Sentiment Analysis Projects (نظام تحليل المشاعر لمراجعات النص باستخدام التعلم الآلي)
تفاصيل العمل


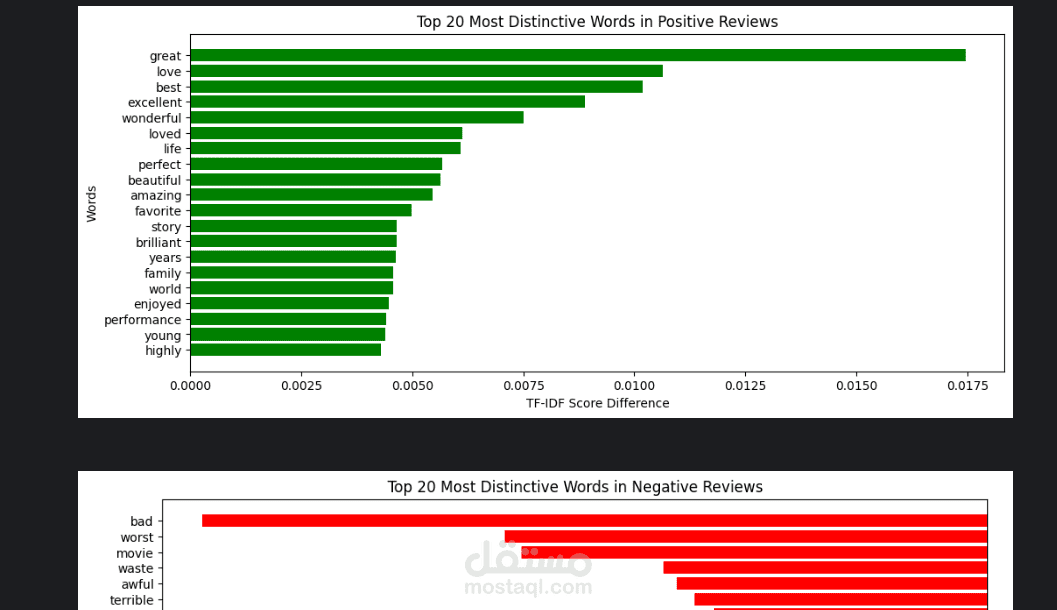
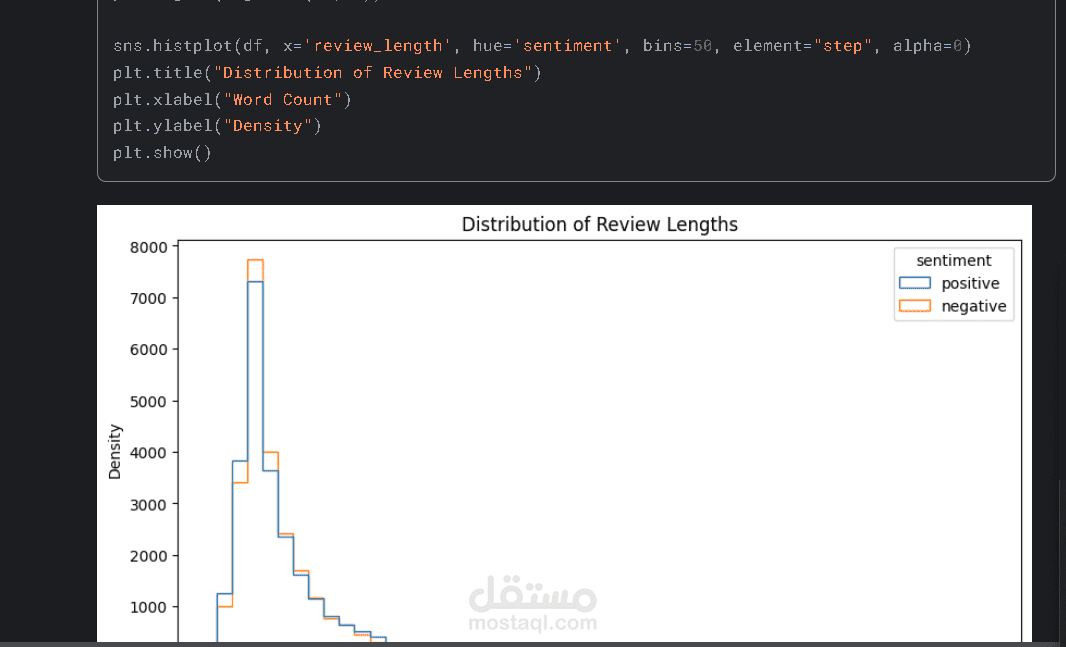
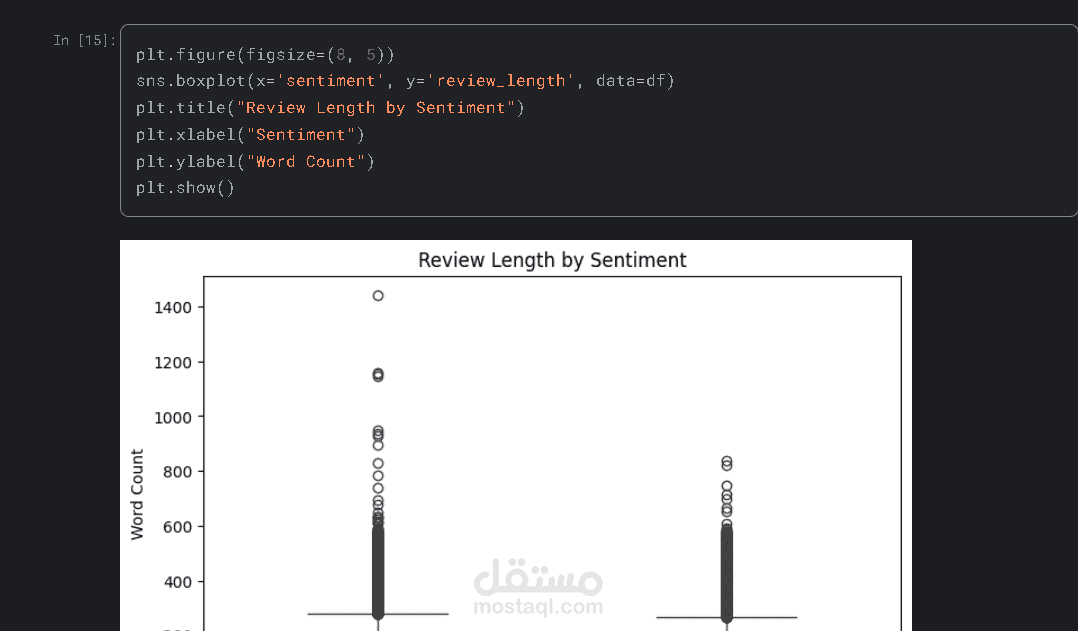
