استخراج وأرشفة محتوى المقالات التقنية (NCMH) بصيغة JSON و HTML
تفاصيل العمل
طبيعة المشروع: مشروع متقدم لاستخراج المحتوى الكامل للمقالات من منصة NCMH، مع الحفاظ على التنسيق الهيكلي لكل مقال. تطلب العمل دقة عالية في سحب النصوص والروابط بصيغ برمجية محددة.
المهام المنفذة:
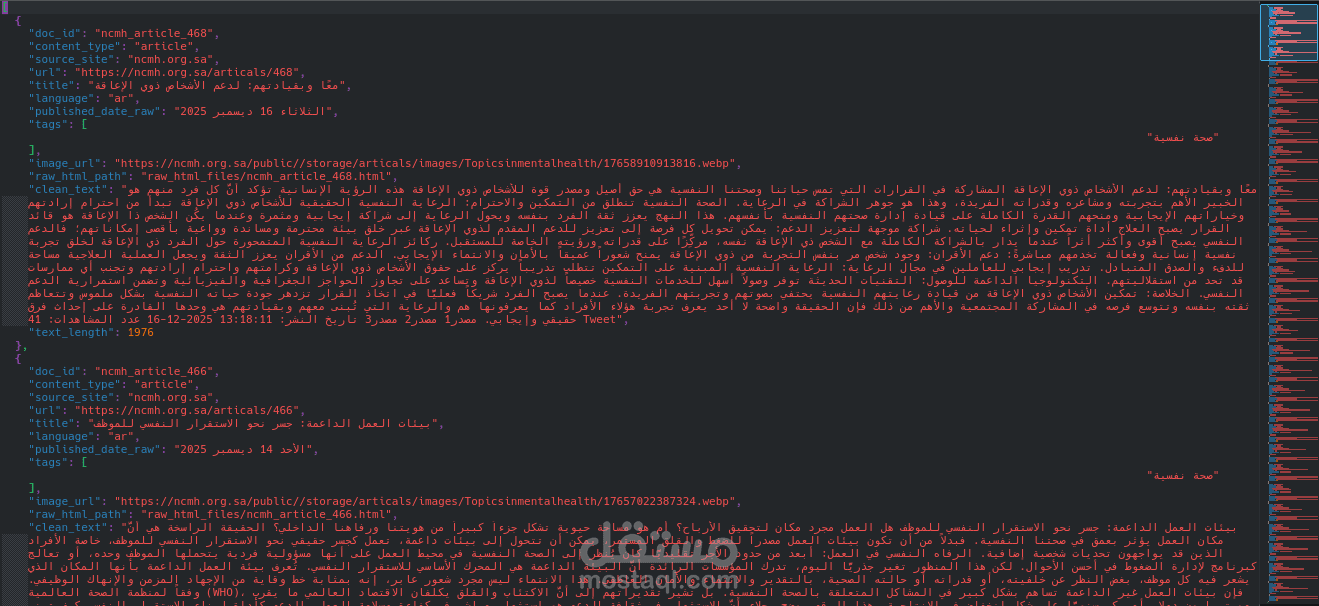
هيكلة البيانات: قمت بسحب البيانات وتحويلها إلى صيغة JSON لسهولة معالجتها برمجياً، وصيغة HTML للحفاظ على تنسيق المقالات الأصلي.
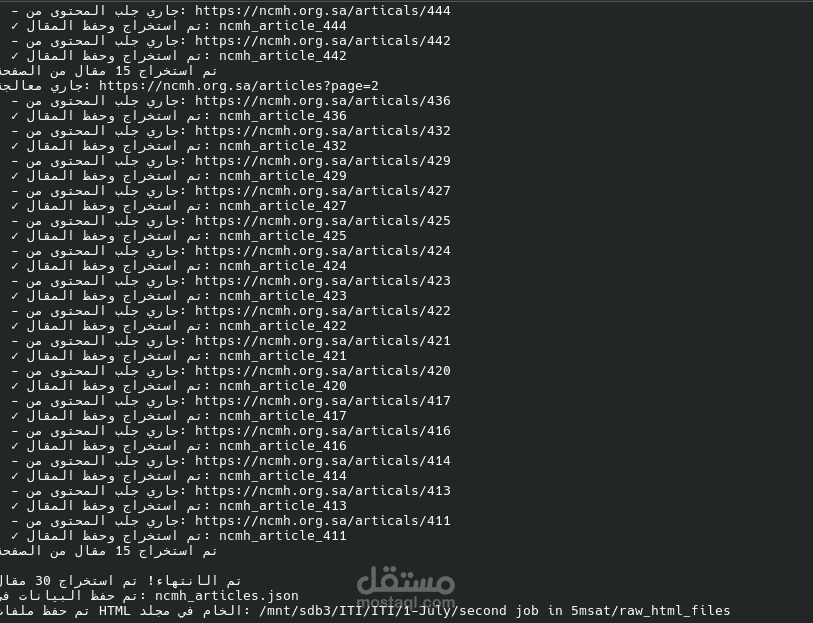
التعامل مع المحتوى الضخم: بناء سكريبت قادر على تصفح أقسام الموقع واستخراج المقالات بشكل آلي وشامل.
تنظيف البيانات (Data Cleaning): التأكد من خلو المحتوى المستخرج من الأكواد البرمجية الزائدة أو الإعلانات لضمان "نظافة" البيانات المسلمة.
التقنيات المستخدمة:
Python (المحرك الأساسي للعملية).
BeautifulSoup / Scrapy للتعامل مع بنية الـ HTML المعقدة.
JSON library لتنظيم وتصدير البيانات المهيكلة.
النتائج:
تسليم كامل المحتوى المطلوب بجودة احترافية.
الحصول على تقييم 5 نجوم من العميل (المملكة العربية السعودية)، مع الإشادة بالسرعة والدقة.