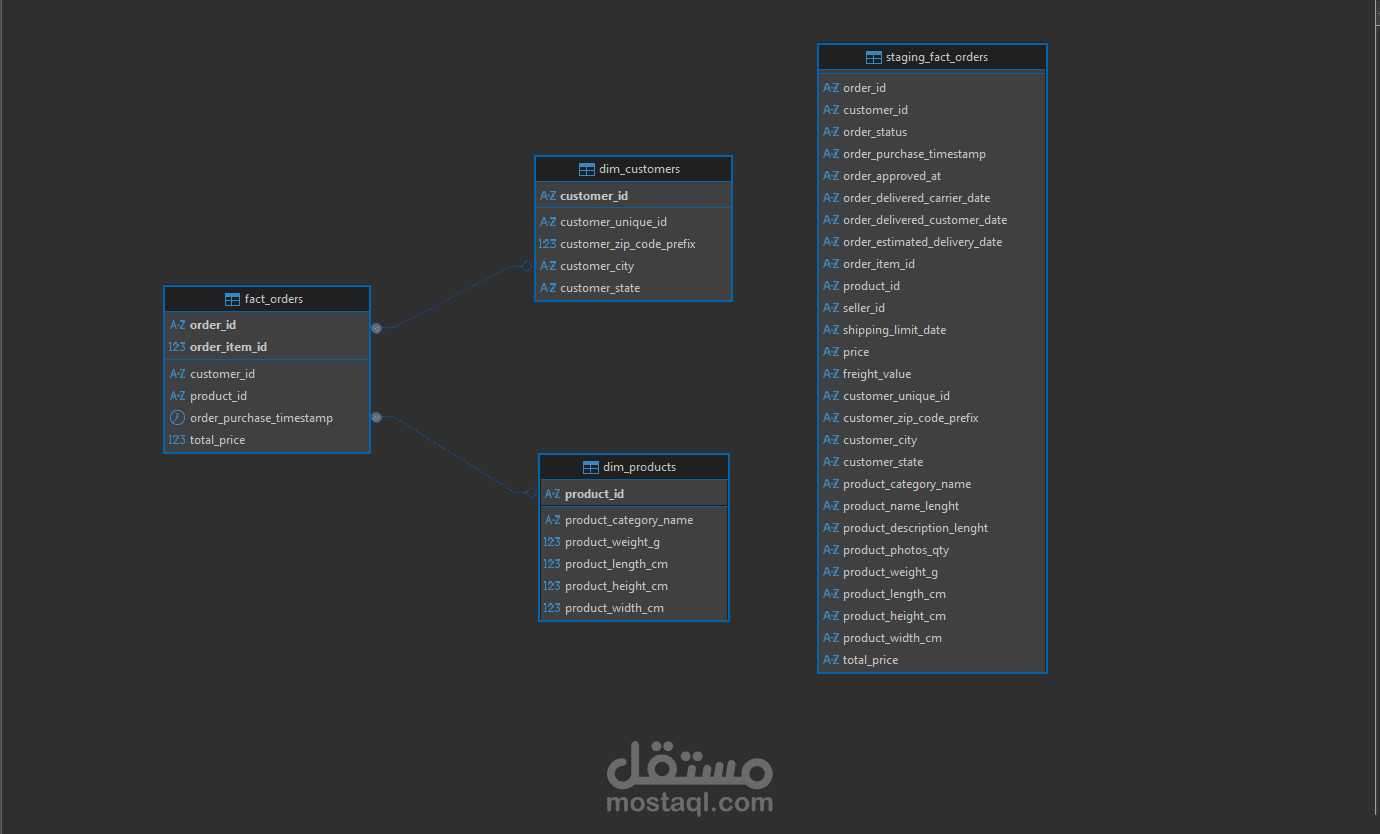
خامساً: Data Warehouse Layer
تم تصميم Star Schema يتكون من:
- fact_orders
- dim_customers
- dim_products
مع تطبيق:
- Primary Keys
- Foreign Keys
- Indexes لتحسين الأداء
- Incremental Loading باستخدام ON CONFLICT
أهم المميزات:
- Incremental Pipeline
- Idempotent Processing
- Bulk Operations في MongoDB
- Performance Optimization باستخدام COPY
- تصميم Star Schema احترافي
- Logging System منظم
- Modular Clean Architecture (core / infrastructure / transformation)
التقنيات المستخدمة:
- Python
- Pandas
- MongoDB
- PostgreSQL
- SQL
- Docker