Heart Disease prediction
تفاصيل العمل

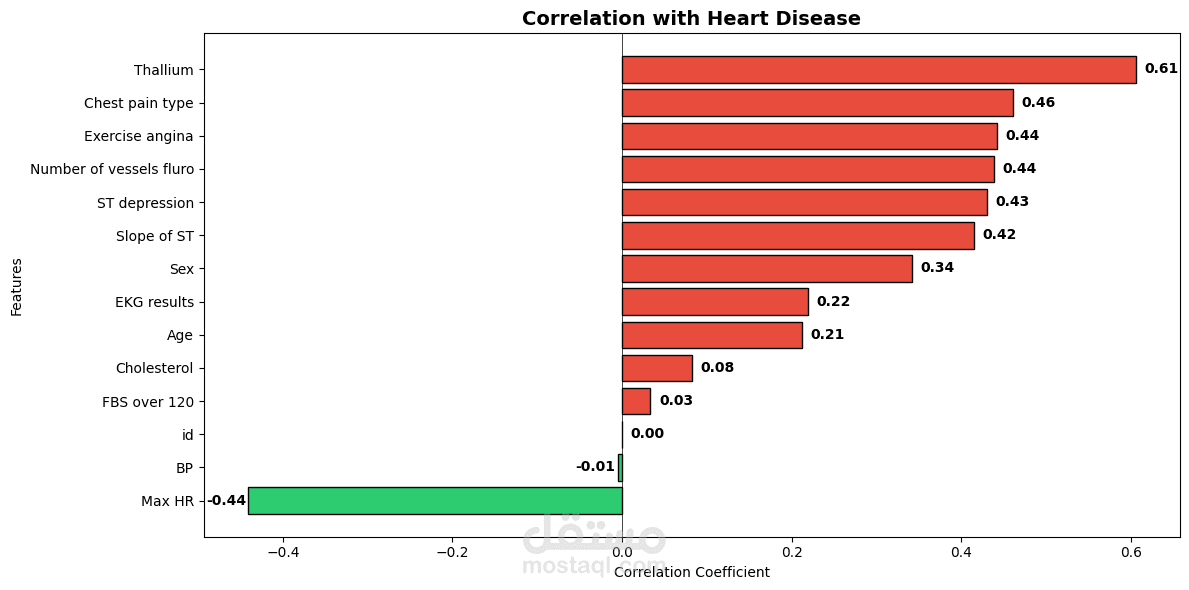
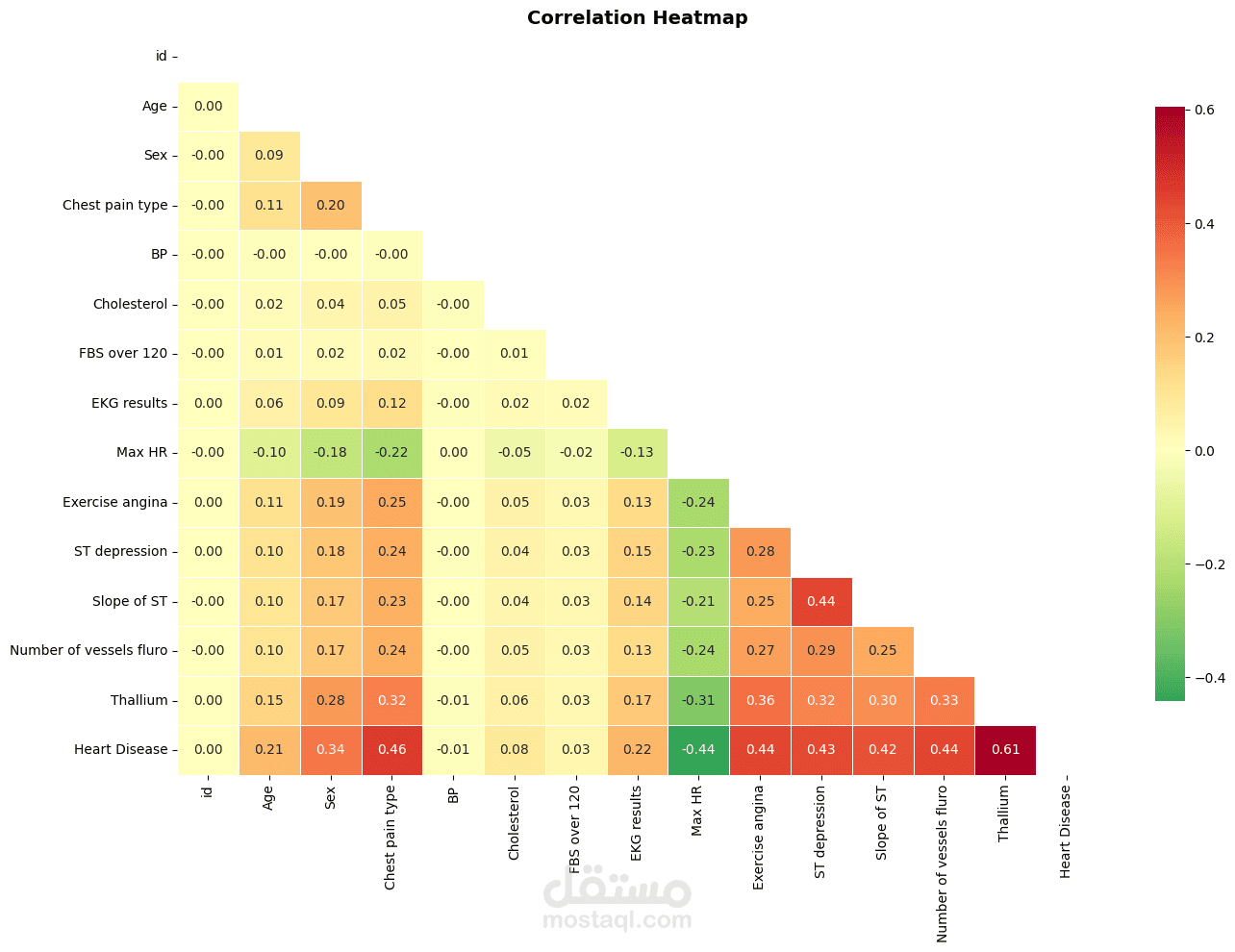
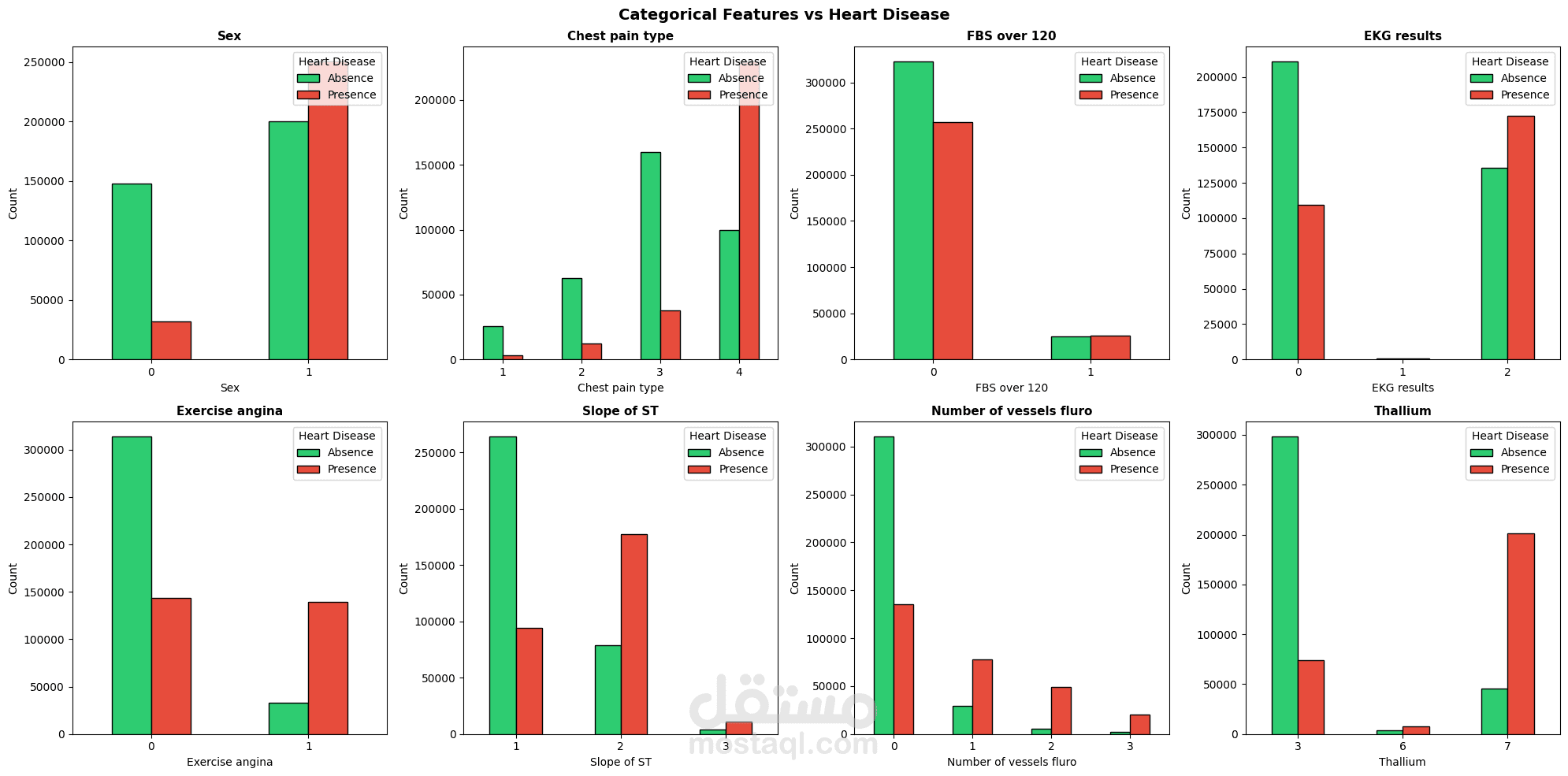
