Yelp Sentiment Analysis – مقارنة بين النموذج التقليدي و Transformer
تفاصيل العمل

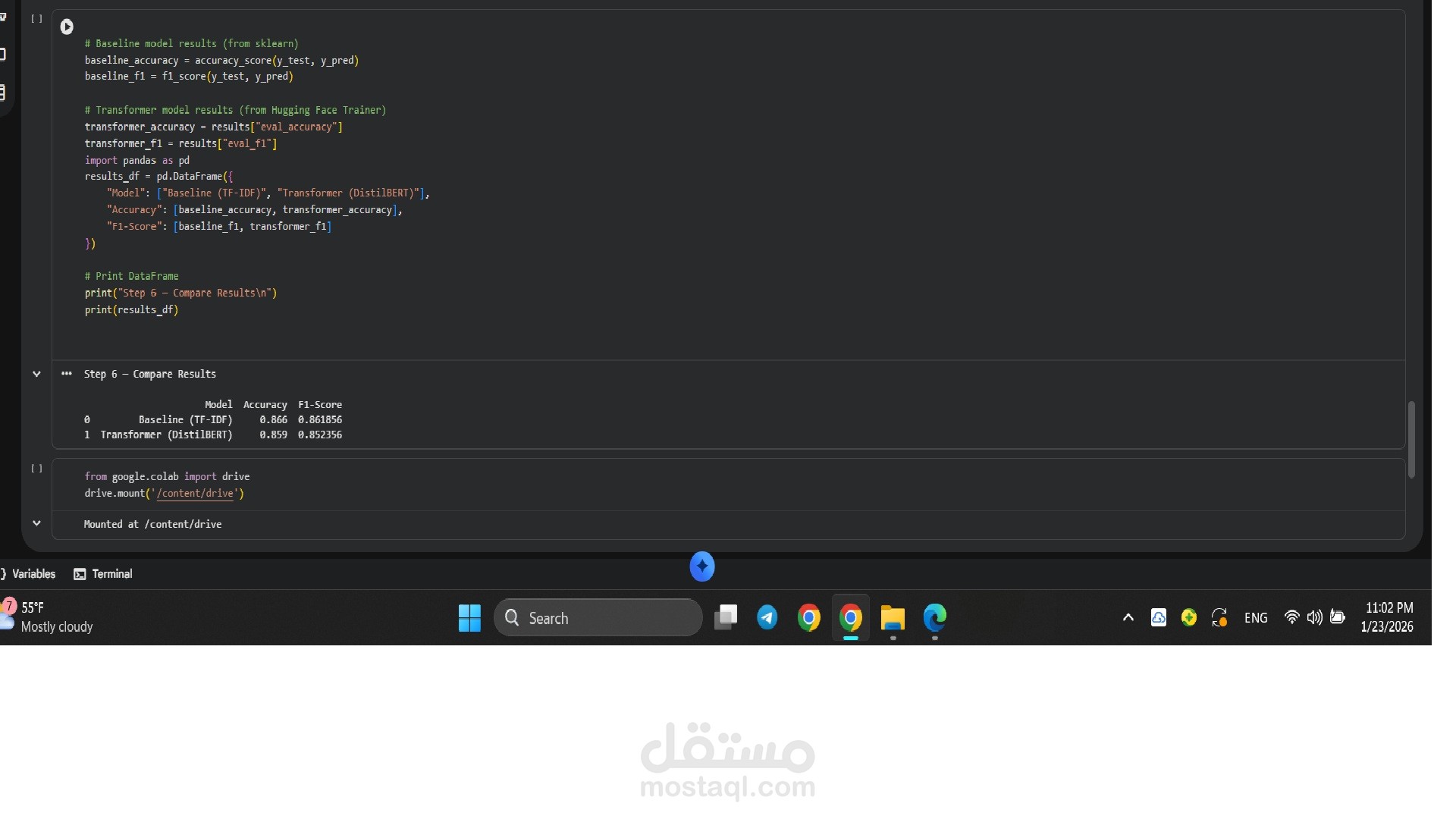
في هذا المشروع تم تنفيذ نظام لتحليل المشاعر (Sentiment Analysis) يهدف إلى فهم آراء العملاء تلقائيًا من خلال مراجعاتهم النصية، مع مقارنة منهجيتين مختلفتين في بناء نماذج الذكاء الاصطناعي لمعرفة أيهما يقدّم أداءً أفضل في سيناريوهات الأعمال الحقيقية.
المشروع يعتمد على Yelp Polarity Dataset، وهي مجموعة بيانات معروفة تحتوي على مراجعات عملاء مصنّفة إلى مشاعر إيجابية وسلبية،
وتُستخدم على نطاق واسع في أبحاث ومع تطبيقات معالجة اللغة الطبيعية (NLP).
هدف المشروع:
تحليل مشاعر مراجعات العملاء بشكل آلي
مقارنة أداء النماذج التقليدية مقابل نماذج Transformer الحديثة
الوصول إلى توصية تقنية مبنية على النتائج الفعلية، وليس الافتراضات
منهجية العمل
النموذج التقليدي (Baseline Model)
تم بناء نموذج أساسي يعتمد على:
TF-IDF لتحويل النصوص إلى تمثيل رقمي
Logistic Regression كخوارزمية تصنيف
هذا النموذج يُستخدم كنقطة مرجعية لقياس الأداء، ويتميز بالبساطة وسرعة التنفيذ.
نموذج Transformer (Fine-Tuned DistilBERT)
تم استخدام نموذج DistilBERT المدرب مسبقًا، ثم:
إعادة تدريبه (Fine-Tuning) على بيانات Yelp
الاستفادة من تمثيل السياق الكامل للنصوص
تحسين دقة الفهم اللغوي للمراجعات الطويلة والمعقّدة
خطوات التنفيذ:
تحميل وتجهيز البيانات باستخدام مكتبة Hugging Face Datasets
تقسيم البيانات إلى تدريب واختبار
تدريب كل نموذج بشكل منفصل
تقييم الأداء باستخدام:
Accuracy
F1-Score
مقارنة النتائج وتحليل الفروق بين النموذجين
النتائج:
النموذج المعتمد على Transformer (DistilBERT) أظهر أداءً أعلى في فهم سياق النصوص
النموذج التقليدي كان أسرع وأخف، لكنه أقل دقة في بعض الحالات
تم الخروج بتوصية واضحة حول متى يُفضّل استخدام كل نموذج حسب احتياجات المشروع
الأدوات والتقنيات المستخدمة:
Python
Google Colab
Hugging Face (Transformers – Datasets – Trainer API)
Scikit-learn
Natural Language Processing (NLP)