التصنيف متعدد الفئات لأربع فئات من الآفات الجلدية
تفاصيل العمل
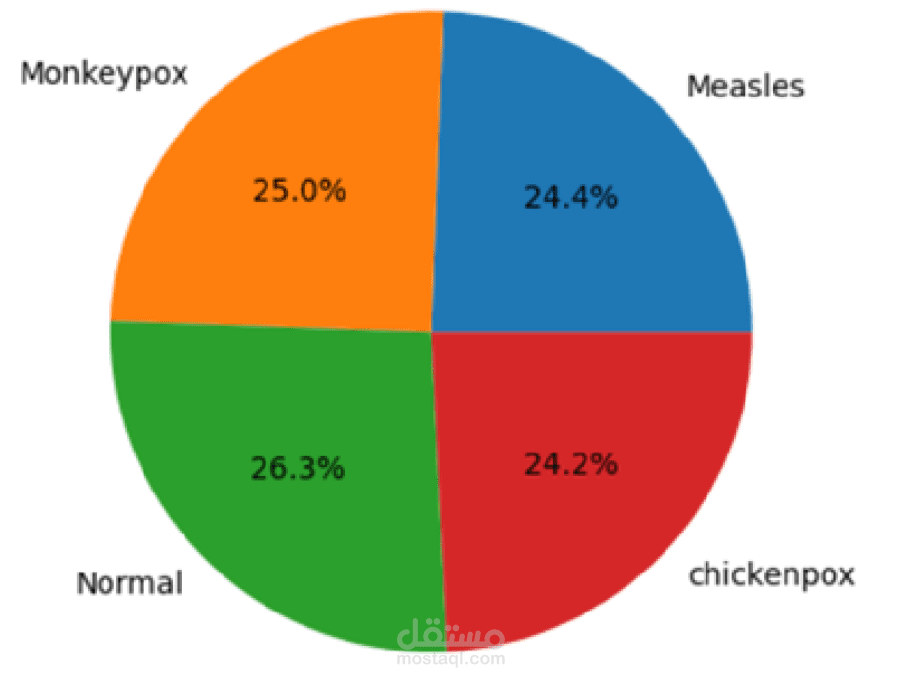
تتكون مجموعة البيانات من أربع فئات: جدري القرود، جدري الماء، الحصبة، والحالات الطبيعية. تم جمع جميع الصور من مصادر متاحة عبر الإنترنت، وتم تطوير مجموعة البيانات من قبل قسم علوم وهندسة الحاسوب بجامعة الإسلامية في كُشْتِيّا بنغلاديش. جميع الصور كانت بأبعاد (224×224×3). نظرًا لعدم توازن البيانات، حيث تُعد فئتا الحصبة وجدري الماء فئات أقل تمثيلًا، تم تطبيق تقنيات زيادة البيانات لمعالجة هذا الخلل.
في مرحلة زيادة البيانات (Data Augmentation)، تم تطبيق تحويلات هندسية شملت التدوير حتى 30 درجة، والإزاحة العمودية، والقص، والتكبير بقيمة 0.2، إضافة إلى قلب بعض الصور أفقيًا مع استخدام نمط التعبئة العاكسة (Reflect). تم تطبيق هذه العمليات على فئتي الحصبة وجدري الماء فقط، حيث تم توليد ثلاث صور إضافية لكل صورة، ليصل الحد الأقصى إلى 270 صورة لكل فئة. ارتفع عدد الصور الإجمالي من 770 إلى 1114 صورة بعد زيادة البيانات.
في مرحلة المعالجة المسبقة، تم ترميز الفئات رقميًا، حيث تشير القيم إلى: الحالة الطبيعية، جدري القرود، الحصبة، وجدري الماء. تم تطبيق تحسين تكيفي للتباين (Adaptive Histogram Equalization) على القناة الحمراء فقط من الصور الملونة لتعزيز الخصائص اللونية المميزة مع تجنب تضخيم الضوضاء، بينما تم تجنب عمليات التنعيم للحفاظ على السمات المهمة.
تم استخدام طريقتين لاستخراج الخصائص من الصور. الأولى استخراج يدوي للخصائص بالاعتماد على مزيج من مصفوفة التشارك الرمادي (GLCM)، ولحظات اللون (Color Moments)، ونمط البتات المحلية (LBP)، حيث تم استخراج 24 سمة لكل صورة. أما الطريقة الثانية فكانت استخراج الخصائص باستخدام نماذج التعلم العميق عبر مكتبة Img2Vec المعتمدة على نماذج مدربة مسبقًا في PyTorch.
لتقييم الأداء، تم استخدام أسلوب K-Fold Cross Validation لضمان تقييم موثوق للنماذج. تمت مقارنة نموذجين للتصنيف هما: Random Forest و XGBoost. أظهر نموذج Random Forest باستخدام الخصائص اليدوية أداءً جيدًا، حيث حقق دقة إجمالية بلغت 95%، مع أفضل أداء لفئتي الحالة الطبيعية وجدري القرود، بينما سجلت فئتا الحصبة وجدري الماء أداءً أقل نسبيًا.