housing project
تفاصيل العمل
صف المشروع: قمت في هذا المشروع بتنفيذ دورة حياة تحليل البيانات (Data Science Lifecycle) كاملة على مجموعة بيانات الإسكان في كاليفورنيا، بهدف بناء نموذج تعلم آلي (Machine Learning) قادر على التنبؤ بالقيمة المتوسطة للمنازل بدقة بناءً على مجموعة من الخصائص الجغرافية والديموغرافية.
الخطوات والمهارات المنفذة:
استكشاف وتحليل البيانات (EDA):
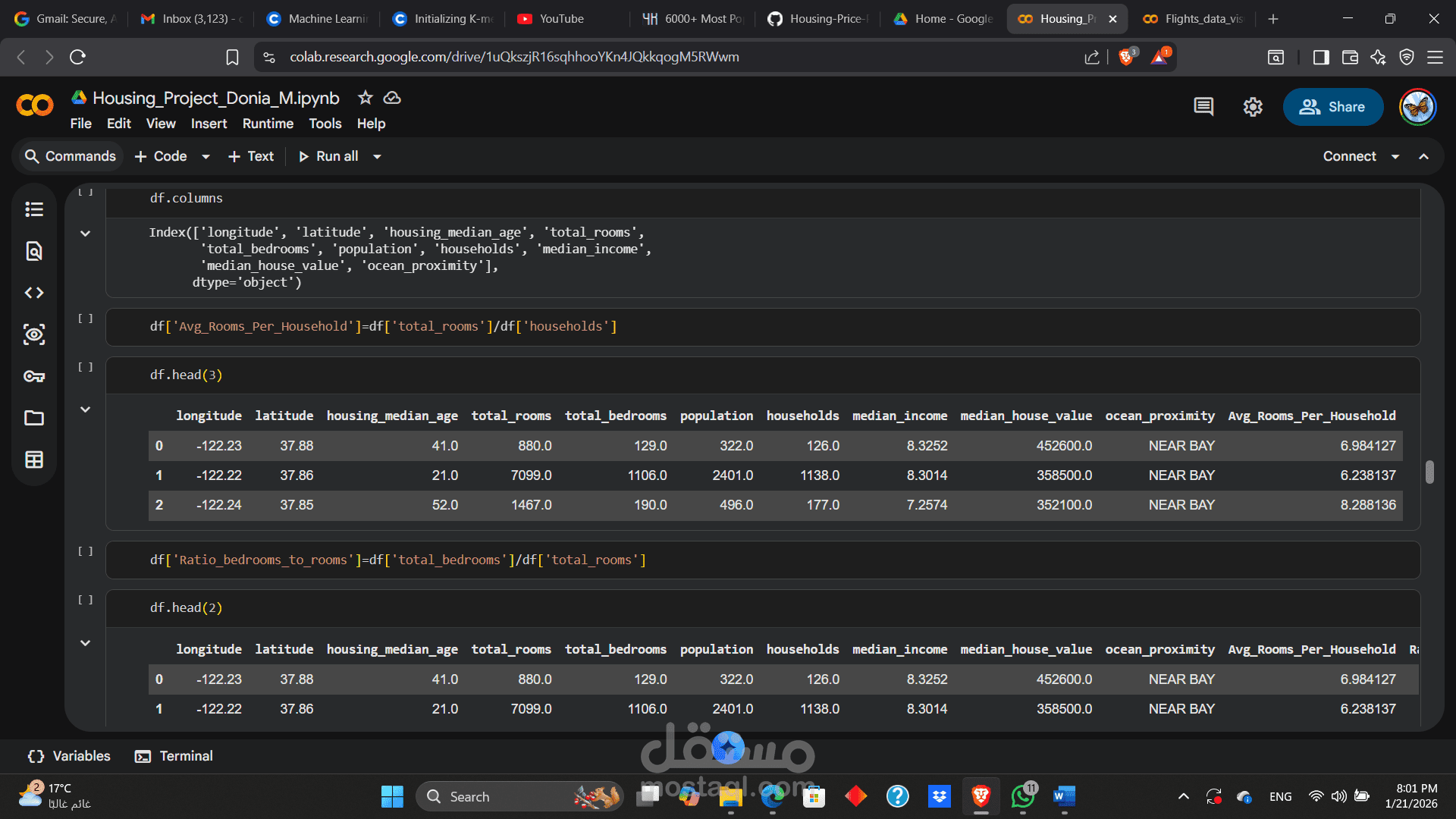
استيراد والتعامل مع البيانات الضخمة باستخدام مكتبة Pandas و NumPy.
فهم التوزيع الإحصائي للبيانات باستخدام describe() و info().
تحليل الخصائص المختلفة مثل (الدخل المتوسط، عدد الغرف، القرب من المحيط، والموقع الجغرافي).
معالجة البيانات (Data Preprocessing):
تنظيف البيانات والتعامل مع القيم المفقودة (Handling Missing Values).
