Mini RAG System (Generative AI Project – LLM)
تفاصيل العمل
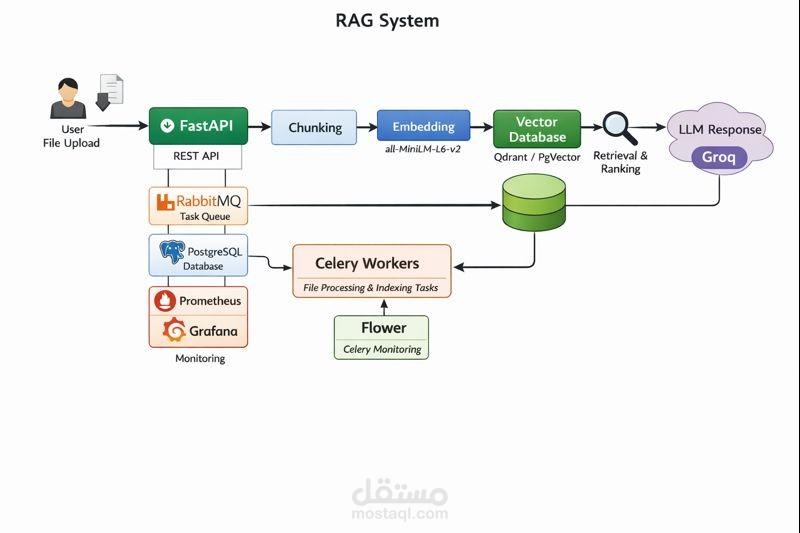
Developed a Mini Retrieval-Augmented Generation (RAG) system using Groq for high-speed LLM inference and Hugging Face Sentence Transformers for embedding generation. Implemented document preprocessing, chunking, and embedding evaluation to ensure accurate and context-aware responses. Built a scalable backend with FastAPI, utilizing SQLAlchemy with PostgreSQL for efficient storage and retrieval of document chunks and embeddings. Integrated Celery to manage long-running background tasks asynchronously, improving system responsiveness and throughput. Containerized the full application with Docker for consistent deployment and implemented monitoring with Prometheus and Grafana to track performance and resource utilization.