Projects Multilingual Sentiment Analysis (NLP Project)
تفاصيل العمل
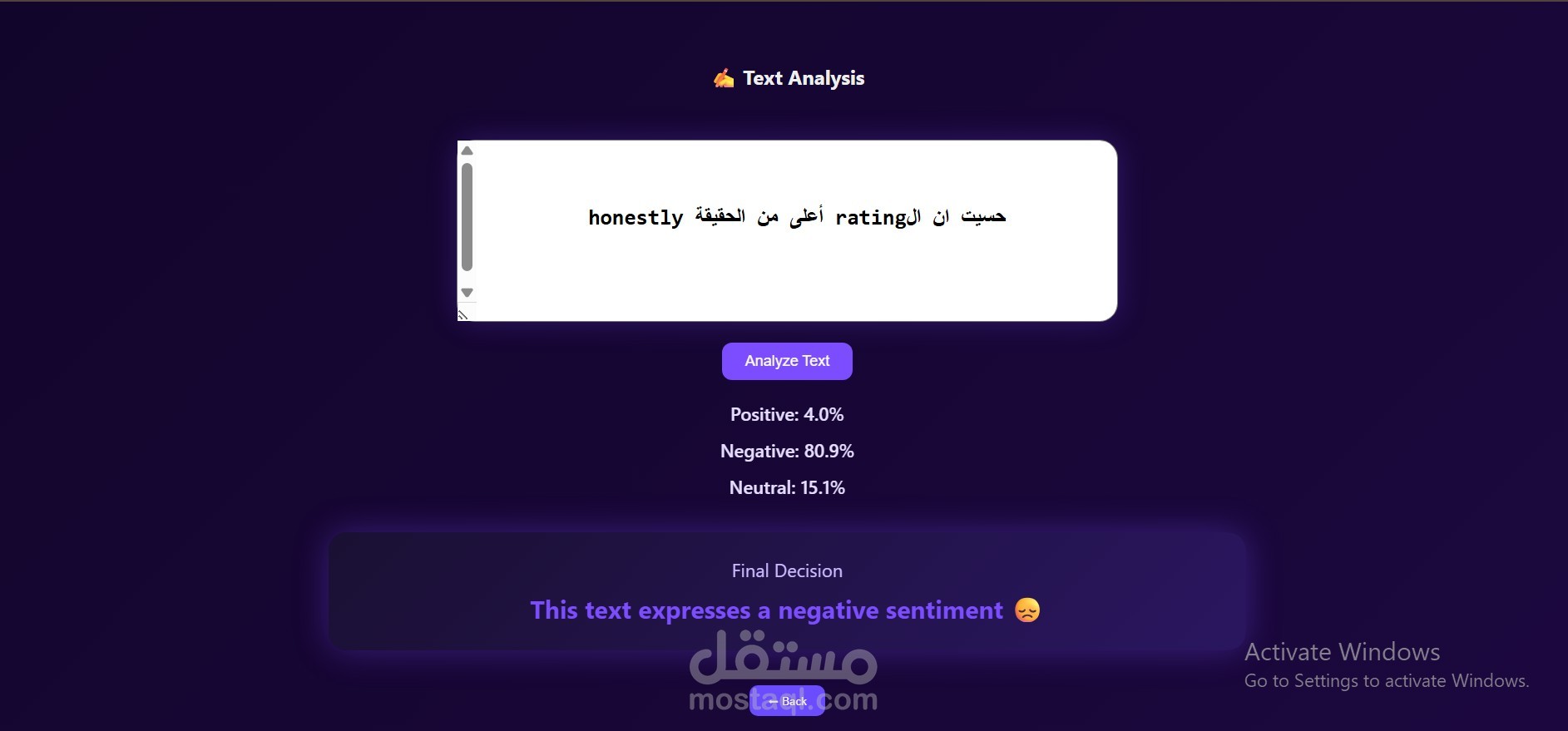
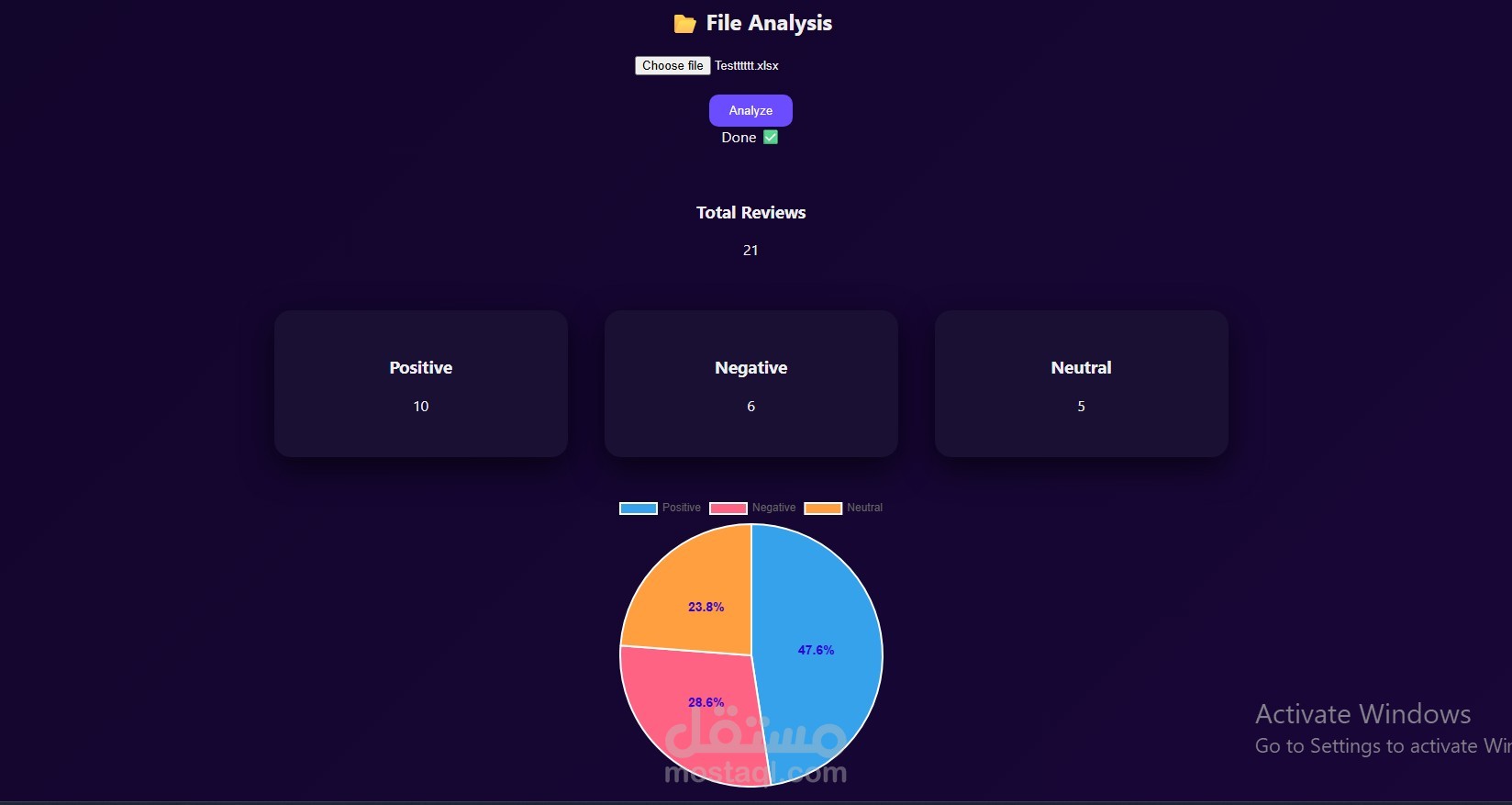
