AI-Driven Sentiment & Topic Classifier for Customer Reviews
تفاصيل العمل
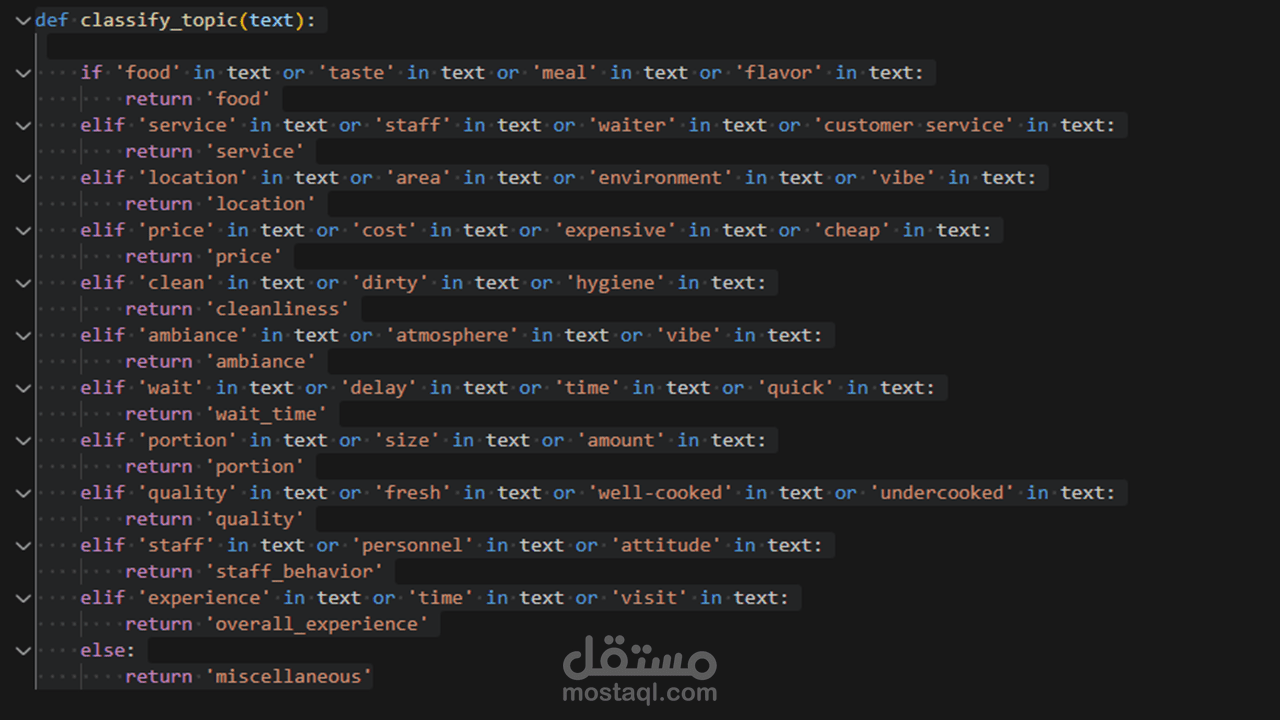
تطوير نموذج ذكاء اصطناعي يعتمد على معالجة اللغات الطبيعية (NLP) لتحليل وتقسيم مراجعات العملاء (Reviews) إلى فئات محددة بدقة. يقوم النظام بفحص النصوص وتصنيفها تلقائياً إلى (الجودة، السعر، الخدمة، وقت الانتظار، وغيرها)، مما يسهل على الشركات فهم نقاط القوة والضعف في خدماتها دون الحاجة لقراءة آلاف التعليقات يدوياً.
- خطوات التنفيذ :
1 . تحديد الكلمات المفتاحية (Keyword Mapping): بناء قاموس شامل من الكلمات والدلالات التي تميز كل قطاع في تجربة العميل.
2 . بناء خوارزمية الفرز (Classification Logic): تطوير محرك برمجي يستخدم الشروط المنطقية (Conditional Logic) لمعالجة النصوص وتصنيفها لحظياً.
