End-to-End ML Pipeline for Data Analysis
تفاصيل العمل
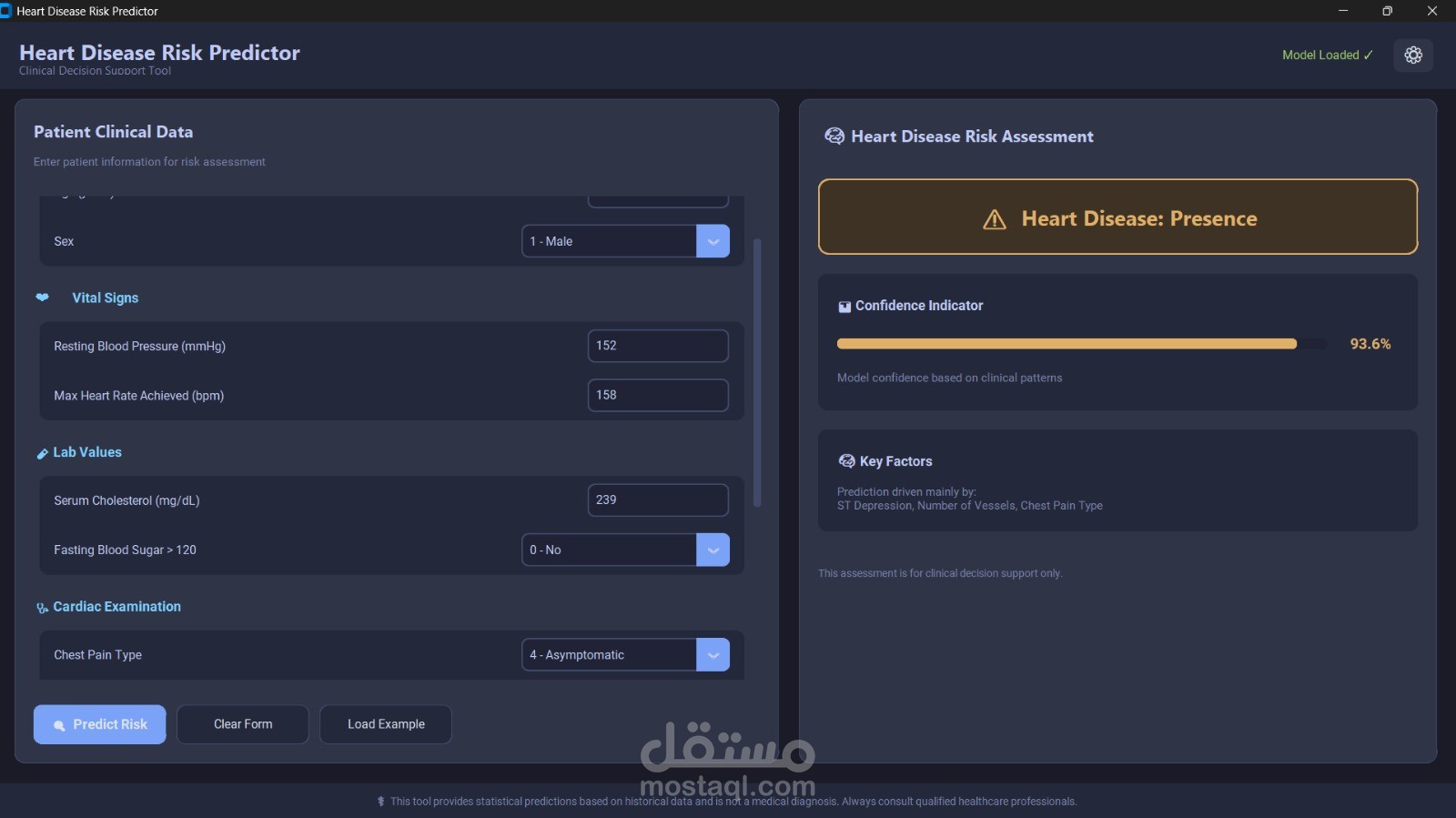
تصميم Pipeline كاملة لتحليل البيانات وبناء نموذج تنبؤي بدءاً من Data Preprocessing وحتى التقييم النهائي.
التقنيات المستخدمة:
Python, Scikit-learn Pipelines, NumPy, Pandas
النتائج:
أتمتة خطوات المعالجة والتدريب
مقارنة عدة موديلات (Logistic Regression, Random Forest)
تحسين الأداء باستخدام Cross Validation