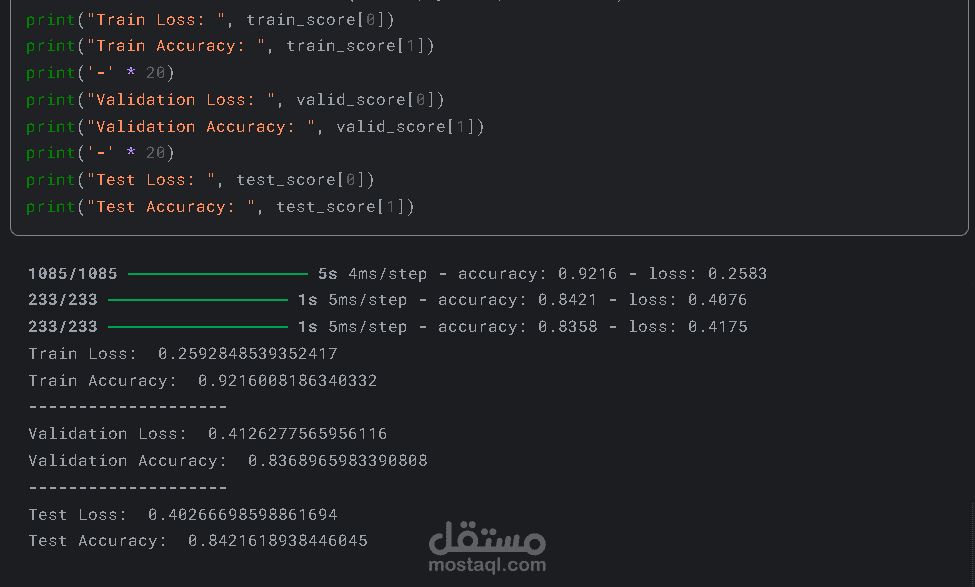
وصف المشروع:
قمت بتطوير نموذج ذكي لمعالجة اللغات الطبيعية (NLP) يهدف إلى تحليل النصوص ومراجعات المستخدمين (Reviews) وتصنيفها آلياً إلى مشاعر إيجابية أو سلبية، مما يساعد الشركات في فهم آراء العملاء بشكل دقيق وسريع.