3 . اختبار تدفق المنطق (Logic Flow Testing): فحص كفاءة الخوارزمية في التعامل مع التعليقات المتنوعة وضمان دقة توجيه كل نص للفئة الصحيحة.
4 . معالجة الاستثناءات (Edge Cases Handling): برمجة فئة "متنوع - Miscellaneous" للتعامل مع النصوص التي لا تقع ضمن الفئات الأساسية لضمان استمرارية عمل النظام.
- الادوات :
1 . Pandas: لمعالجة البيانات وتنظيمها في جداول (DataFrames).
2 . NLTK (Natural Language Toolkit): المكتبة الأساسية لمعالجة النصوص، واستخدمتِ منها:
3 . Tokenization: لتقسيم النصوص إلى كلمات فردية.
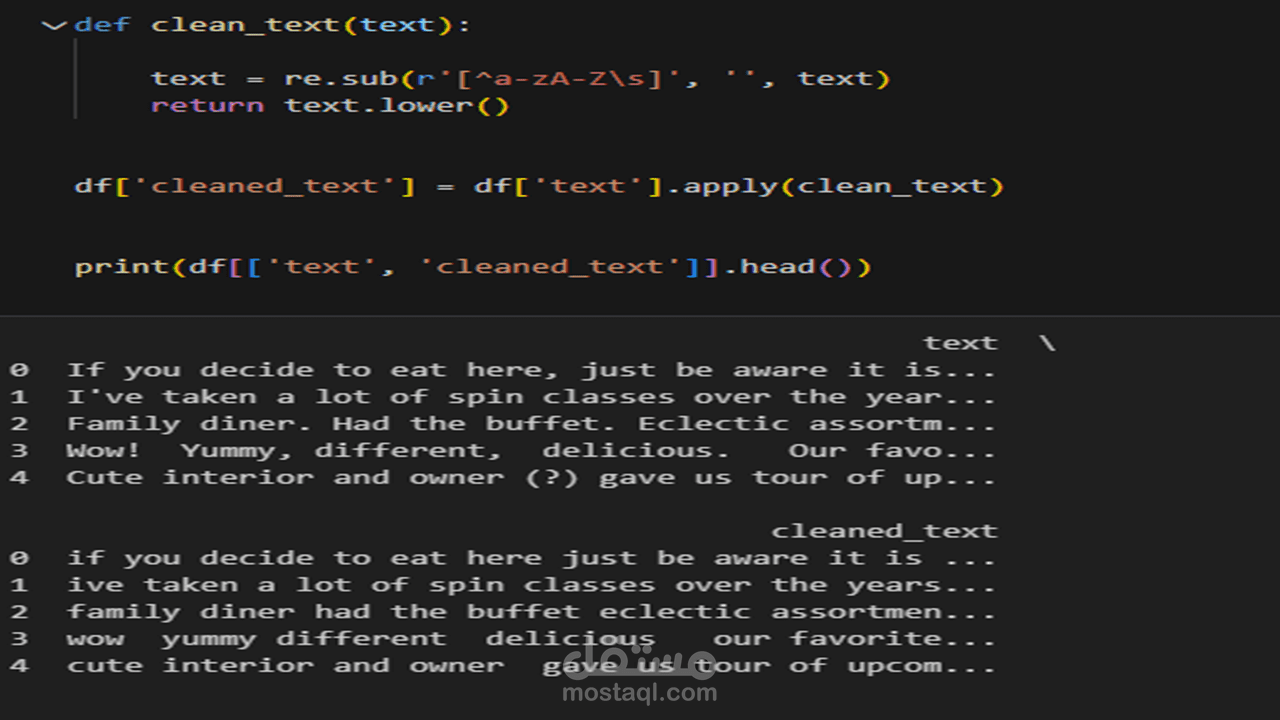
4 . Stopwords Removal: لحذف الكلمات التي ليس لها قيمة تحليلية (مثل: the, and, in).
