Data Preprocessing Module V2
تفاصيل العمل
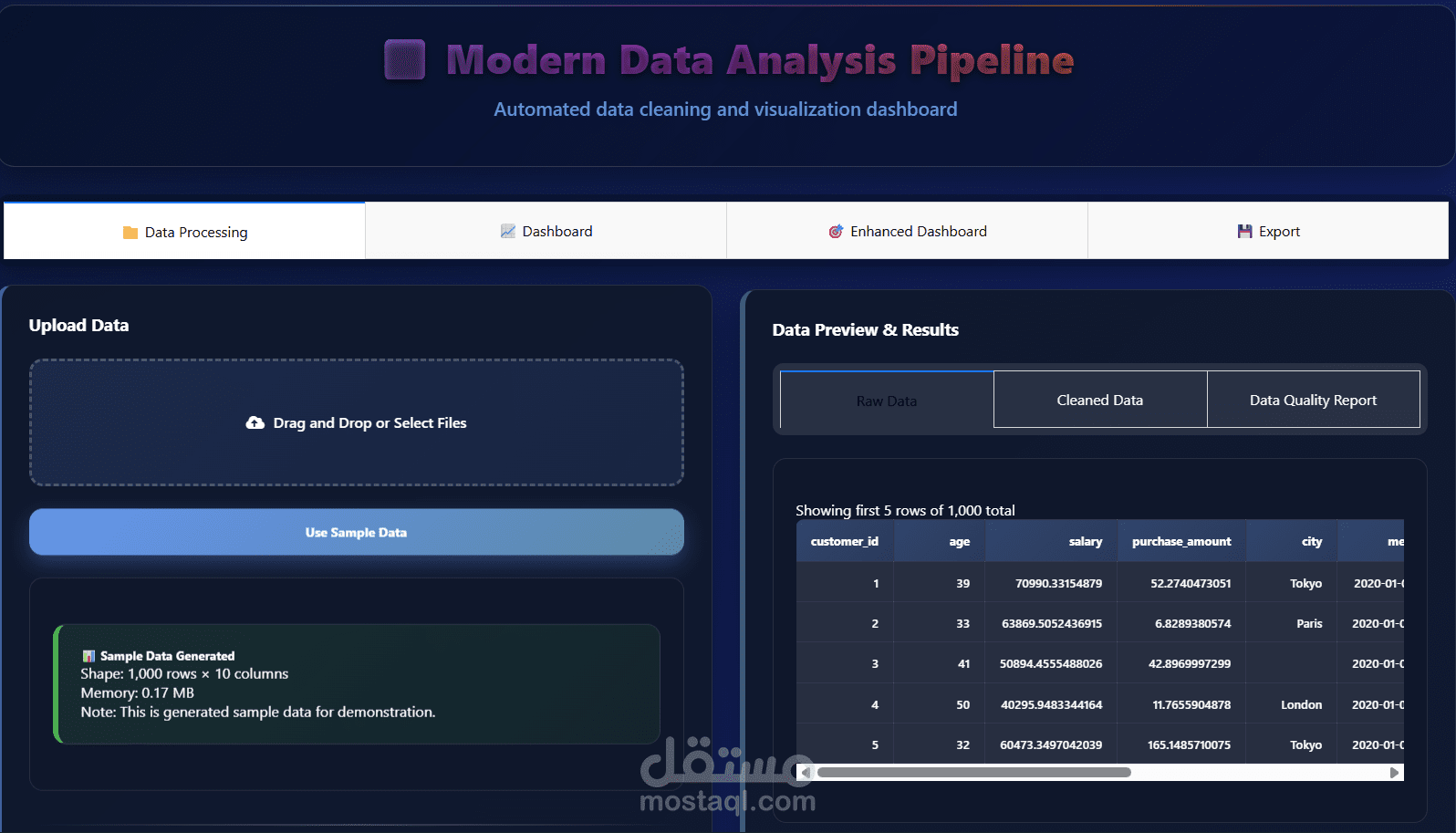

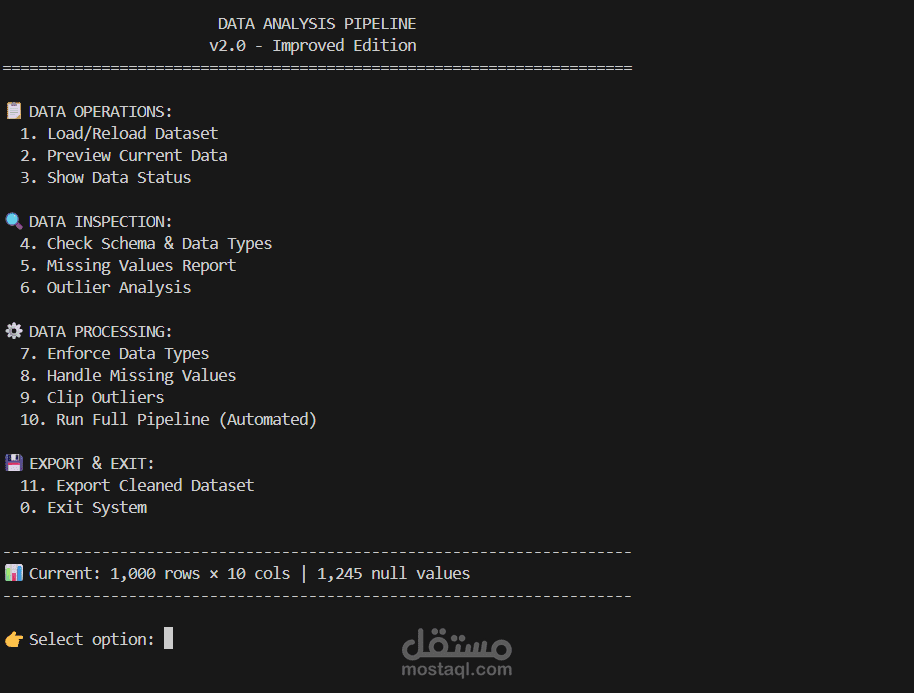
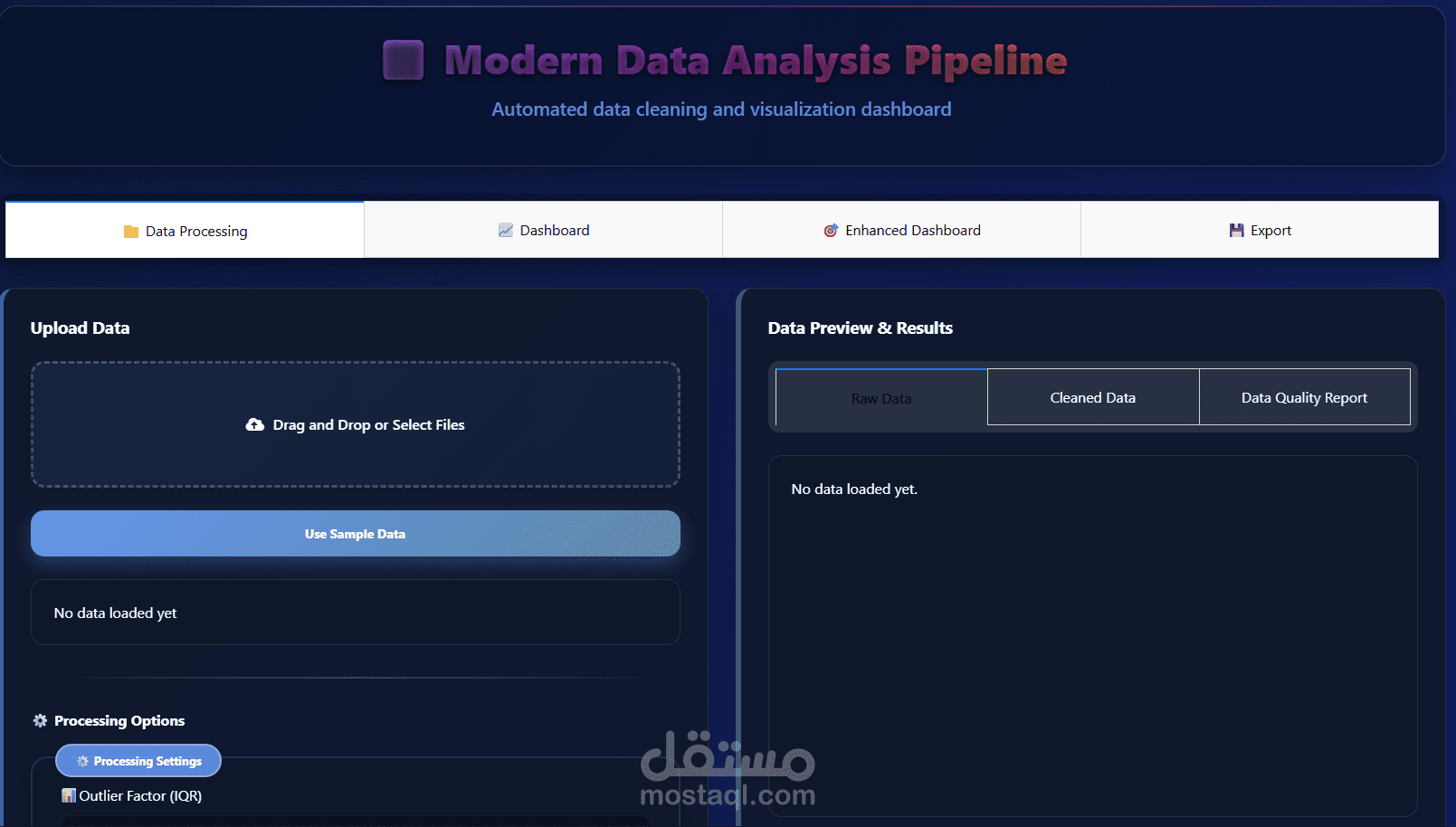
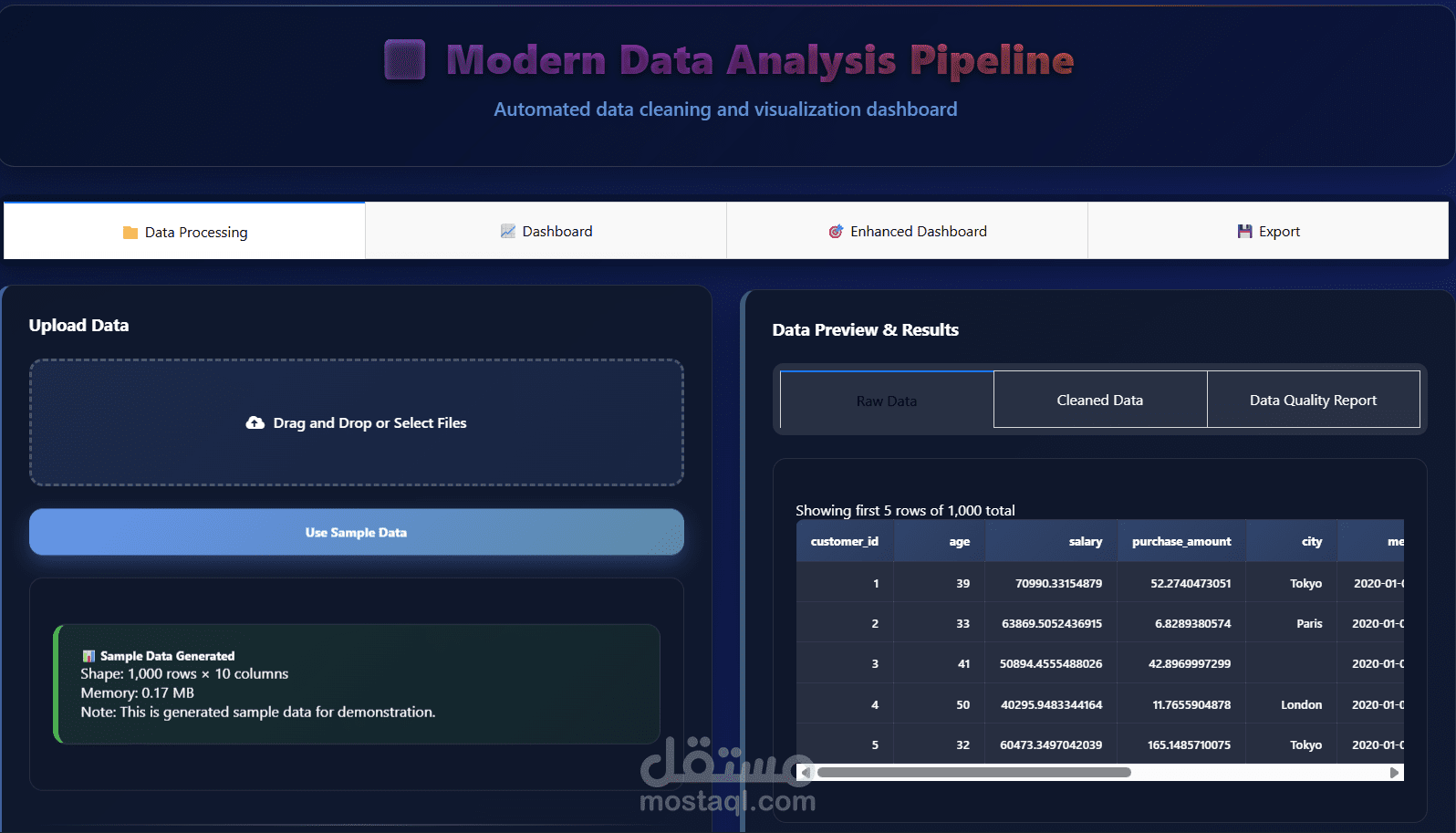
