University Admission Chance Predictor
تفاصيل العمل
مشروع متقدم في مجال النمذجة التنبؤية (Predictive Modeling) يهدف إلى مساعدة الطلاب في تقدير فرص قبولهم في الجامعات العالمية. يعتمد المشروع على تحليل بيانات تاريخية لمئات الطلاب (Admission_Predict Dataset) واستخدام خوارزميات التعلم الآلي لربط المعايير الأكاديمية مثل (درجات GRE، TOEFL، معدل التخرج CGPA) باحتمالية القبول النهائية، مما يوفر رؤى دقيقة ومبنية على البيانات بدلاً من التخمين.
- الخطوات :
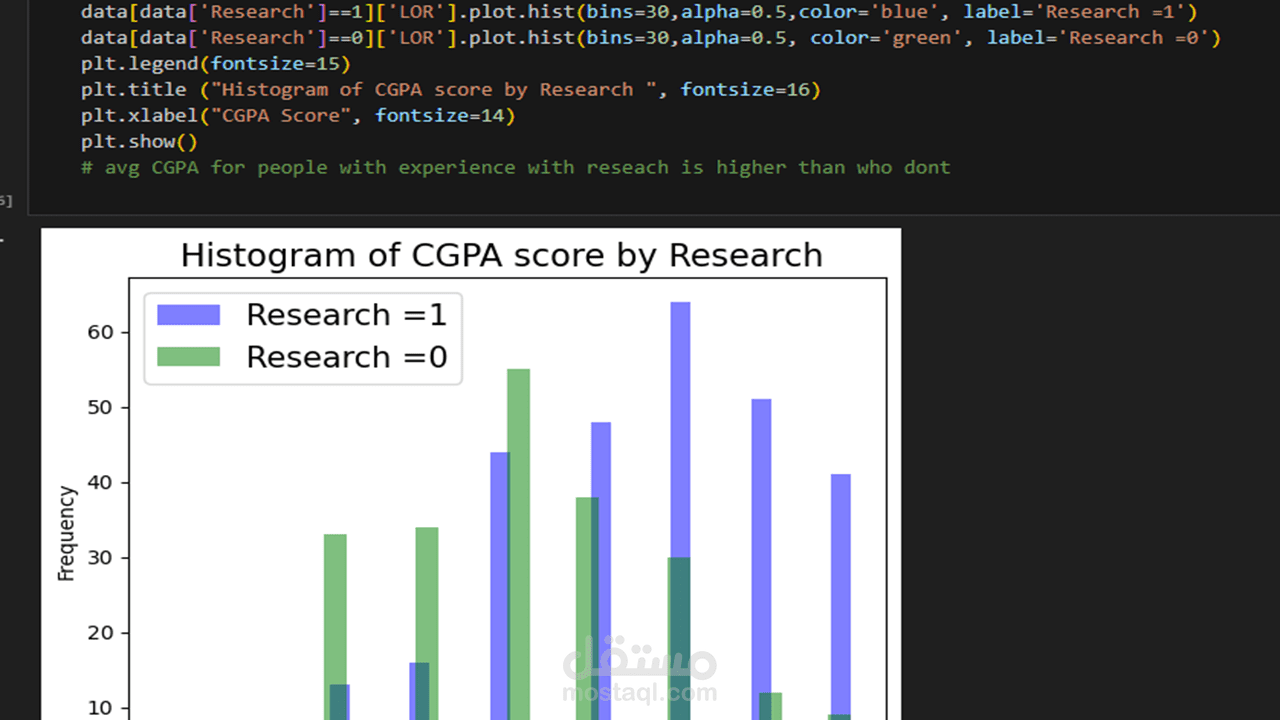
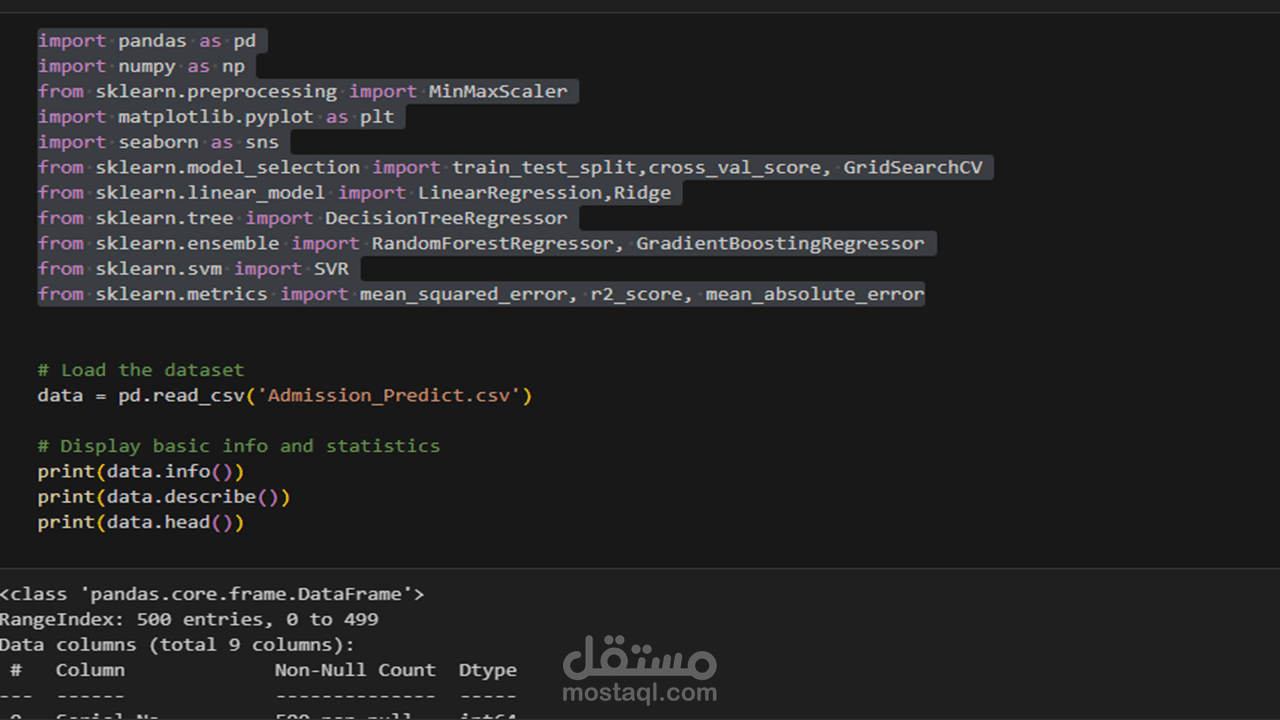
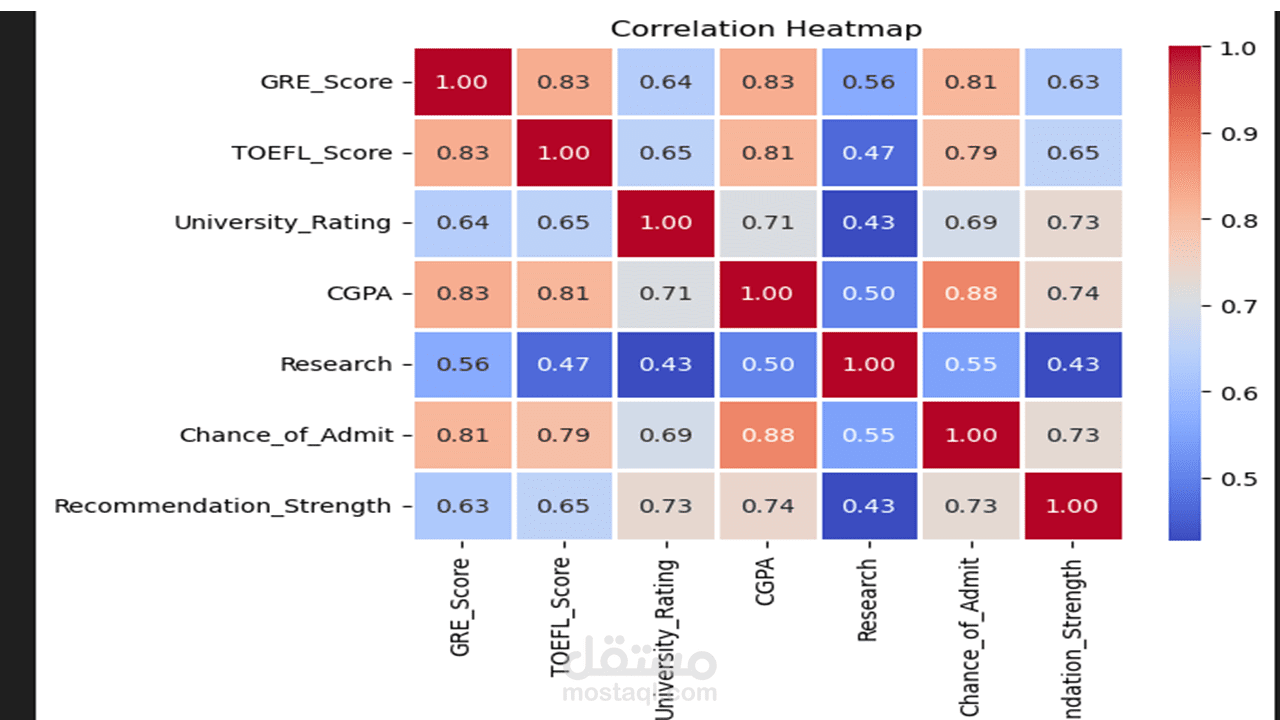
1 . استكشاف البيانات (Exploratory Data Analysis - EDA): تحليل مجموعة البيانات لفهم توزيع الدرجات، واكتشاف العلاقات (Correlations) بين المتغيرات المختلفة وفرص القبول.
