استخراج البيانات من المواقع Web Scraping,Python,Automation
تفاصيل العمل

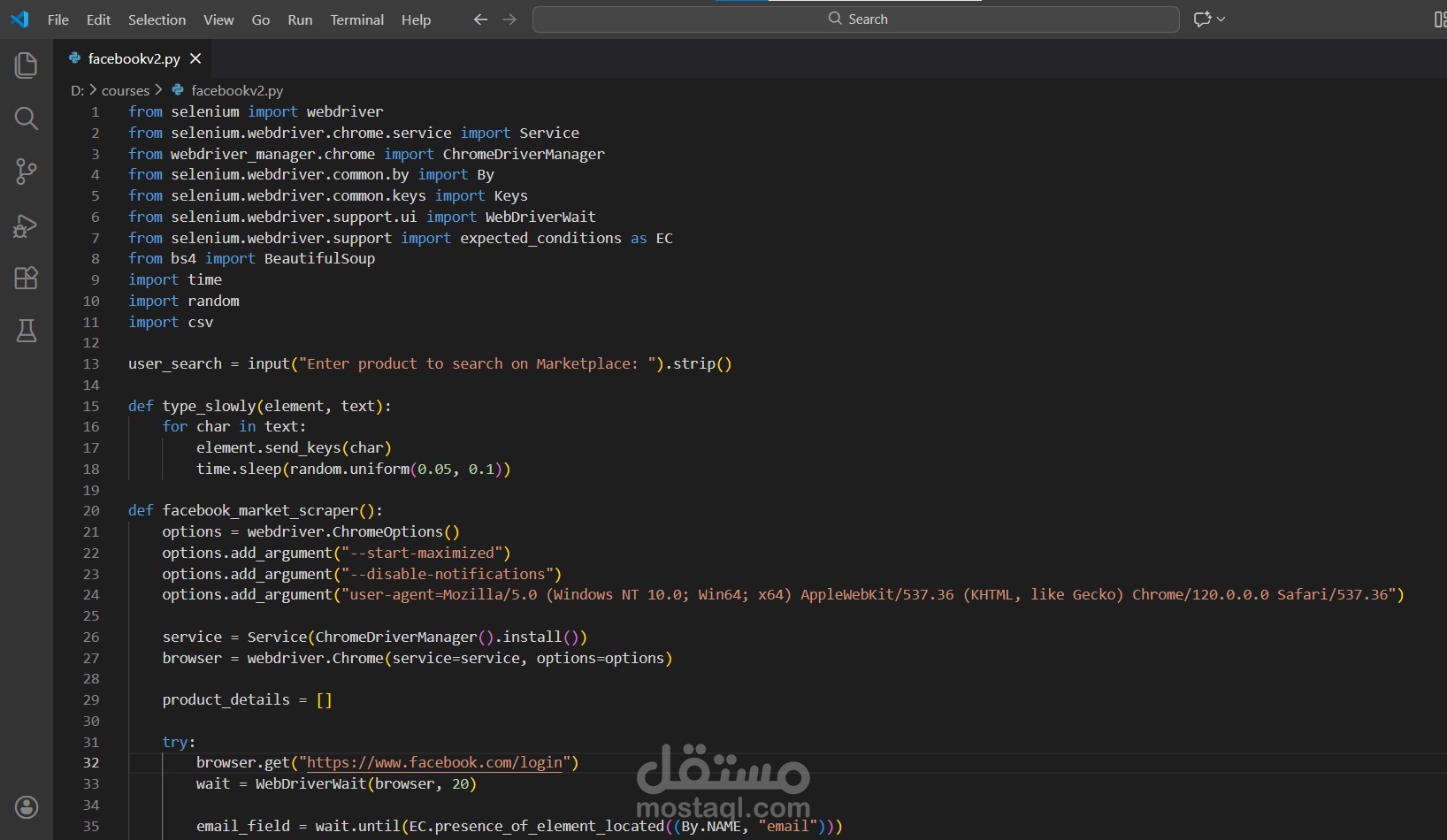
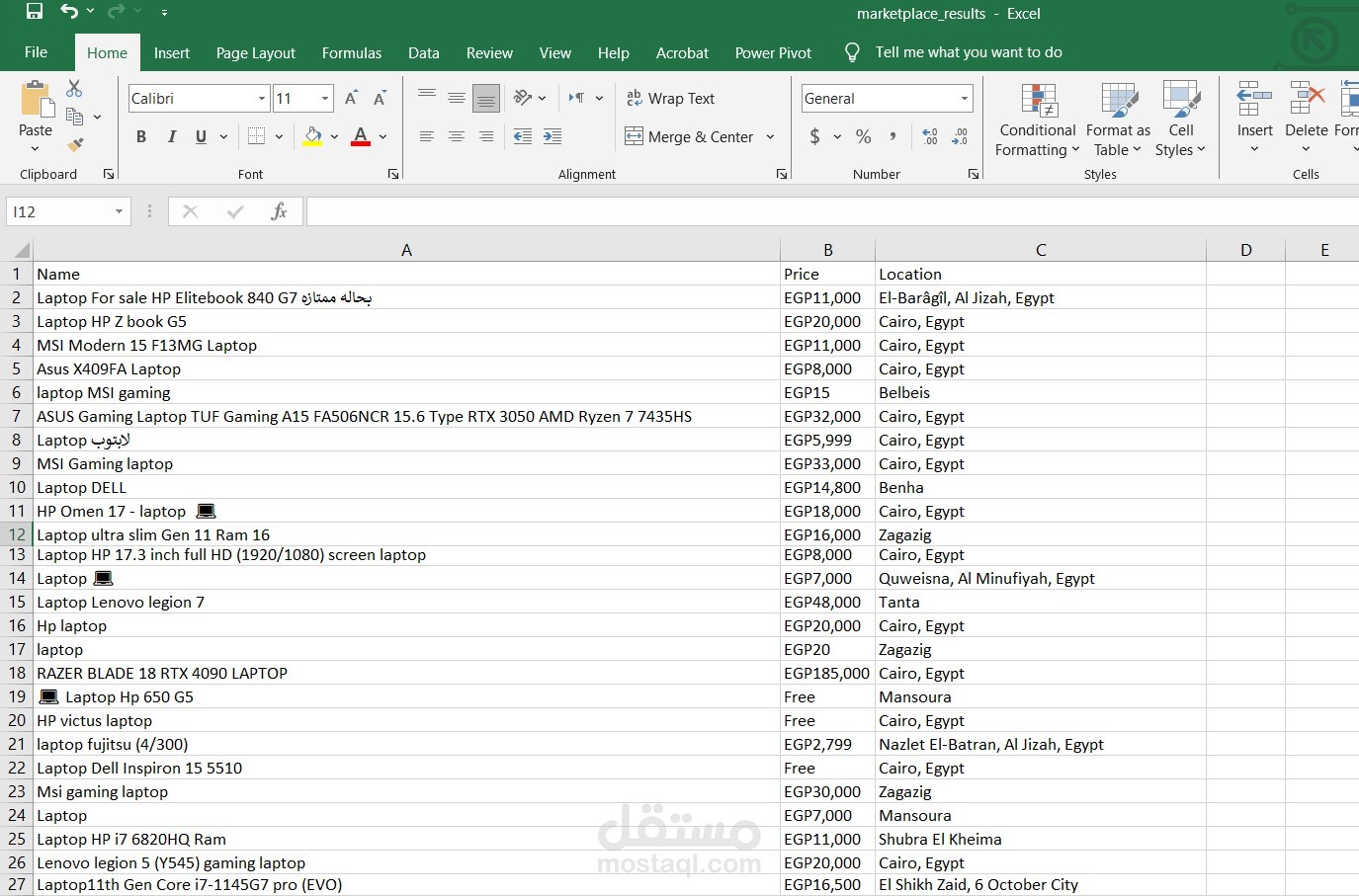
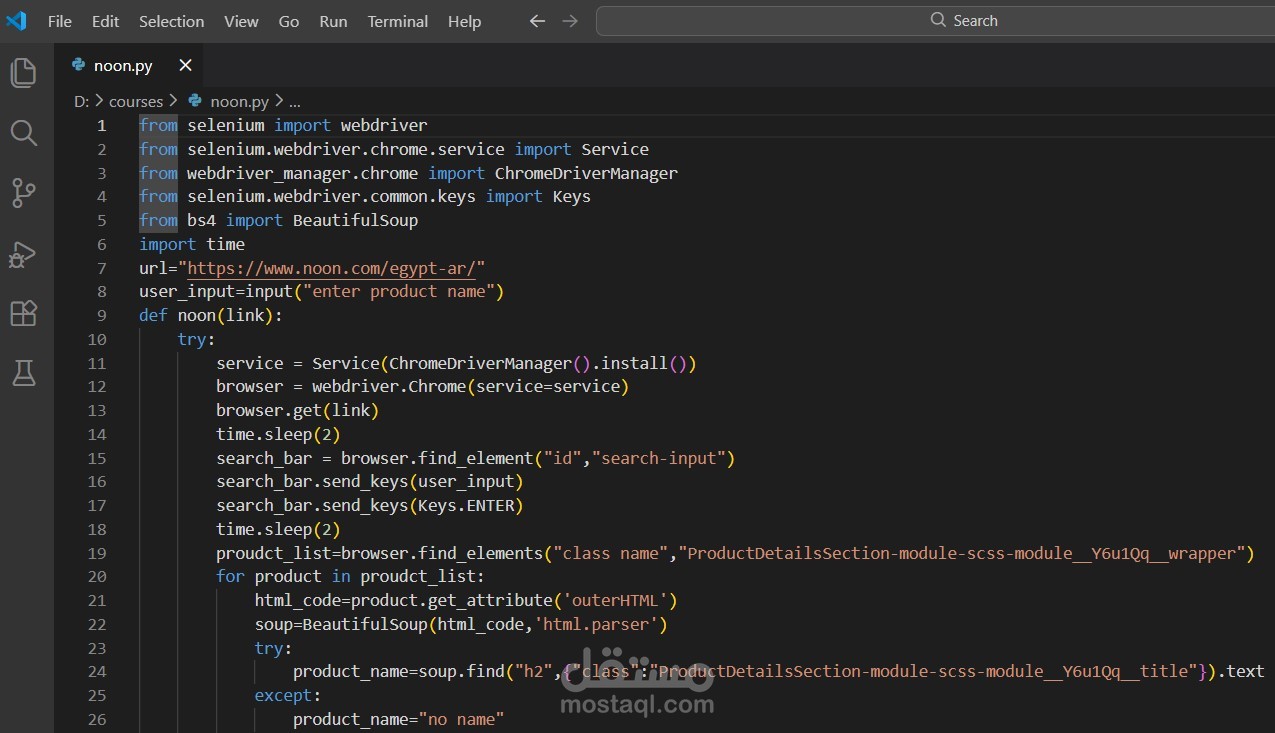
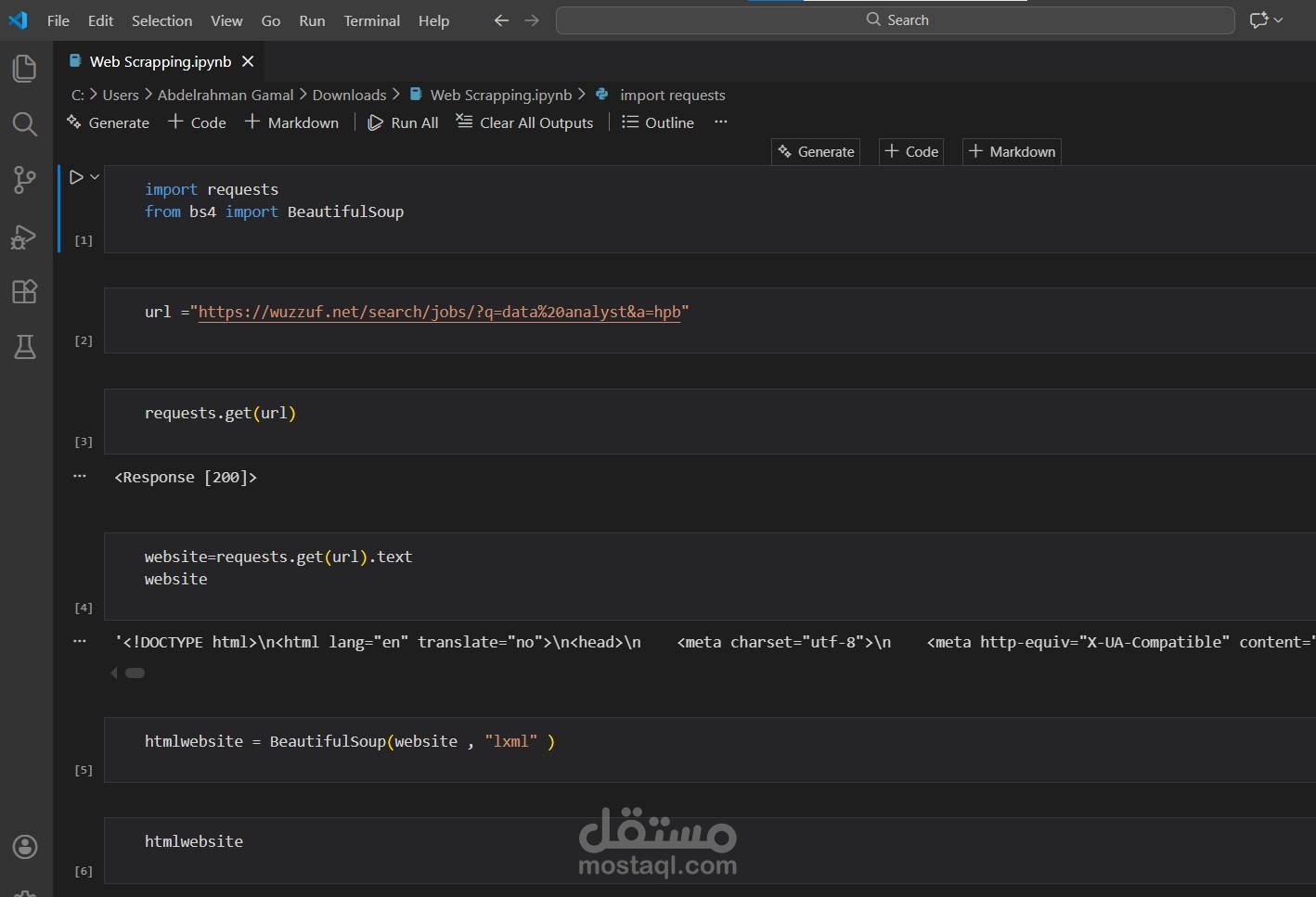
استخراج البيانات الاحترافي من المواقع | Web Scraping | Python | Selenium | BeautifulSoup
أستخرج البيانات من أي موقع بدقة عالية وأحوّلها إلى ملفات جاهزة للتحليل باستخدام أحدث تقنيات Web Scraping.
ماذا أقدم؟