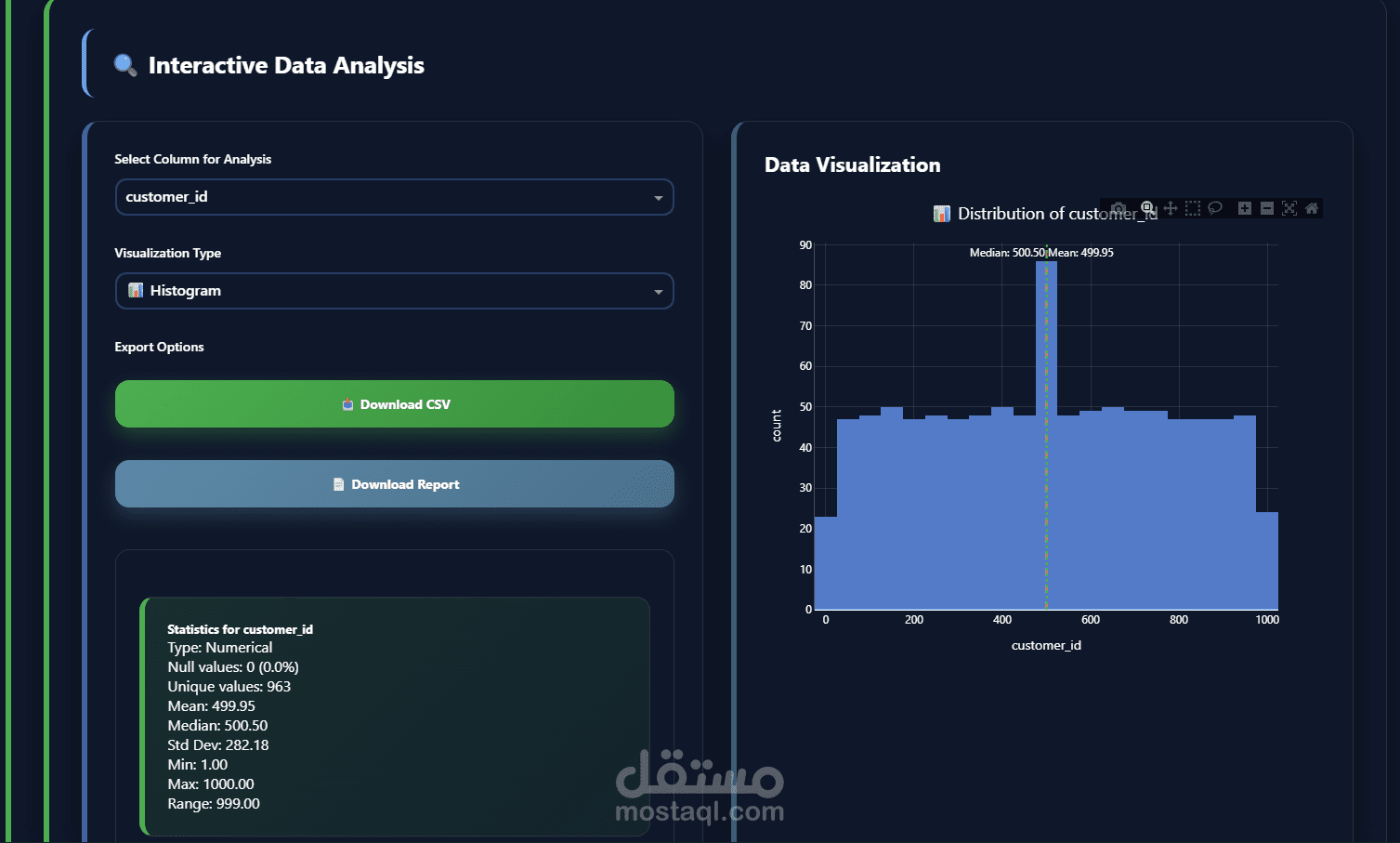
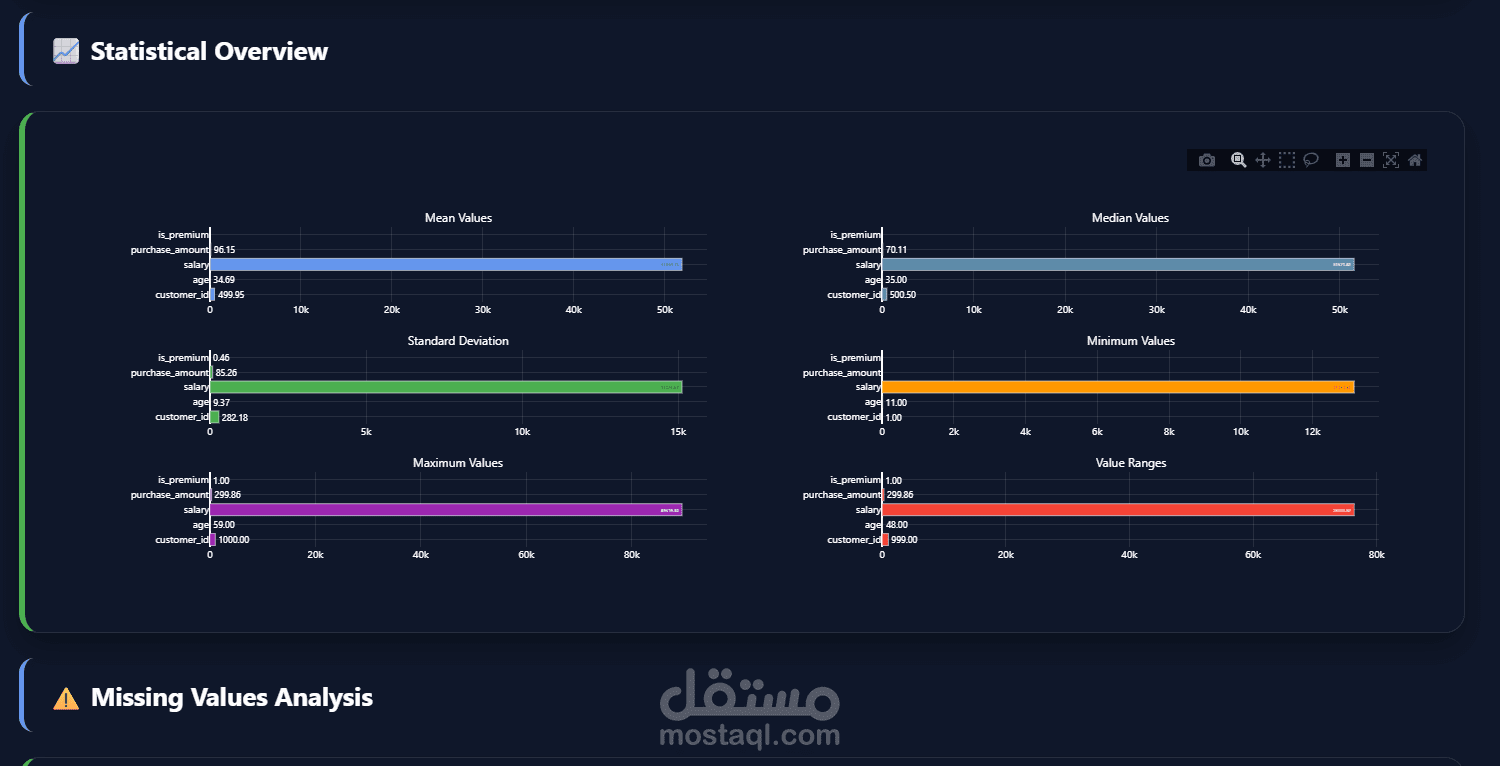
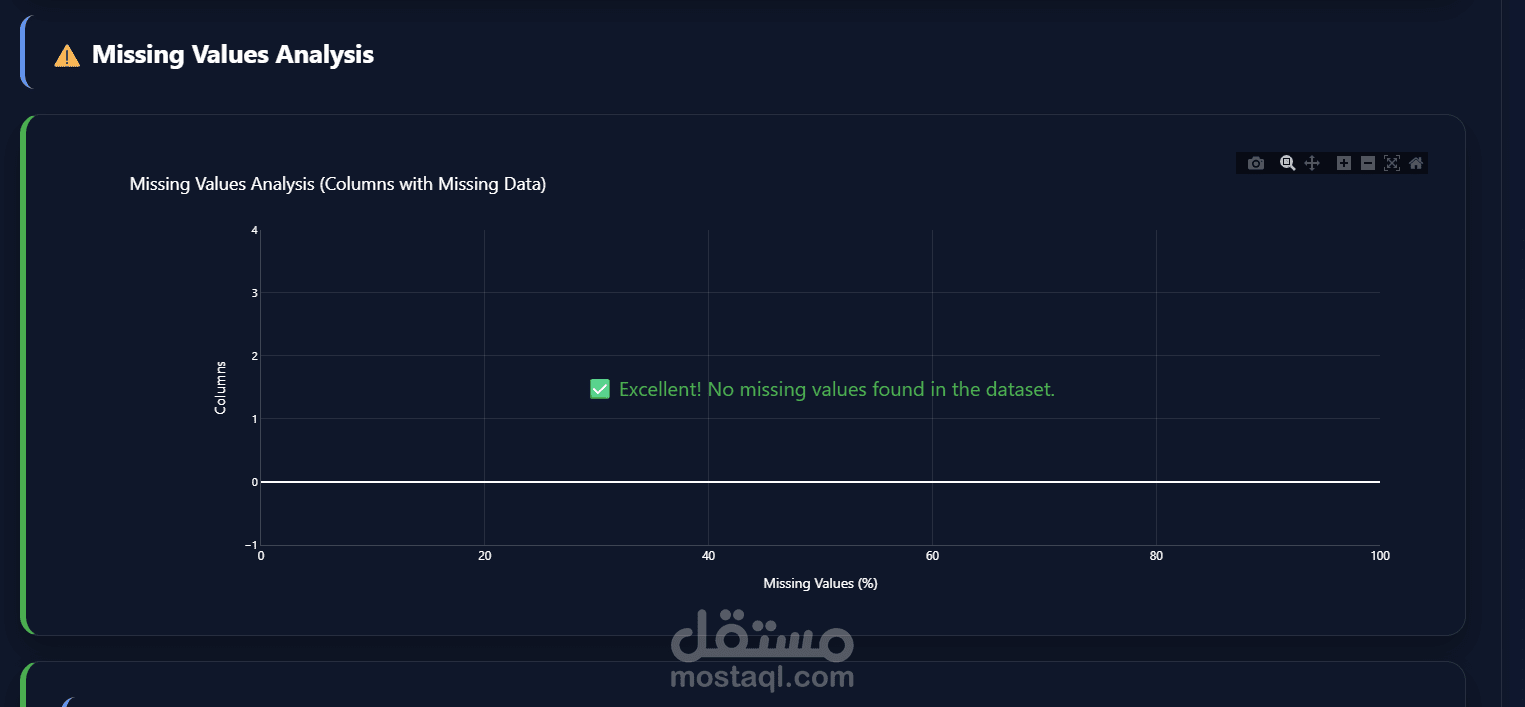
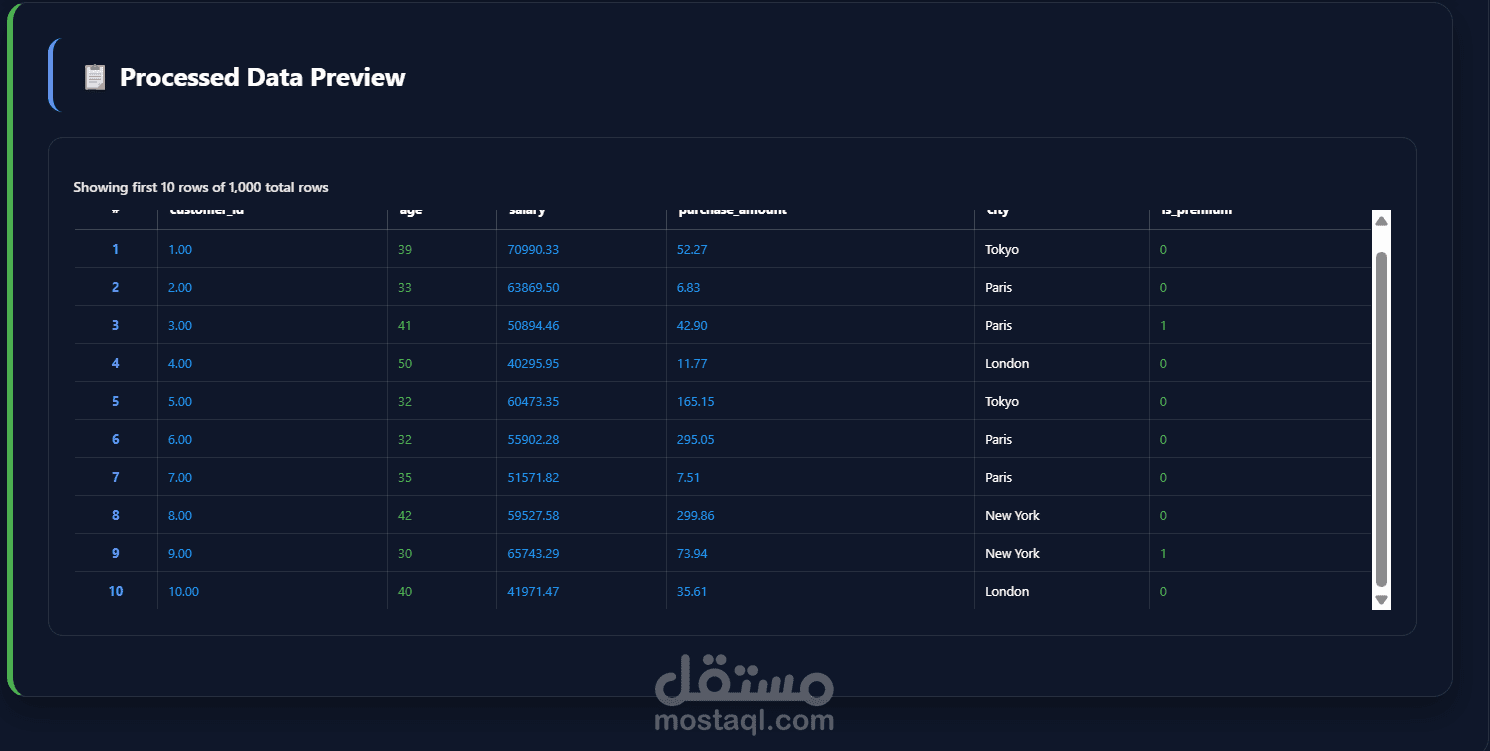
يهدف مشروع Data Preprocessing Module