2 . معالجة البيانات (Data Preprocessing): تنظيف البيانات من أي قيم مفقودة، وتنسيق الأعمدة، وعمل Feature Scaling لضمان أن جميع المعايير (مثل درجات الـ GRE العالية ومعدل الـ GPA الصغير) لها تأثير متوازن على النموذج.
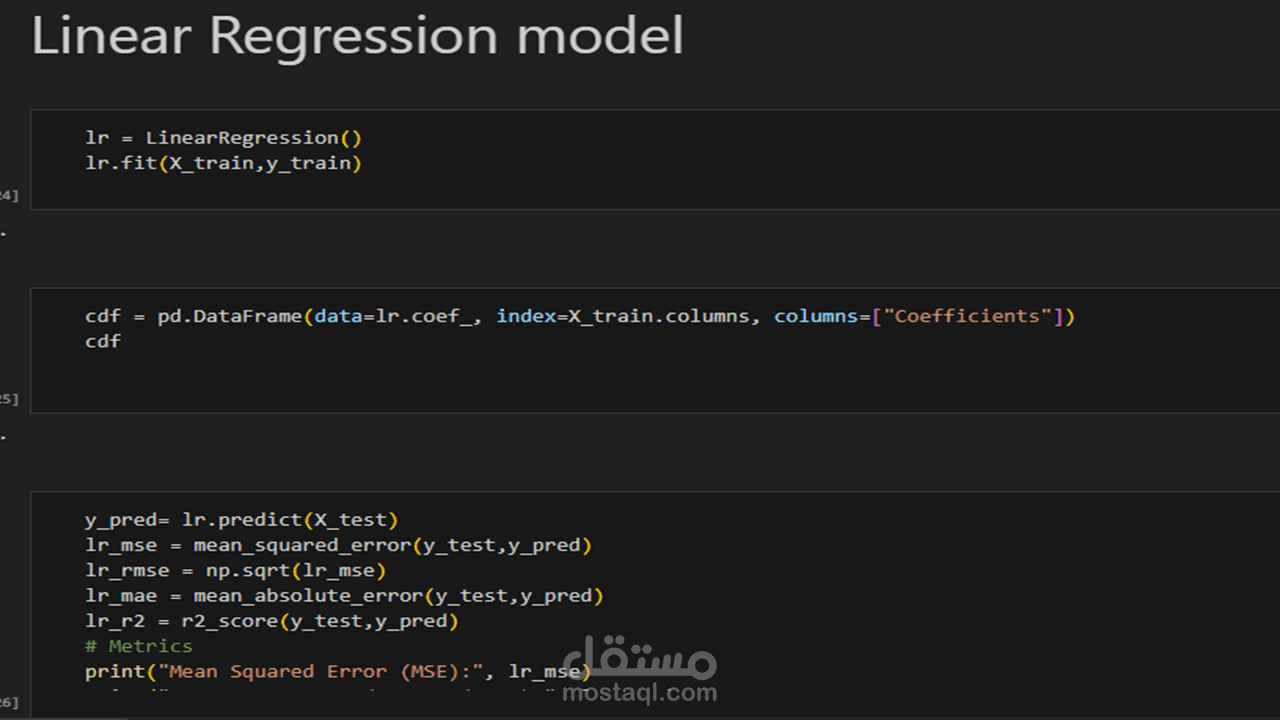
3 . بناء النموذج التنبئي (Model Development): اختيار وتدريب خوارزميات التعلم الآلي المناسبة (مثل Linear Regression أو Random Forest) لإنشاء معادلة قادرة على التنبؤ بنسبة القبول.