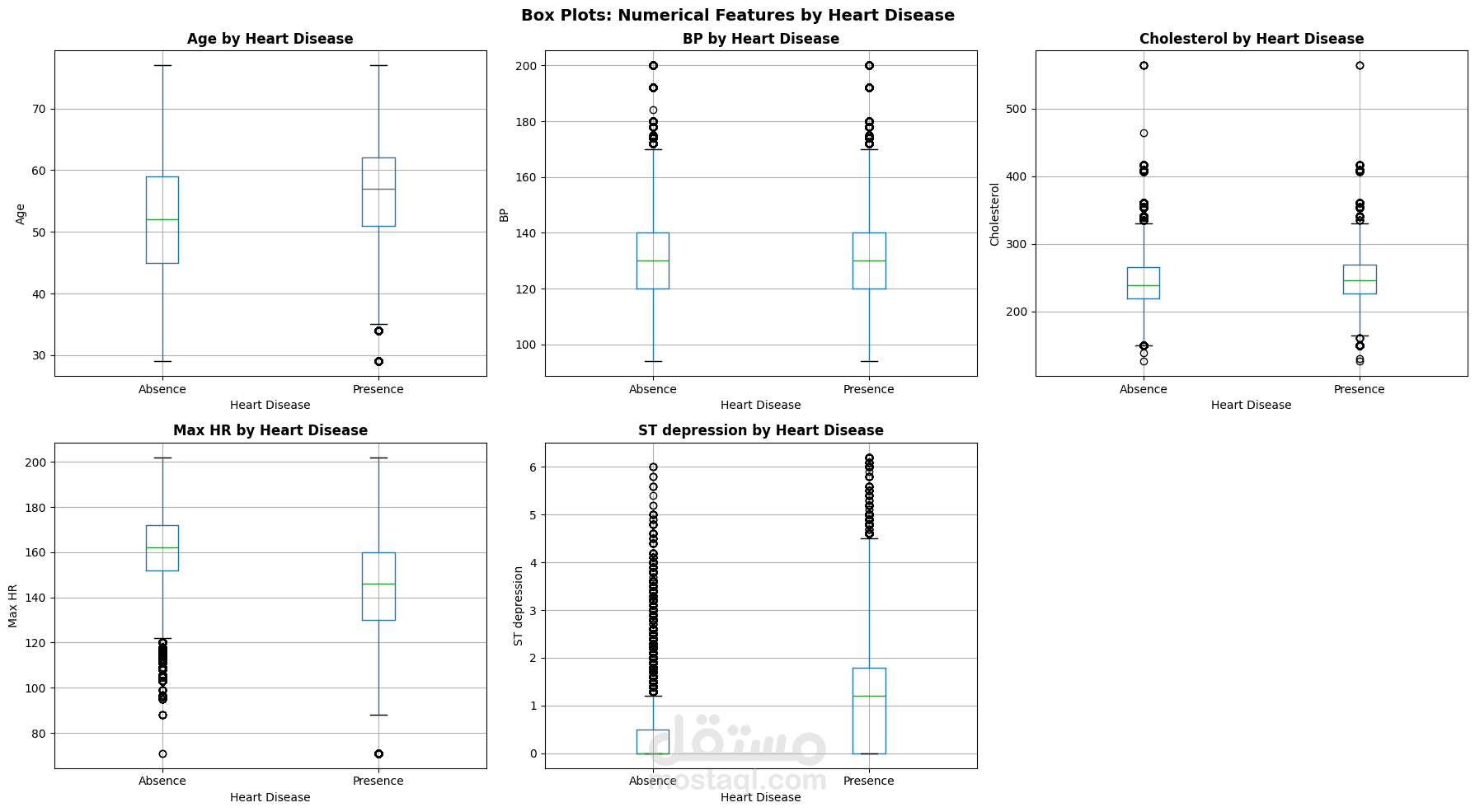
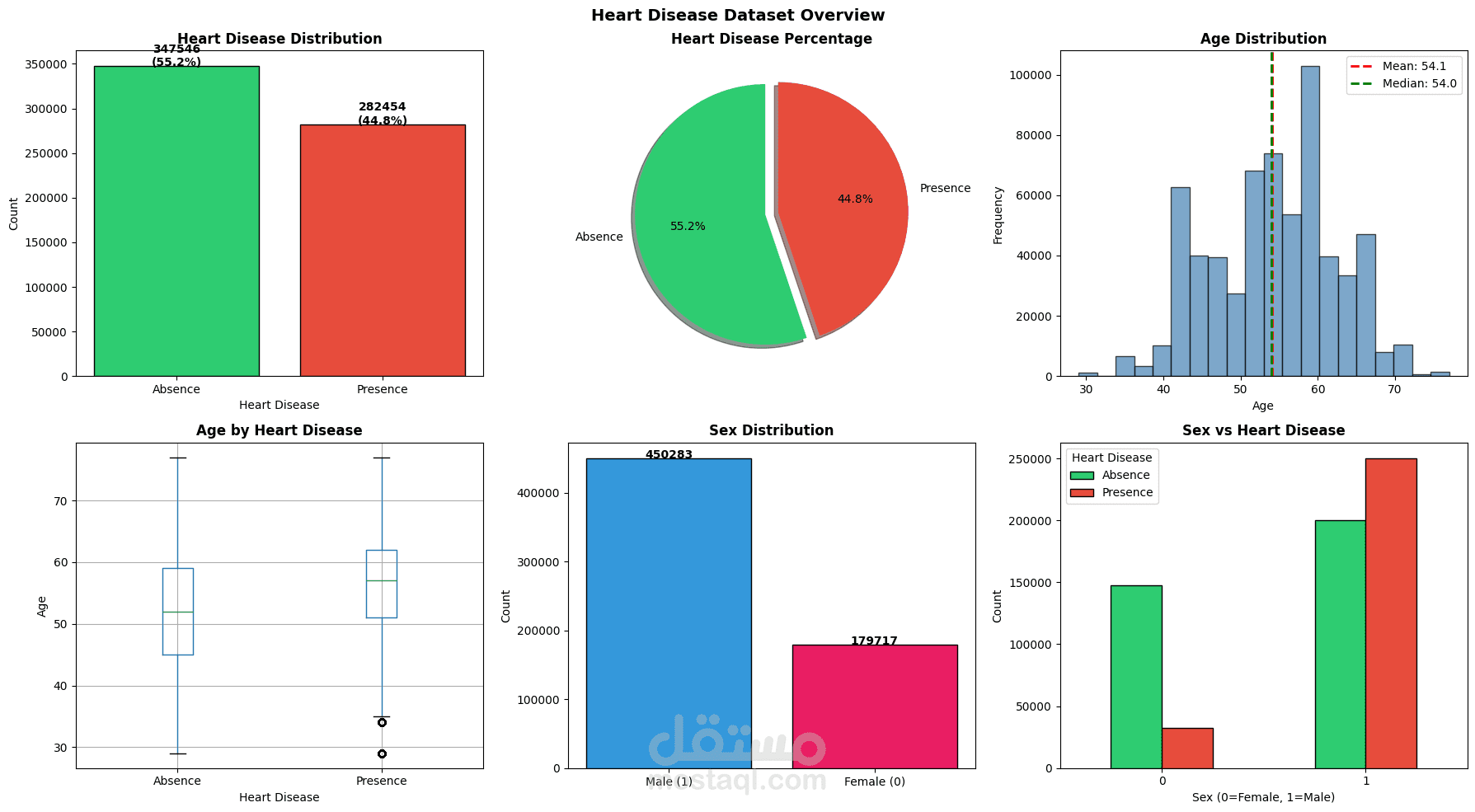
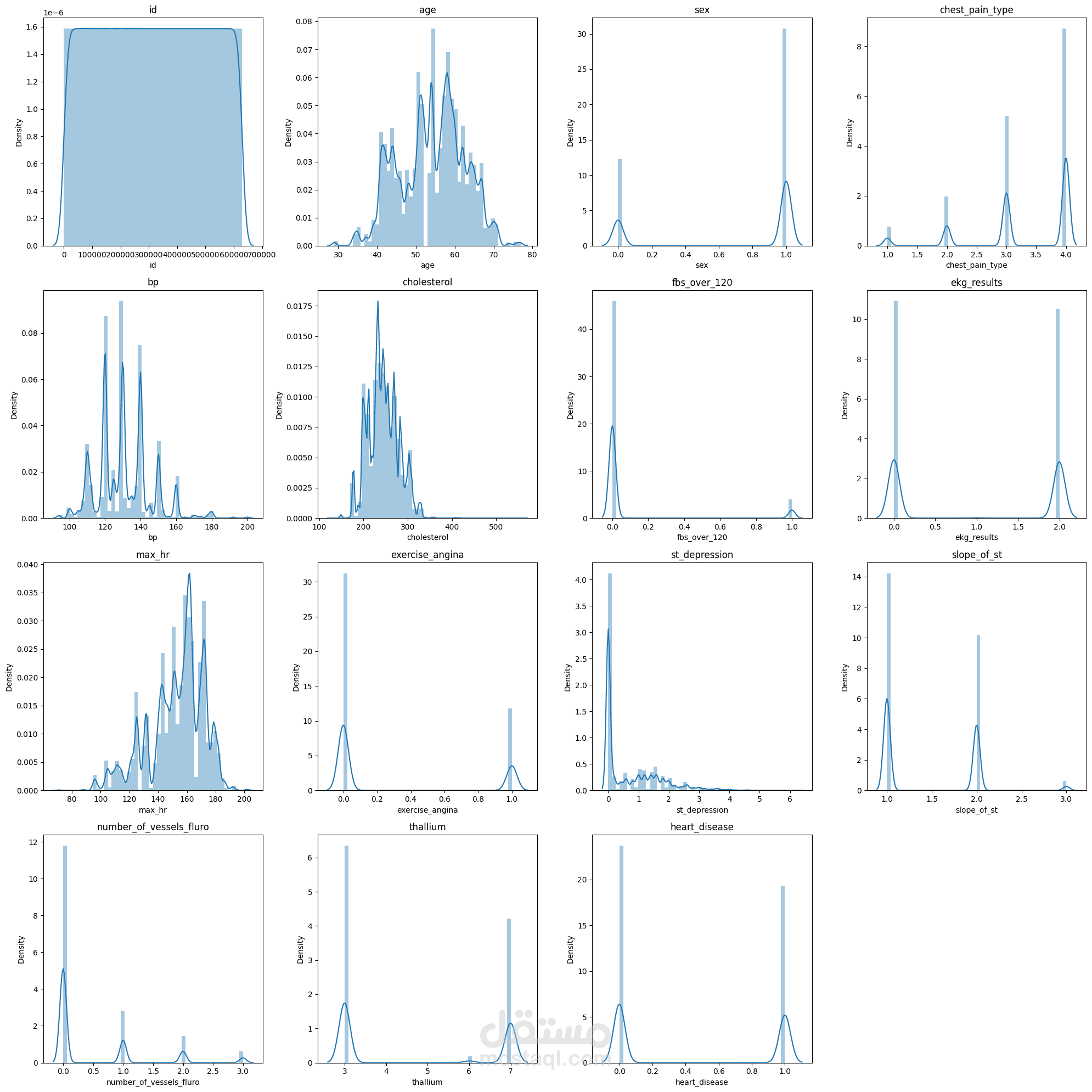
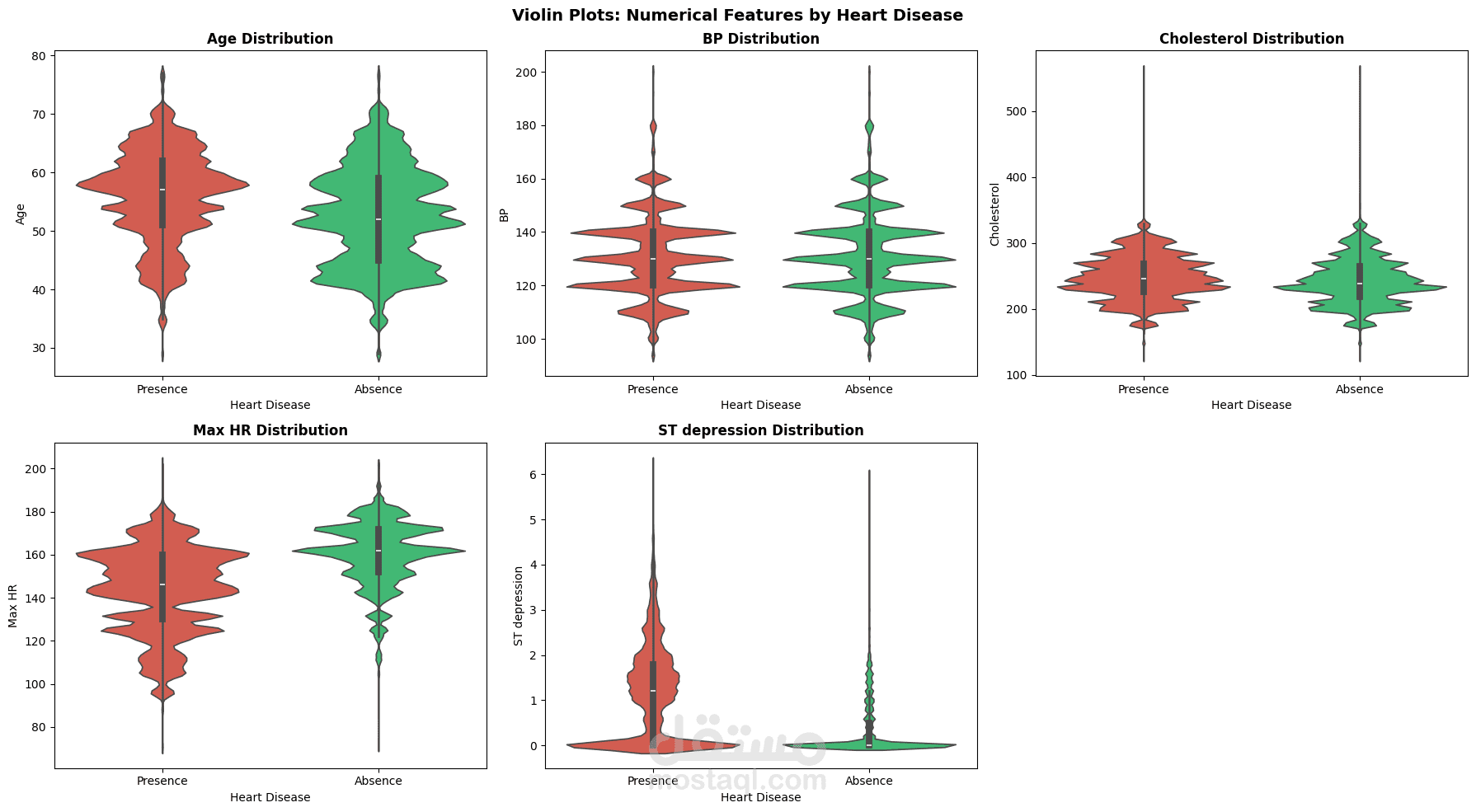
يهدف هذا المشروع إلى بناء نظام