إلى توفير وحدة احترافية مرنة وقابلة لإعادة الاستخدام لمعالجة البيانات وتجهيزها قبل استخدامها في نماذج تعلم الآلة وتحليل البيانات. تم تصميم المشروع لتبسيط خطوات الـ Data Preprocessing الشائعة وتحويلها إلى مسار عمل منظم (Pipeline) يمكن دمجه بسهولة داخل أي مشروع Machine Learning باستخدام Python و Scikit-learn.
تتضمن الوحدة مجموعة من العمليات الأساسية، من أهمها:
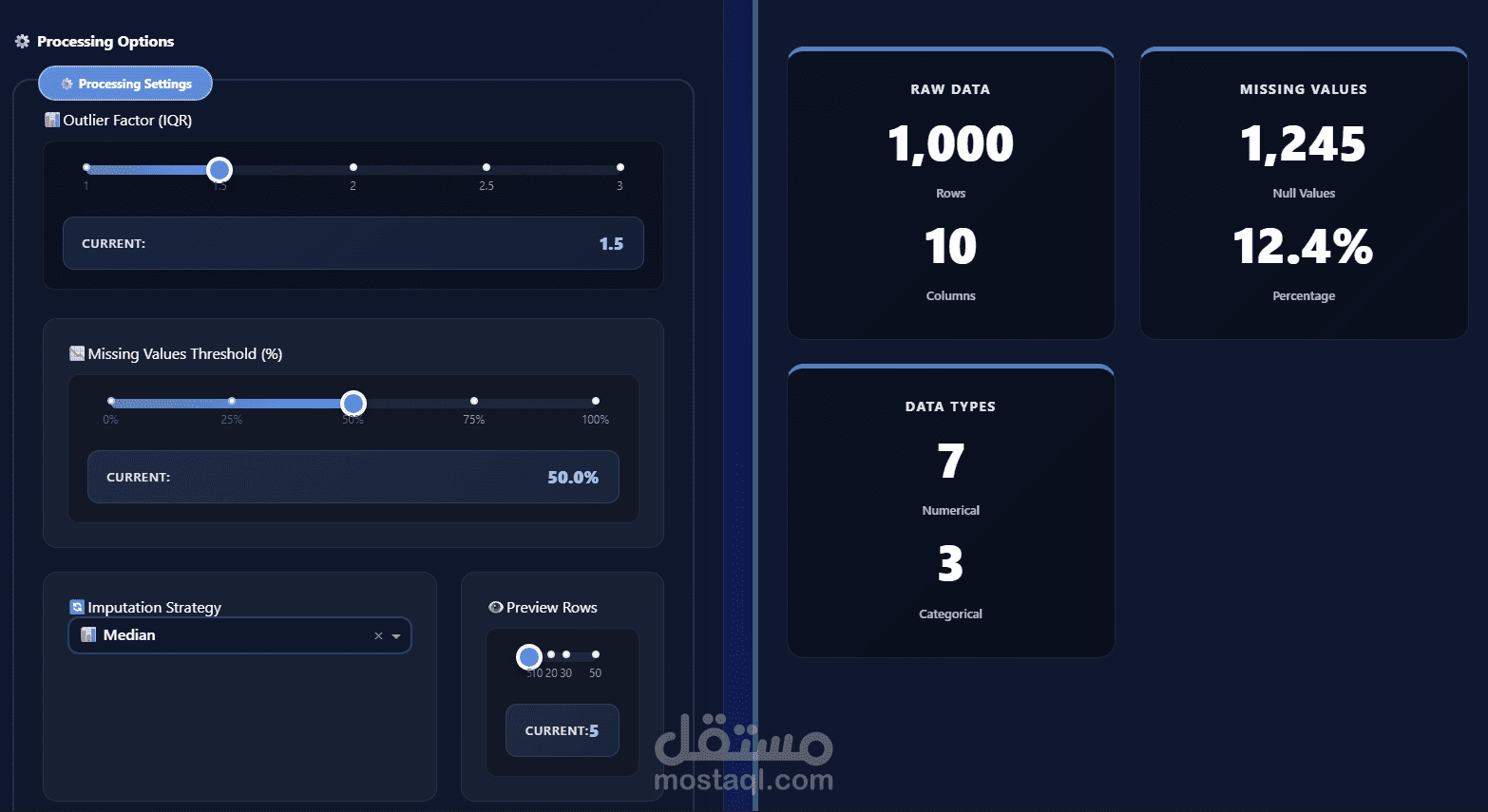
