VAE-Model
تفاصيل العمل
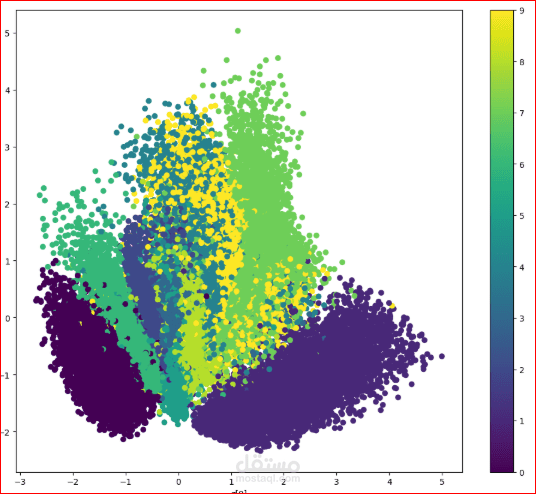
VAE (Variational Autoencoders): These models focus on compressing images
into a compact "Latent Space" and then reconstructing them. They are
mathematically grounded but often produce slightly blurry outputs.