Machine Learning للتنبؤ بوجود Heart Disease اعتمادًا على بيانات سريرية وتشخيصية واسعة النطاق. يشمل العمل مراحل Data Cleaning و Exploratory Data Analysis (EDA) لفهم طبيعة البيانات والعلاقات بين المتغيرات، يلي ذلك تدريب نماذج Tree-Based Models مثل XGBoost لتعلّم الأنماط غير الخطية الكامنة في البيانات.
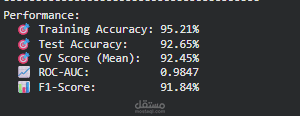
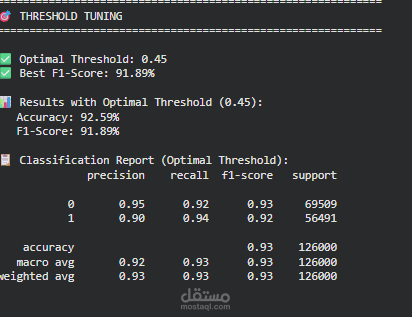
يركّز المشروع على تقييم الأداء باستخدام مقاييس متعددة مثل Accuracy و Recall و F1-Score، مع مراعاة الجانب السريري وأهمية Interpretability في التطبيقات الطبية. كما يوضح المشروع أن الاعتماد على Raw Clinical Features قد يكون أكثر فاعلية من الإفراط في Feature Engineering عند التعامل مع مجموعات بيانات كبيرة وغنية بالمعلومات.
في النهاية، يقدّم النظام نموذجًا قادرًا على إنتاج تنبؤات موثوقة يمكن الاستفادة منها في Clinical Decision Support Systems مع التأكيد على أن النتائج إرشادية ولا تُغني عن التشخيص الطبي.