healthcare stroke predict
تفاصيل العمل

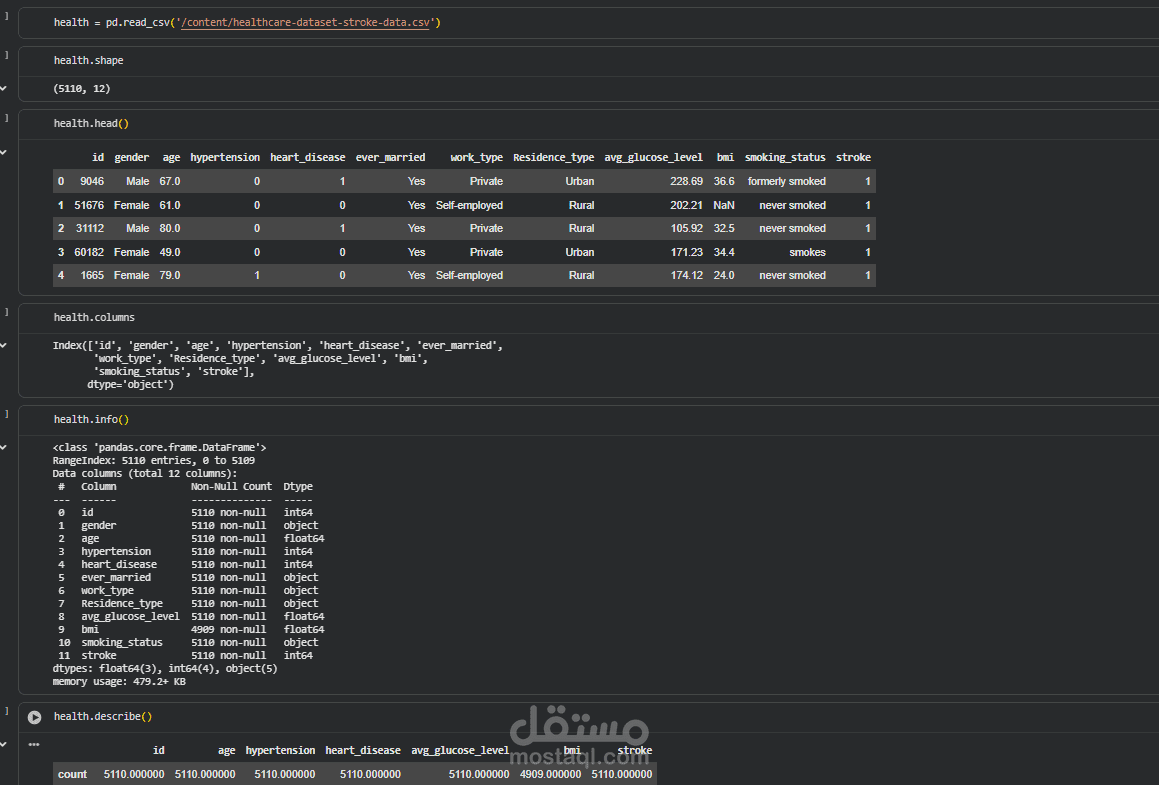

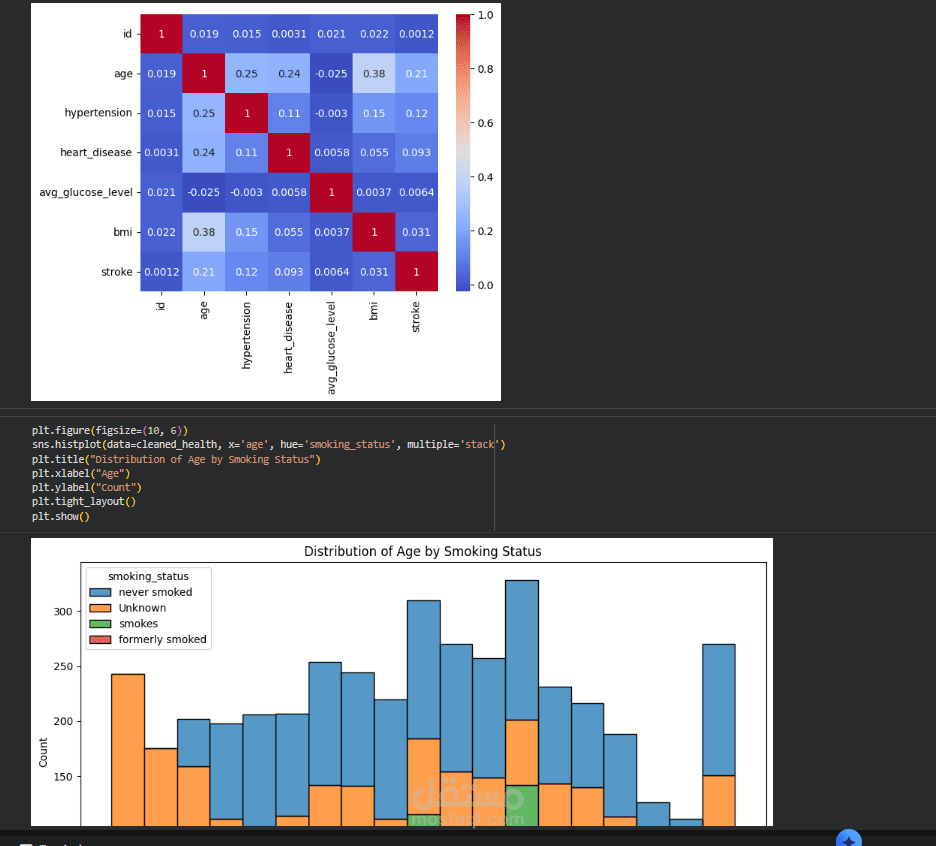
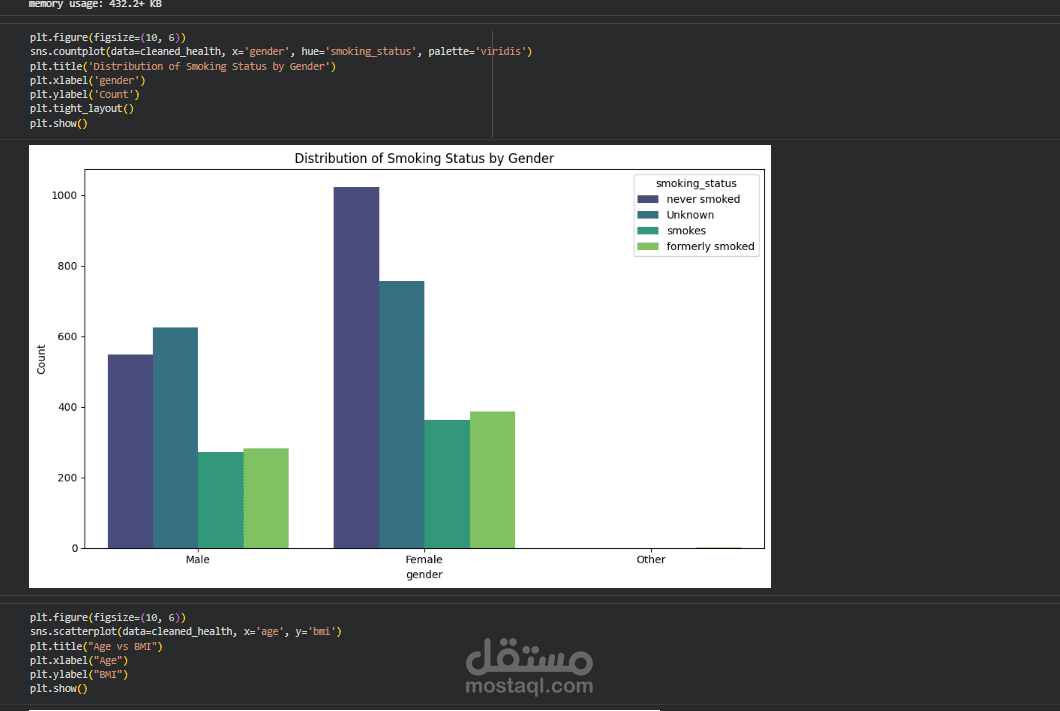
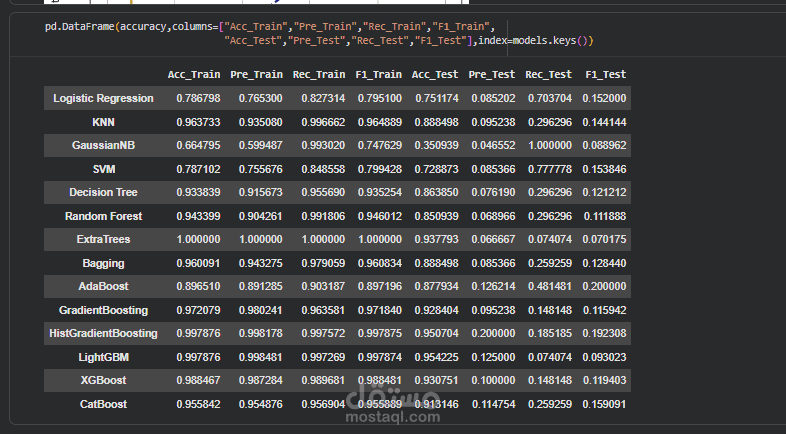
In this project, I implemented a complete machine learning workflow to predict the likelihood of stroke occurrence using clinical and demographic health data. The model analyzes real-world health indicators such as age, gender, hypertension, heart disease history, average glucose level, body mass index (BMI), smoking status, and other patient features to assess stroke risk. The dataset used is sourced from Kaggle’s “Healthcare Stroke Prediction” dataset, which includes over 5,000 patient records with multiple categorical and numerical features.
The work involved:
Data preprocessing: Cleaning the dataset, handling missing values, and encoding categorical variables to prepare the data for training.
Exploratory Data Analysis (EDA): Investigating distributions and relationships among features to gain insights into key risk factors.
Model development: Training and evaluating classification algorithms to accurately predict stroke occurrence, using performance metrics appropriate for binary classification tasks.
Evaluation: Assessing model quality to ensure reliable predictive performance and interpretability.
This project demonstrates practical application of machine learning in healthcare analytics, showcasing the ability to transform complex medical data into actionable predictions that support early risk detection and informed decision-making.
Tools & Technologies: Python, Pandas, NumPy, Scikit-learn, Machine Learning Classification