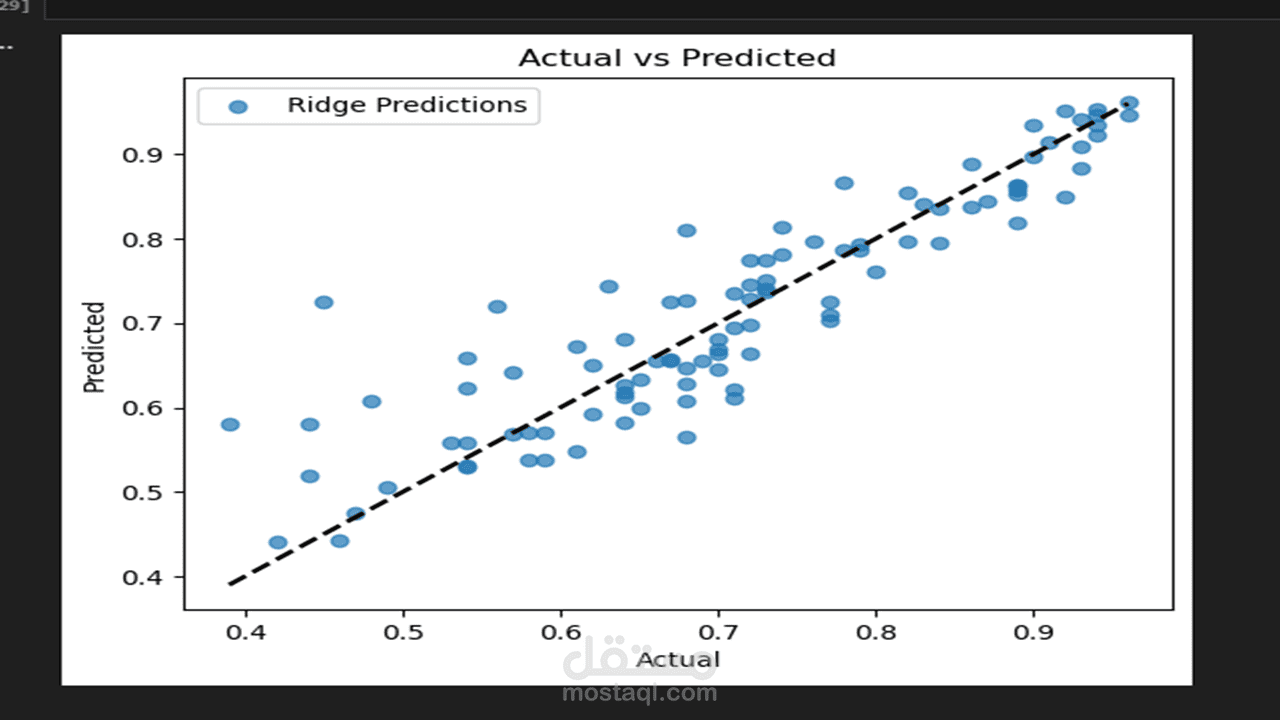
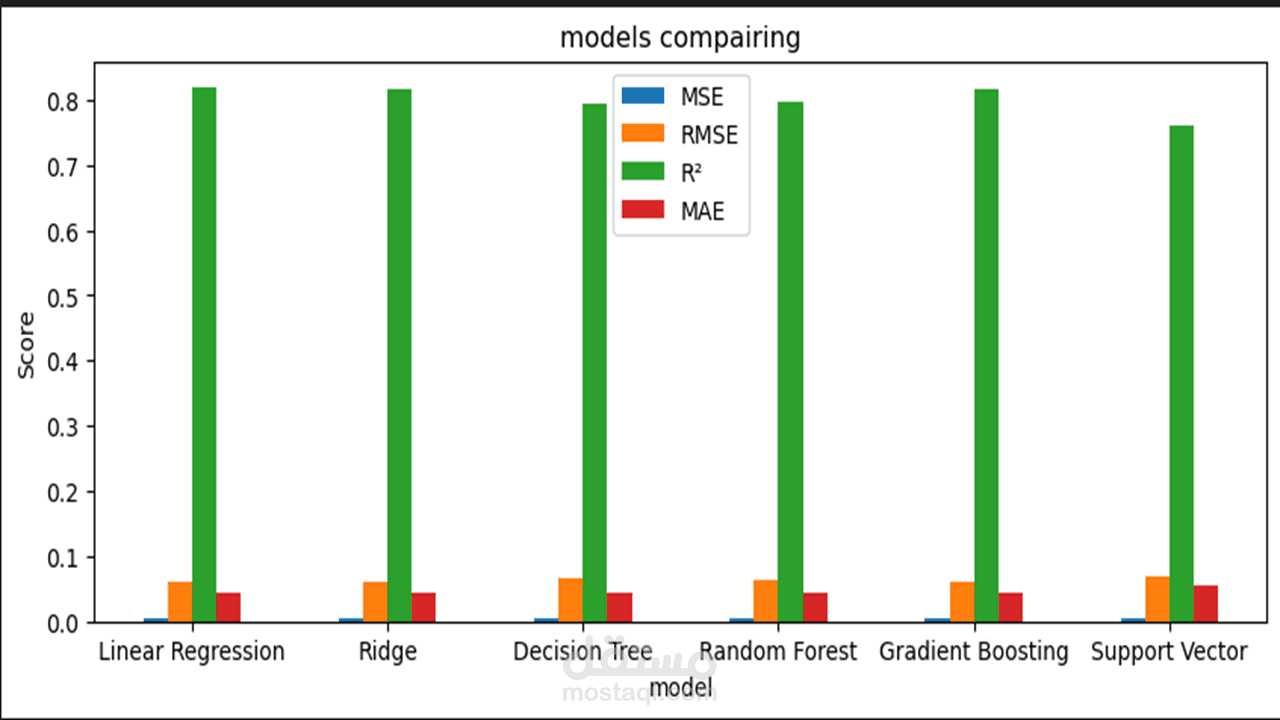
4 . تقييم الأداء (Model Evaluation): اختبار النموذج باستخدام بيانات لم يراها من قبل وقياس دقته باستخدام معايير إحصائية مثل (R-squared) و (MAE) لضمان جودة التوقعات.
5 . تحليل الأهمية (Feature Importance): تحديد العوامل الأكثر تأثيراً في عملية القبول لمساعدة الطلاب على التركيز على تحسين مهارات/درجات محددة.
- الادوات :
- المكتبات الأساسية: Pandas و NumPy لمعالجة البيانات الضخمة والجداول الرياضية.
- المعالجة المسبقة: MinMaxScaler لتوحيد مقاييس البيانات (Normalization) لضمان كفاءة الخوارزميات الحساسة مثل SVR.
- تصوير البيانات: Matplotlib و Seaborn لرسم العلاقات الإحصائية وتوزيع البيانات.
- الخوارزميات التنبئية: مجموعة متنوعة من نماذج الانحدار (Regression Models):
- Linear & Ridge Regression (نماذج خطية).
- Decision Tree & Random Forest (نماذج تعتمد على الأشجار).
- Gradient Boosting (لرفع دقة التنبؤ).
- SVR (Support Vector Regression) (للتعامل مع العلاقات المعقدة).
- تقييم وتحسين الأداء: * GridSearchCV لضبط أفضل "الإعدادات" (Hyperparameters) للنماذج.
- Cross-validation للتأكد من استقرار النتائج.
- مقاييس الأداء: R2 Score, MSE, MAE
- المميزات :
- نتائج مبنية على البيانات: يوفر توقعات دقيقة بناءً على أنماط قبول حقيقية من كاجل (Kaggle).
- تغطية شاملة للمقاييس: يأخذ في الاعتبار 7 معايير أساسية (GRE, TOEFL, University Rating, SOP, LOR, CGPA, Research).
- سهولة التخصيص: يمكن تطوير النظام لاستقبال مدخلات المستخدم وتزويده بنتيجة فورية.
- رؤى تحليلية: لا يقدم رقماً فقط، بل يوضح مدى تأثير كل عامل أكاديمي على النتيجة النهائية.