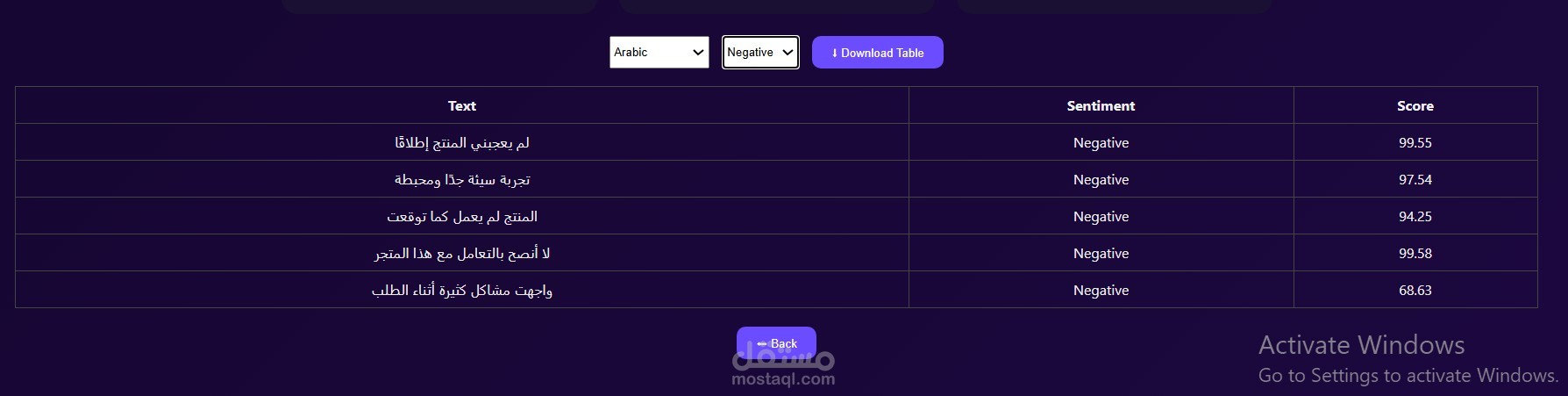
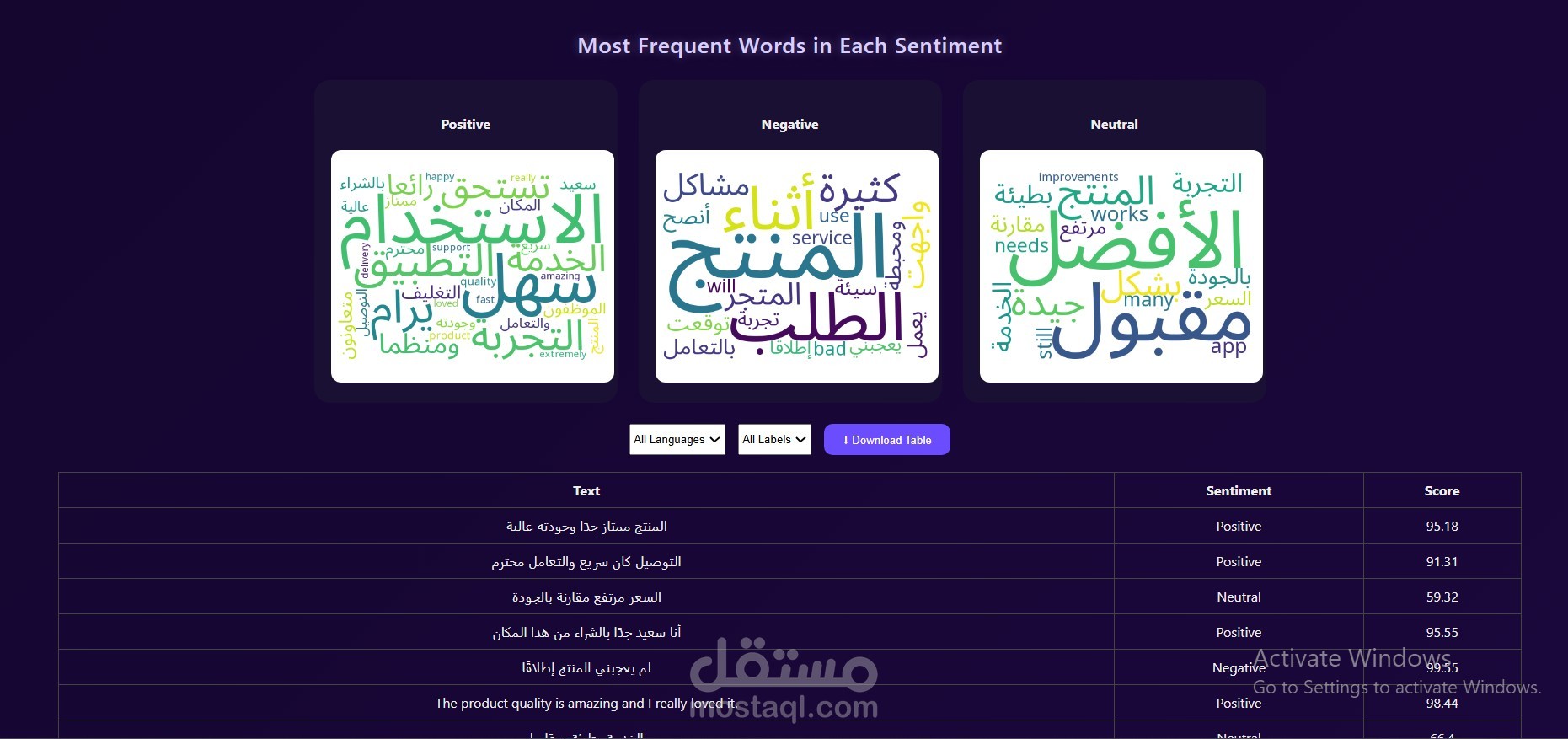
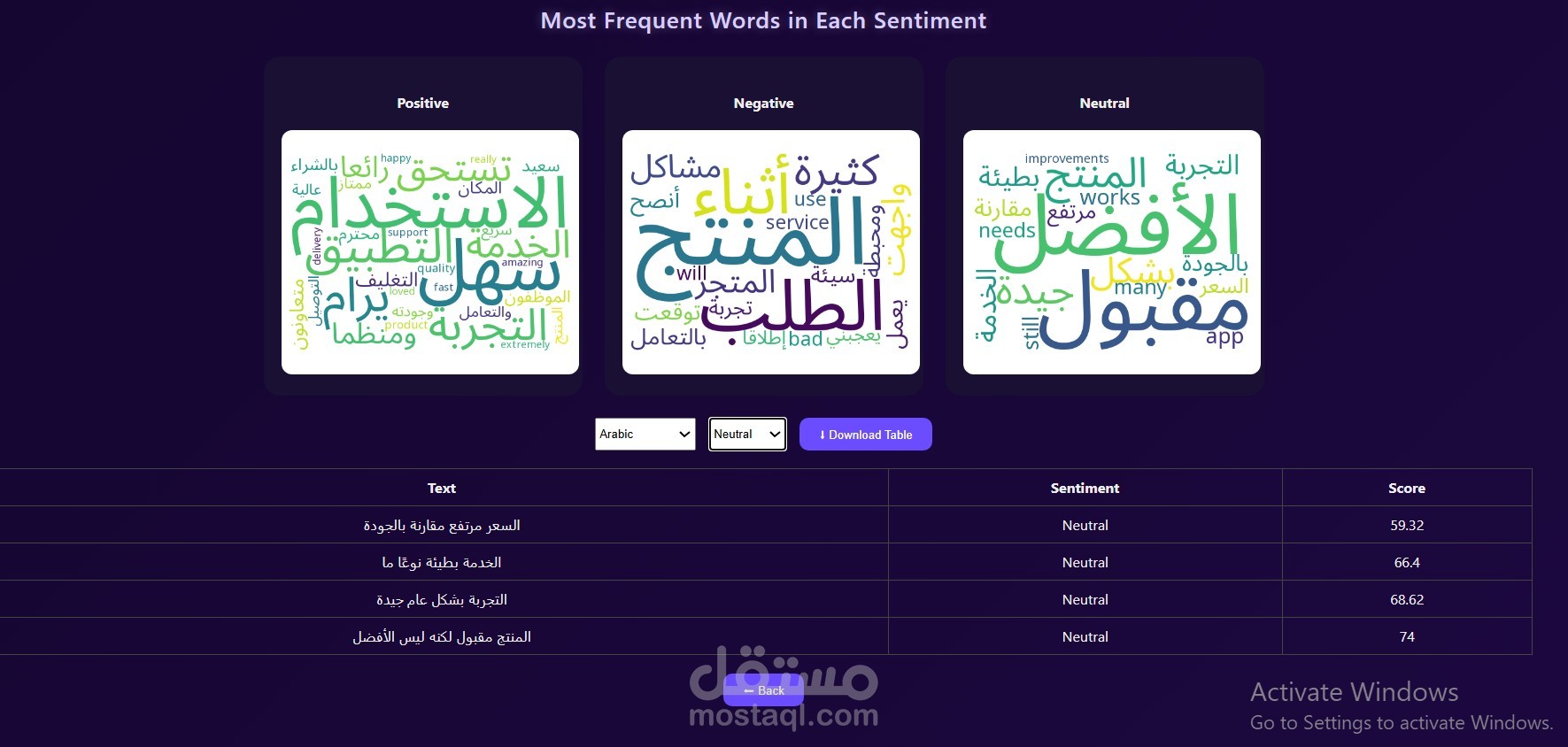
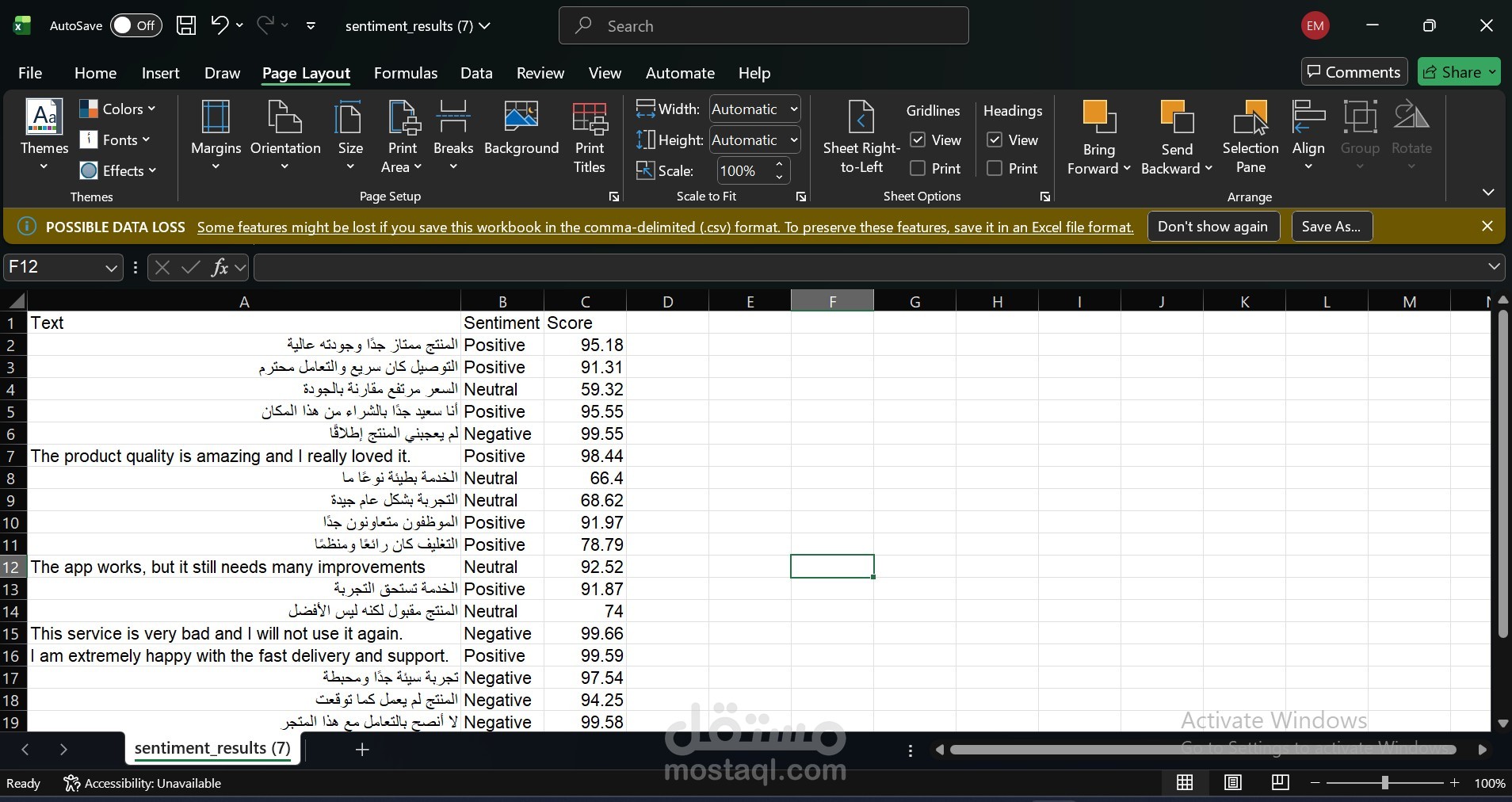
Developed a multilingual Sentiment Analysis application to classify Arabic and English text into Positive, Neutral, and Negative categories. Implemented using XLM-RoBERTa and enhanced Arabic training data through back translation to improve model generalization, leveraging a dataset of 115K Arabic and 150K English samples. Deployed the system using FastAPI and Docker to ensure scalable and efficient inference. Achieved 80% accuracy and a 79.4% F1-score with consistent performance across sentiment classes.