CLIP model
تفاصيل العمل

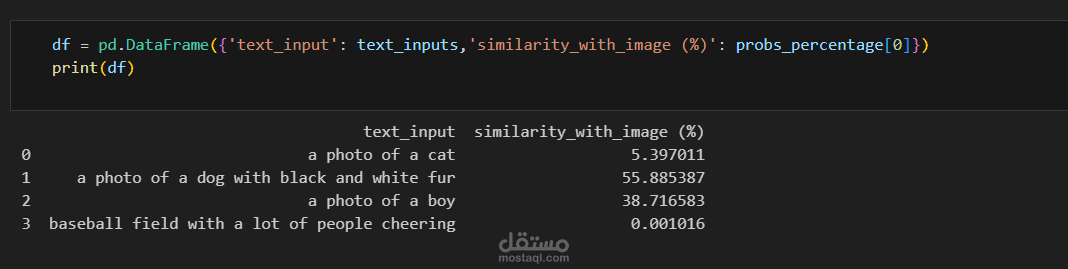
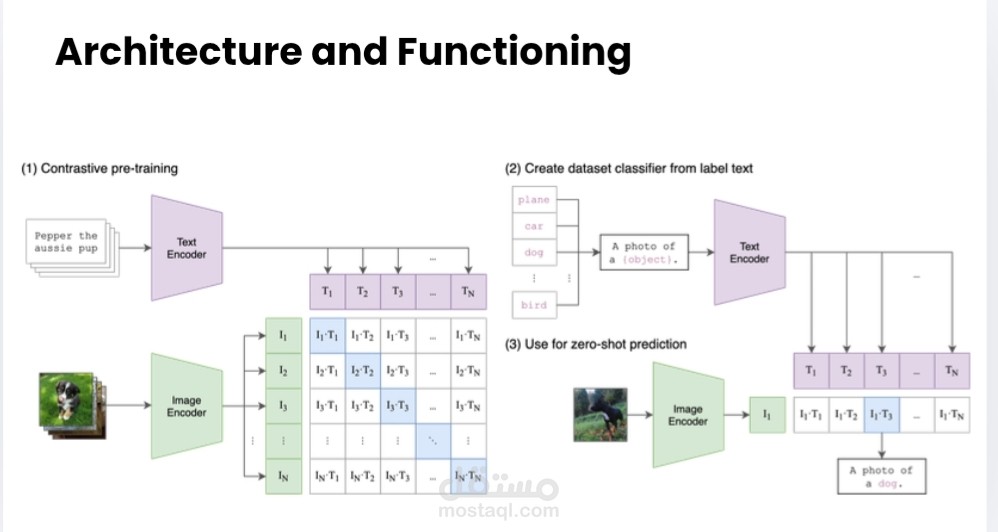
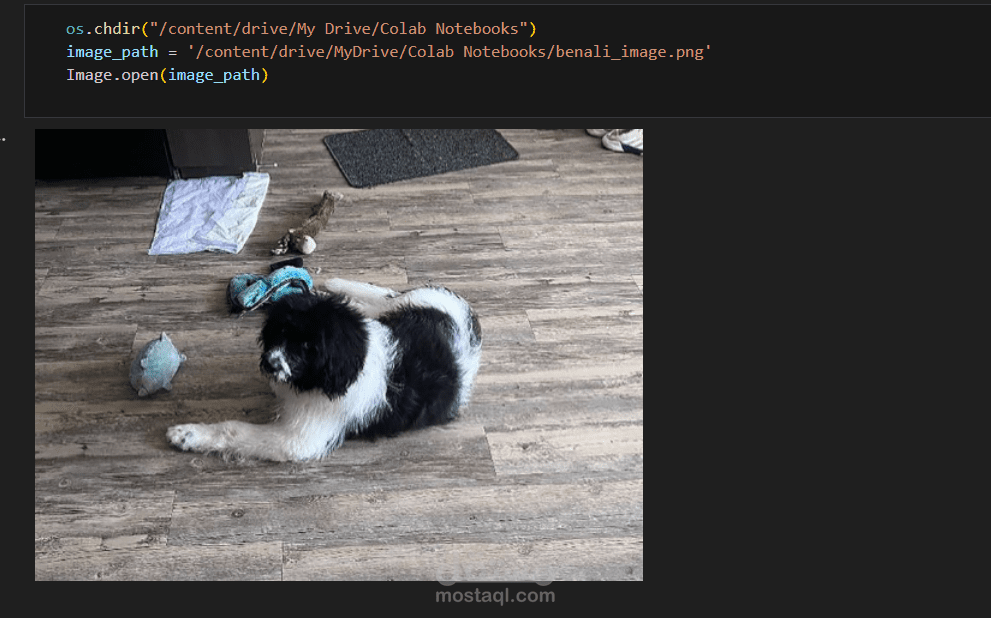
شروع CLIP (Contrastive Language–Image Pretraining) بيهدف لربط الصور بالنصوص باستخدام نموذج ذكاء اصطناعي بيقدر يفهم العلاقة بين الصورة والجملة اللي بتوصفها. في المشروع ده بنُدخل صورة للنموذج ومعاها مجموعة جُمل محتملة، والنموذج بيحسب درجة التشابه بين الصورة وكل جملة باستخدام تمثيل مشترك (Embeddings). بعد كده بيختار الجملة اللي ليها أعلى درجة تشابه وبتكون هي الوصف الأقرب للصورة. النموذج بيعتمد على تدريب متزامن للصور والنصوص، وده بيساعده على الفهم الدلالي للصورة من غير ما يكون محتاج تدريب مخصص لكل فئة. المشروع بيستخدم في تطبيقات زي تصنيف الصور بدون تدريب مسبق، البحث بالصور باستخدام النص، وفهم المحتوى البصري لغويًا.