Scraping شامل: Static + Dynamic websites مع JavaScript rendering
تقنيات متقدمة: BeautifulSoup +Requests+ Selenium + Scrapy حسب احتياجك
Anti-Detection: User-Agent rotation + Random delays + Proxy support
Authentication handling: Login automation + Cookies + Session management
Pagination complete: Infinite scroll + Multi-page navigation
Error handling قوي: Retry logic + Timeout handling + Logging
مناسب لـ: E-commerce tracking، Social media analytics، Job listings، Real estate data، Market research
مميزات الخدمة
كود Production-ready مع PEP 8 compliance
Anti-Detection متقدم: User-Agent rotation + Delays
Error Handling شامل: Retry logic + Timeout + Logging
Config-driven architecture: سهل التخصيص بدون تعديل الكود
Multiple export formats: CSV + JSON + Excel + SQL
Documentation احترافية: Installation + Usage + Troubleshooting
Authentication handling: Login automation + Session management
Pagination complete: Infinite scroll + Multi-page
Clean data delivery: معالجة وتنظيف البيانات
Scheduling ready: جاهز للتشغيل الآلي
Rate limiting ذكي: تجنب حظر IP
Proxy integration: دعم Rotating proxies
Modular functions: Reusable + Easy maintenance
GitHub repository: كود منظم مع Version control
التسليم :
ملف Excel أو CSV منسق
يحتوي على جميع البيانات التي تم استخراجها من الموقع، مرتبة في أعمدة واضحة
تقرير نصي مبسط
ملف نصي يحتوي على وصف الحقول التي تم استخراجها وعدد السجلات وملخص عن عملية الاستخراج.