التعامل مع القيم المفقودة باستخدام استراتيجيات متعددة
كشف ومعالجة القيم الشاذة (Outliers) لتحسين جودة البيانات
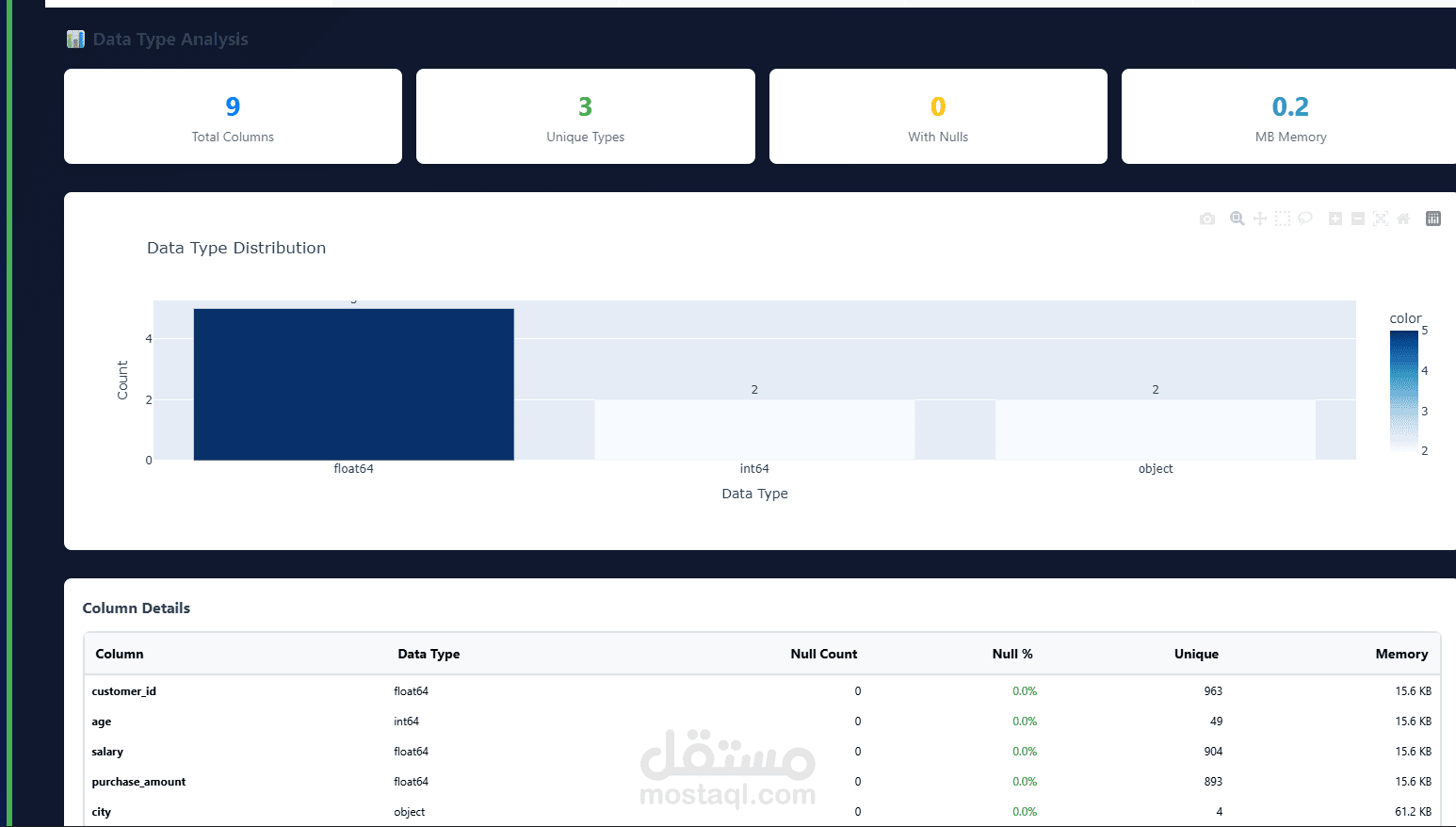
ترميز المتغيرات الفئوية (Categorical Encoding)