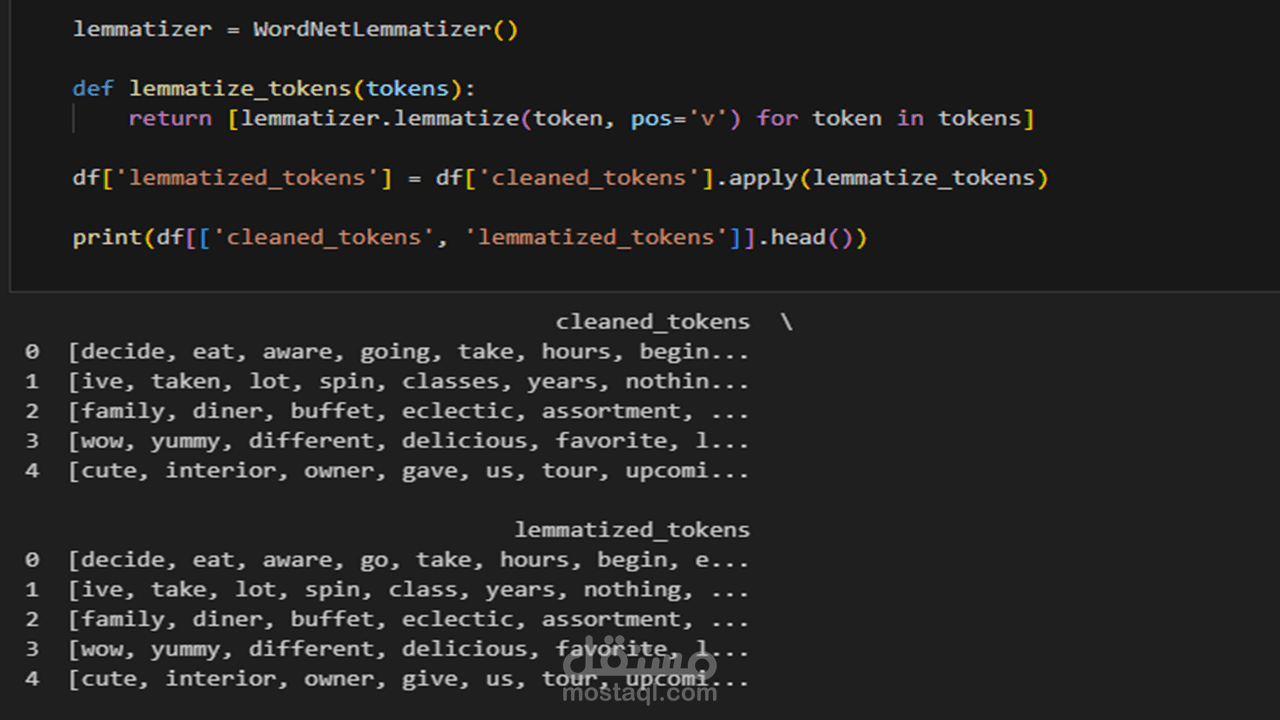
Lemmatization: لإرجاع الكلمات إلى أصلها (مثلاً: "waiting" تصبح "wait").
5 . Scikit-learn (CountVectorizer): لتحويل النصوص إلى مصفوفات رقمية (Vectorization) تمهيداً لتحليلها برمجياً.
6 . Regex (re): لتنظيف النصوص من الرموز والروابط وأي شوائب برمجية.
- المميزات :
- دقة لغوية عالية: بفضل استخدام الـ Lemmatization، النظام بيفهم إن "waiter" و "waiting" ليهم علاقة ببعض.
- تحليل السياق (N-grams): القدرة على فهم التعبيرات المكونة من كلمتين أو أكثر وليس فقط كلمات منفردة.
- معالجة ضخمة للبيانات: بفضل Pandas، النظام يقدر يعالج آلاف التقييمات في ثوانٍ.