RAG System
تفاصيل العمل
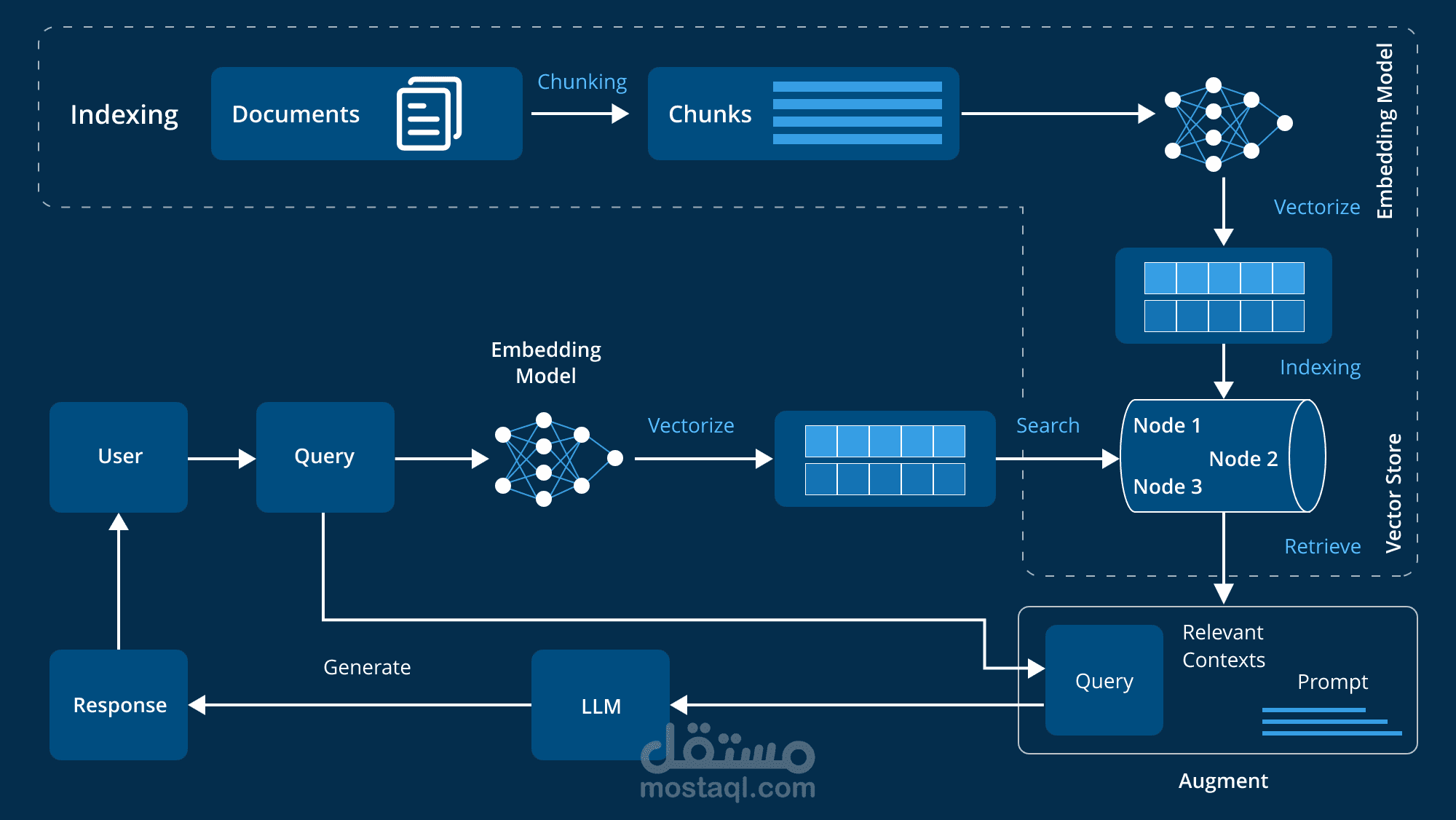
I built a fully functional Retrieval-Augmented Generation (RAG) system to deeply understand how modern AI systems work in real-world production environments.
The system allows users to upload documents, automatically processes them (chunking + embeddings), stores them in a vector database, and retrieves the most relevant context when answering user queries using a language model.
Core Features
Document upload and processing pipeline
Text chunking and embedding generation
Vector similarity search
Context-aware LLM responses
Background task handling
Local model support (Ollama)
Production-ready deployment setup
Technical Stack & Architecture
Backend:
FastAPI for high-performance async APIs
MVC architecture for clean code organization
Background processing using Celery
Local LLM integration via Ollama
Data & Retrieval:
Embeddings generation
Vector database for similarity search
RAG pipeline orchestration
DevOps & Deployment:
*Docker containerization
CI/CD with GitHub Actions
Production-ready deployment workflow
Environment-based configuration