تحويل البيانات النصية/الفئوية (Categorical Data) إلى قيم عددية لتهيئتها للنماذج.
هندسة الميزات لتحسين أداء التنبؤ.
التصور البياني للبيانات (Data Visualization):
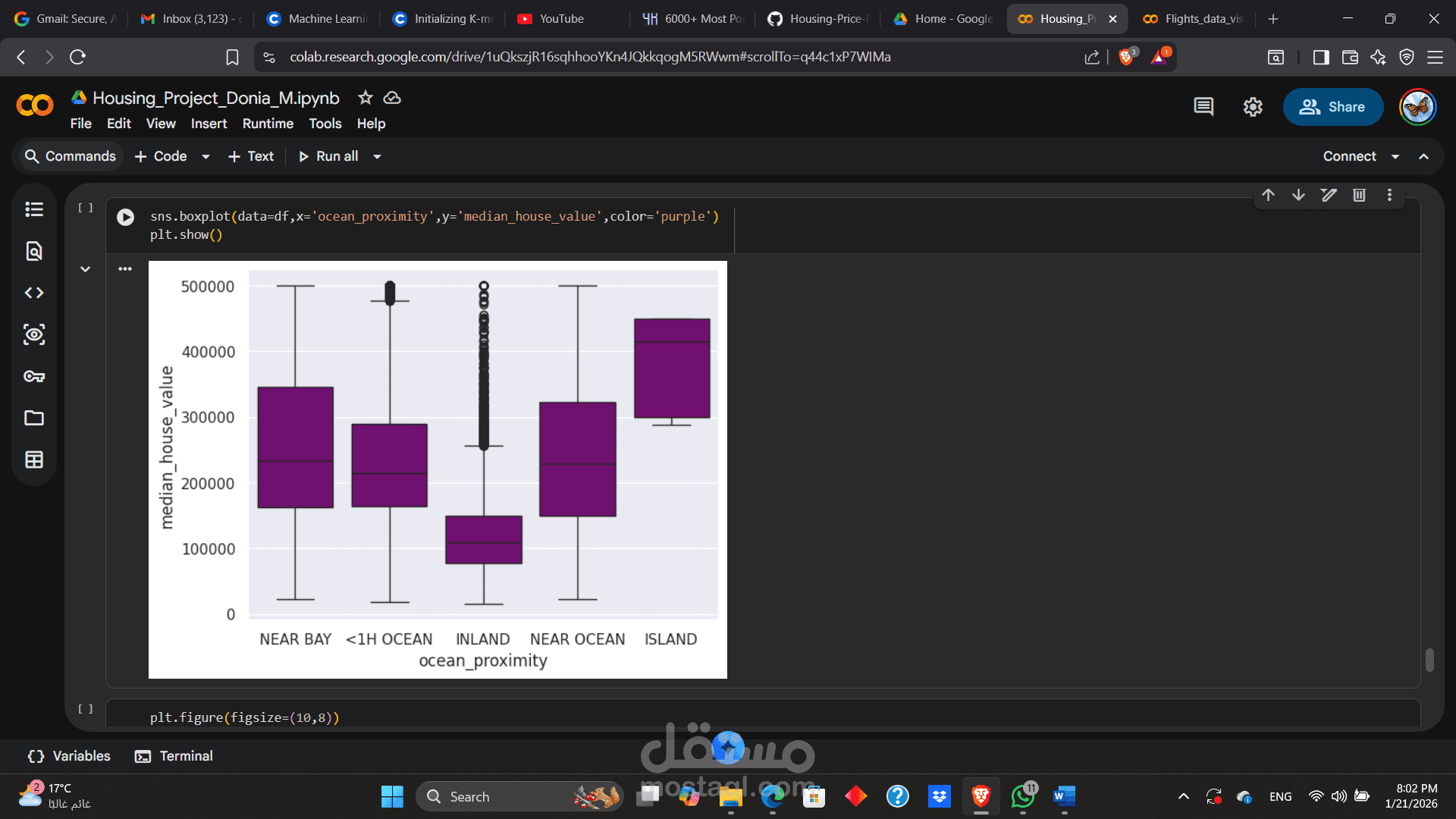
إنشاء رسوم بيانية متقدمة وتوزيعات تكرارية (Histograms) باستخدام مكتبات Matplotlib و Seaborn لاكتشاف الأنماط والارتباطات بين المتغيرات.
بناء وتقييم النماذج (Model Building):
استخدام مكتبة Scikit-Learn لتقسيم البيانات وبناء نموذج التنبؤ.
الهدف هو تقليل نسبة الخطأ في التوقعات لتقديم قيمة حقيقية لأصحاب القرار في القطاع العقاري.
الأدوات المستخدمة:
اللغة: Python
المكتبات: Pandas, NumPy, Scikit-Learn, Matplotlib, Seaborn.
البيئة: / Google Colab.