تطوير ومقارنة نماذج تعلم الآلة للتصنيف والانحدار باستخدام Scikit-learn
تفاصيل العمل

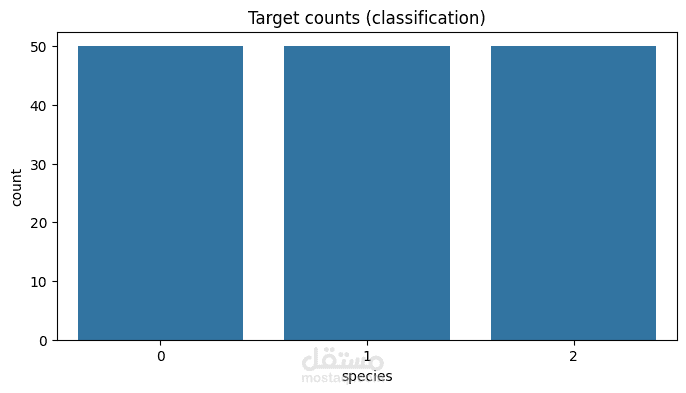
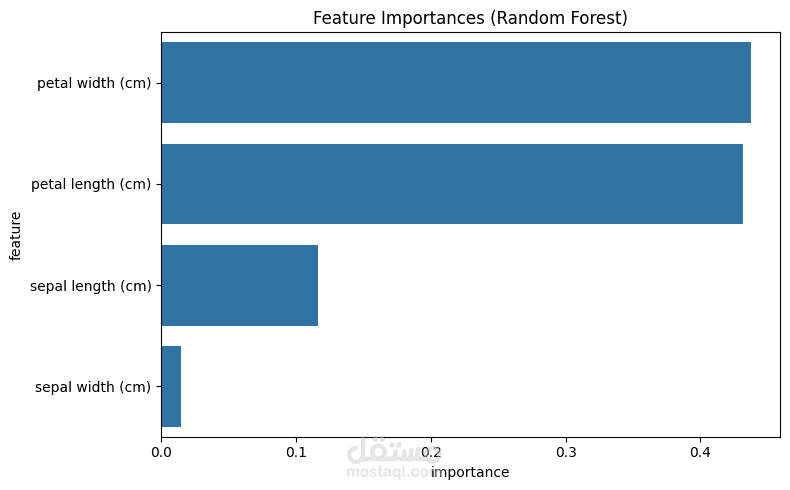
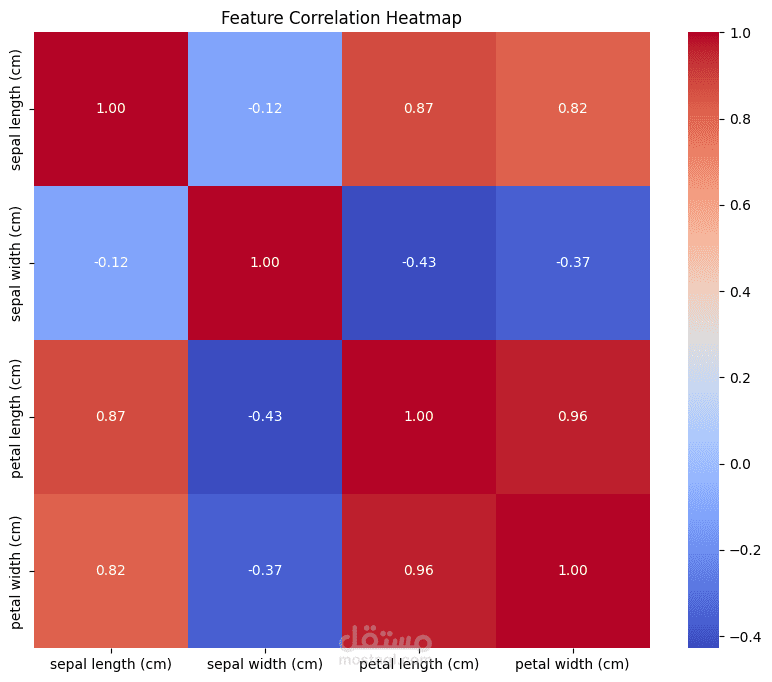
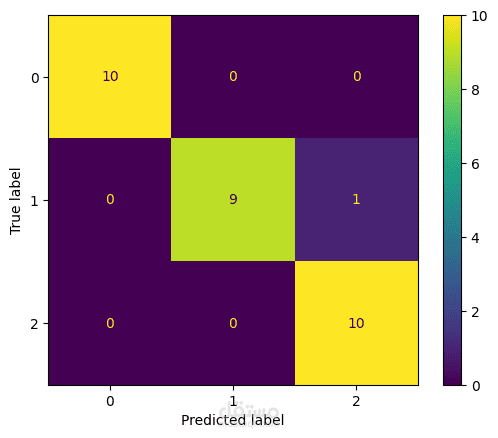

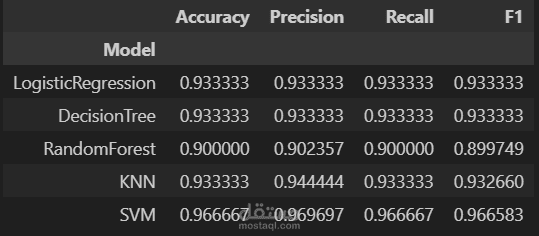
مشروع يهدف إلى بناء وتحليل وتقييم نماذج تعلم الآلة لحل مشكلات التصنيف والانحدار باستخدام مكتبة Scikit-learn في بايثون.
يتضمن المشروع:
تحميل ومعالجة البيانات (مثل Iris أو California Housing).
تنظيف البيانات واكتشاف القيم المفقودة.
تقسيم البيانات إلى تدريب واختبار.
تطبيق Standard Scaling على البيانات.
استكشاف البيانات بصريًا باستخدام Matplotlib وSeaborn.
بناء عدة نماذج تعلم آلة مثل:
Linear Regression
Decision Tree
Random Forest
K-Nearest Neighbors
تحسين أداء النماذج باستخدام GridSearchCV.
تقييم النماذج باستخدام مقاييس مثل:
MSE
MAE
R²
Accuracy (في حالة التصنيف)
يركز المشروع على مقارنة أداء النماذج المختلفة واختيار النموذج الأمثل بناءً على النتائج التحليلية.