تفاصيل تنفيذ المشروع:
الأدوات والتقنيات المستخدمة:
لغة البرمجة Python.
مكتبات معالجة اللغات الطبيعية NLTK و Scikit-learn.
مكتبات التعلم العميق TensorFlow / Keras (لبناء النماذج المتقدمة مثل LSTM).
مكتبات Pandas و NumPy لمعالجة البيانات النصية.
نوع البيانات:
مجموعة بيانات نصية (Text Dataset) تحتوي على آلاف المراجعات والآراء المكتوبة.
البيانات مصنفة (Labeled Data) إلى فئات شعورية (إيجابي / سلبي).
تحليل ومعالجة البيانات:
تنظيف النصوص (Text Cleaning) بإزالة الرموز، التشكيل، والكلمات الزائدة (Stop Words).
تطبيق تقنيات المعالجة المسبقة مثل التوحيد (Stemming/Lemmatization) لتقليل تشتت المفردات.
تحويل النصوص إلى أرقام (Vectorization) باستخدام تقنيات مثل TF-IDF أو Word Embeddings لتفهمها الآلة.
Tokenization
تجهيز البيانات للتدريب والاختبار
آلية عمل النموذج:
تحويل النصوص إلى تمثيل عددي قابل للتعلم
استخدام خوارزميات تعلم الآلة (Machine Learning) للتصنيف بناءً على تكرار الكلمات وسياقها.
تدريب النموذج للتعرف على الأنماط اللغوية التي تدل على الرضا (الإيجابية) أو الاستياء (السلبية).
تحسين دقة النموذج من خلال ضبط المعاملات (Hyperparameter Tuning).
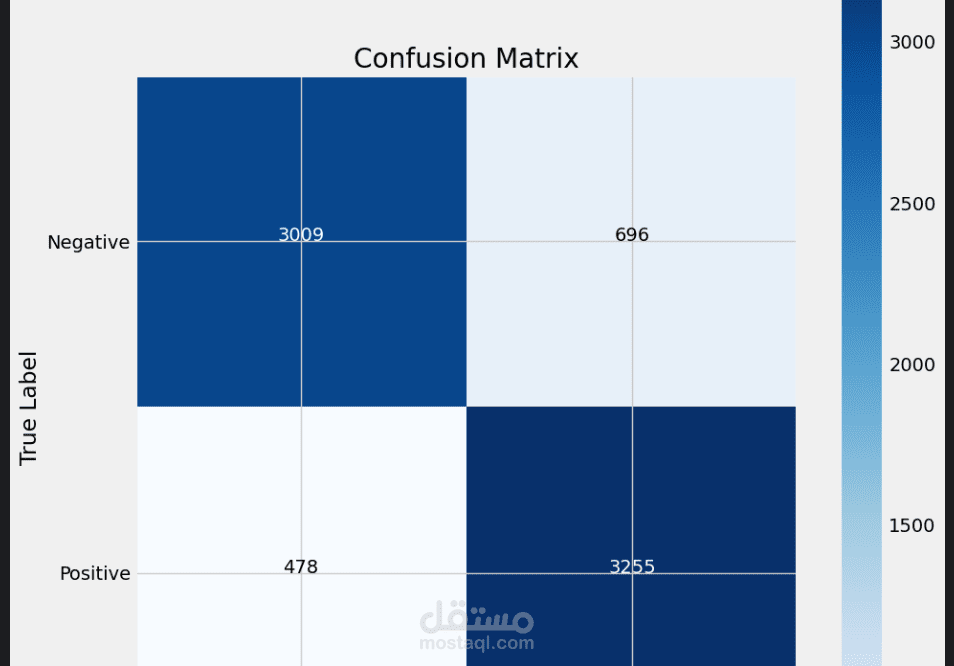
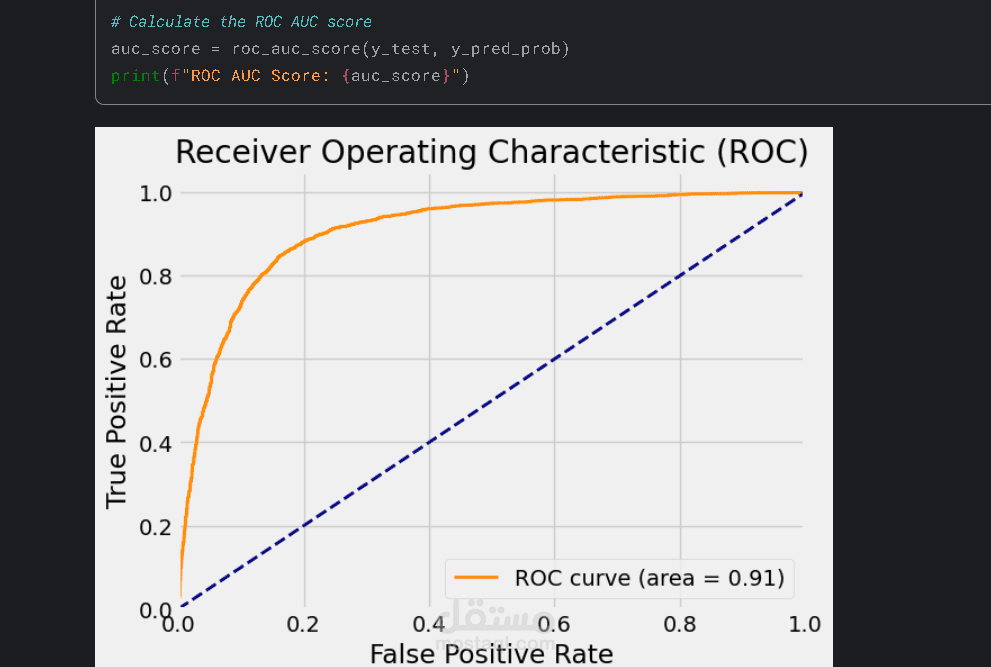
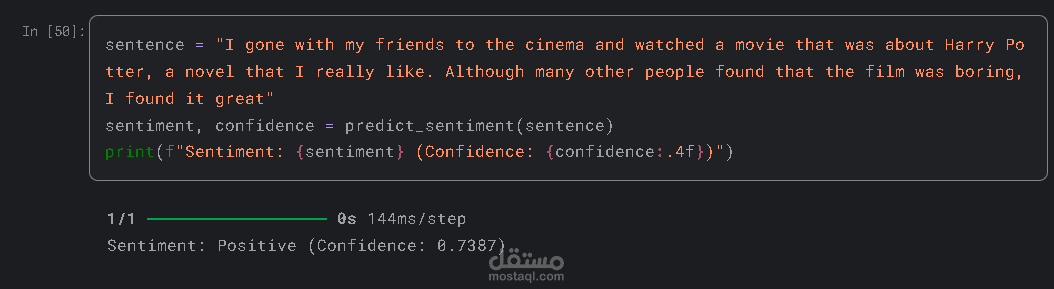
نتائج المشروع:
تحقيق دقة عالية في تصنيف المشاعر واكتشاف نبرة النص.
القدرة على معالجة كميات ضخمة من النصوص في وقت قياسي، مما يجعله أداة فعالة لتحليل آراء الجمهور.