توحيد وتقييس البيانات (Scaling & Normalization)
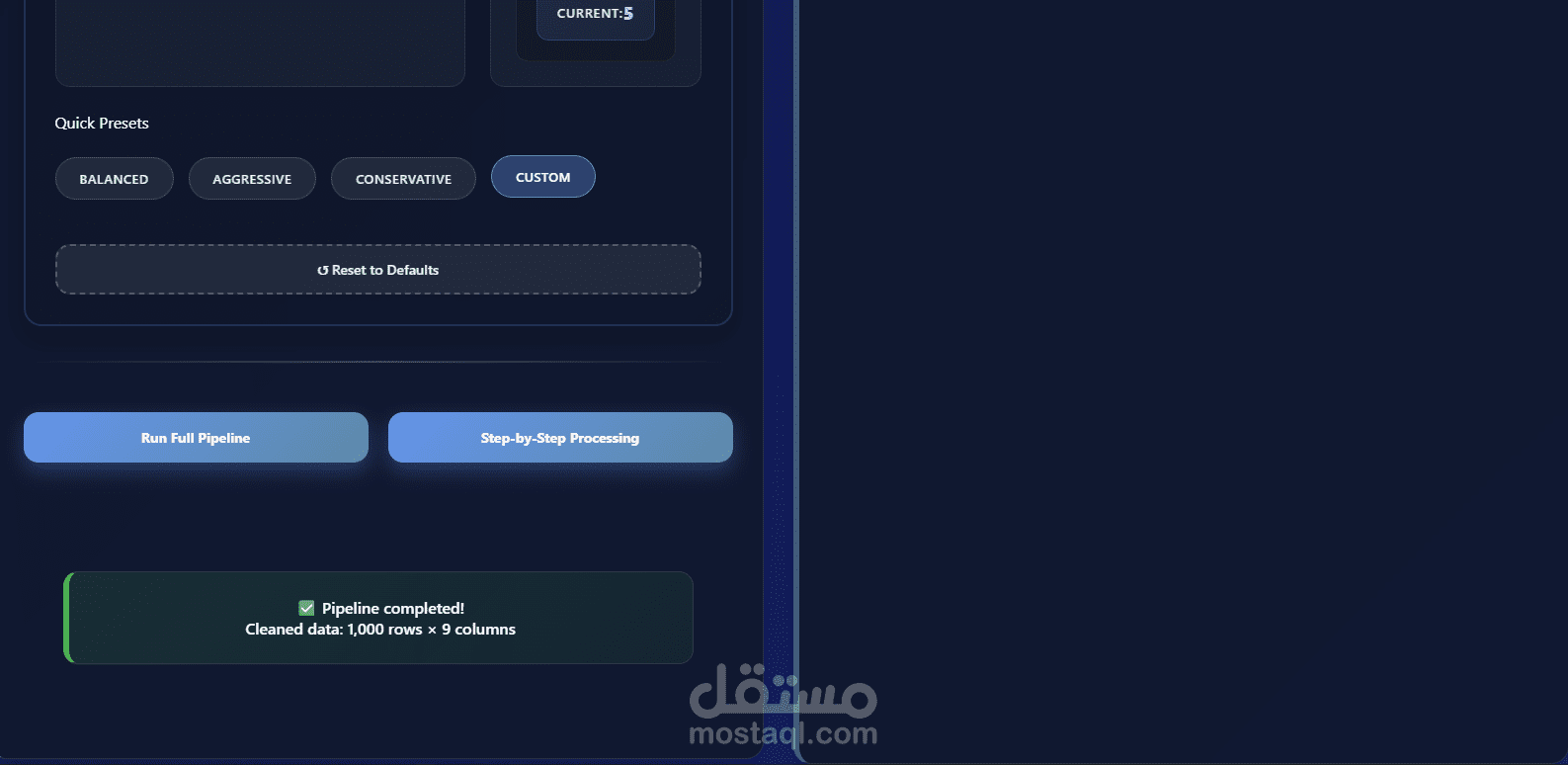
بناء Pipelines مخصصة بالاعتماد على
BaseEstimator و TransformerMixin
دعم إعادة الاستخدام والتوسّع بسهولة داخل المشاريع المختلفة
يساعد هذا المشروع على:
تقليل تكرار الكود وتحسين قابليته للصيانة
ضمان تطبيق نفس خطوات المعالجة على بيانات التدريب والاختبار
تحسين جودة البيانات وزيادة دقة النماذج
تسريع دورة تطوير نماذج تعلم الآلة
تطبيق أفضل الممارسات الهندسية في مشاريع Data Science
تم تنفيذ المشروع بأسلوب منظم وقابل للتوسّع، مما يجعله مناسبًا للاستخدام في المشاريع الحقيقية، الأبحاث، والتطبيقات العملية في مجال علوم البيانات وتعلم الآلة.