NEWS Web Scraper – نظام آلي وقابل للتوسّع لاستخراج المقالات من مواقع الأخبار
تفاصيل العمل

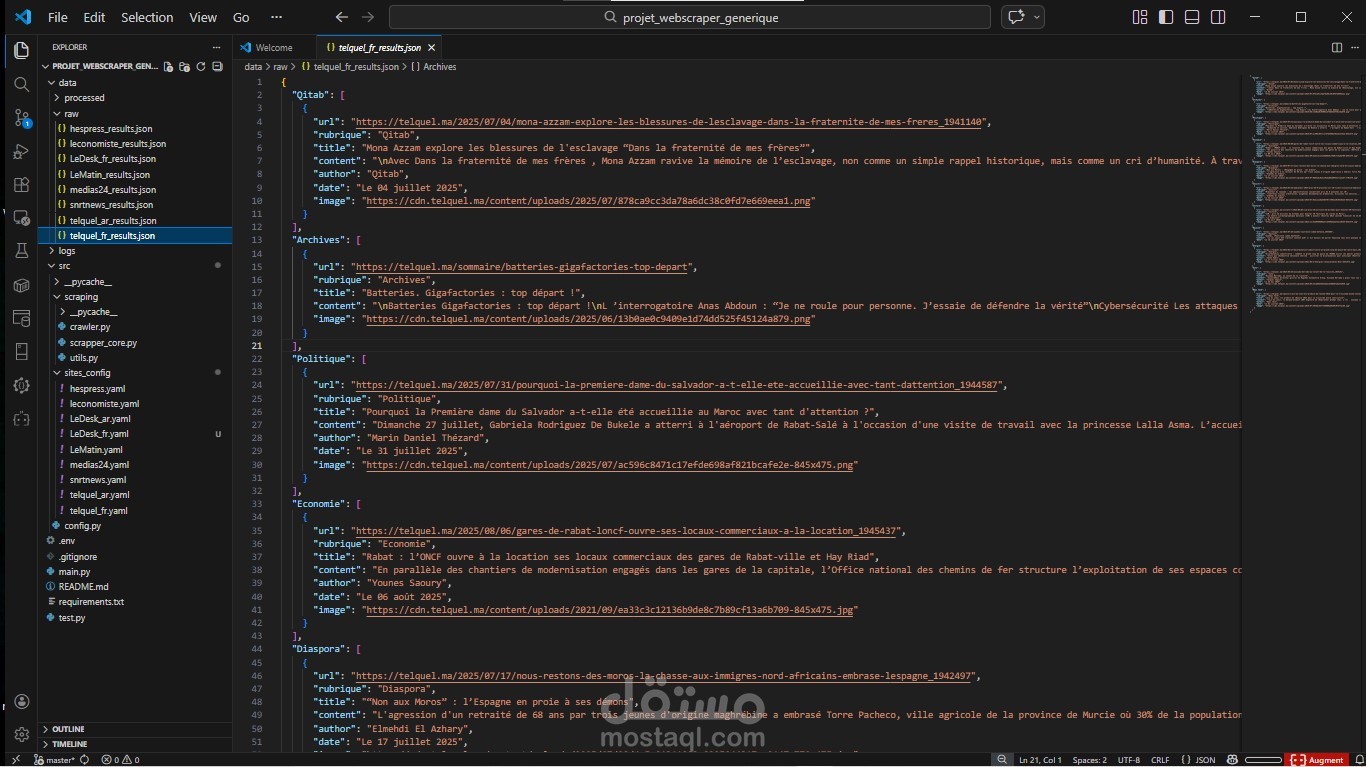
في هذا المشروع قمت بتطوير Web Scraper عام (Generic News Scraper) مخصص لاستخراج المقالات من مواقع الأخبار، مع تصميم هندسي يسمح بإضافة مواقع جديدة دون أي تعديل على كود Python.
يعتمد النظام على محرك scraping موحّد يتم التحكم فيه بالكامل عبر ملفات إعدادات YAML، مما يجعل الحل مرنًا، قابلًا لإعادة الاستخدام، وسهل الصيانة.
الميزات الرئيسية
- Scraping عام وقابل للتوسّع
محرك واحد قادر على استخراج البيانات من عدة مواقع إخبارية مختلفة.
- إعدادات مرنة عبر YAML
تحديد CSS Selectors و Regex لكل موقع داخل ملف إعدادات مستقل.
- إدارة متقدمة للسجلات (Logs)
تسجيل مفصّل للعمليات في الكونسول وملفات logs مع دوران تلقائي.
- فصل واضح للمهام (Clean Architecture)
• Orchestration
• Scraping Core
• Utilities
• Configuration
- سهولة إضافة مواقع جديدة
يتم ذلك فقط بإنشاء ملف .yaml جديد دون تعديل المنطق البرمجي.
أنواع البيانات المستخرجة:
- عنوان المقال
- رابط المقال
- تاريخ النشر
- محتوى المقال
- القسم / الفئة
- مصدر الخبر
المخرجات (Deliverables):
- بيانات خام منظمة داخل مجلد مخصص
- بيانات معالجة وجاهزة للاستخدام
- نظام Logging كامل لمتابعة الأداء والأخطاء
- كود نظيف، قابل للتوسّع وإعادة الاستخدام
- الأدوات والتقنيات المستخدمة:
Python
Web Scraping
BeautifulSoup / Requests
YAML Configuration
Logging & Log Rotation
Data Processing
قيمة المشروع
هذا المشروع يبرز قدرتي على:
- تصميم حلول Scraping احترافية وقابلة للتوسّع
- تطبيق مبادئ الهندسة البرمجية النظيفة
- بناء أنظمة موثوقة تصلح للاستخدام طويل الأمد في بيئات إنتاجية