Web Scraper ذكي لاستخراج وتنظيم بيانات الويب
تفاصيل العمل

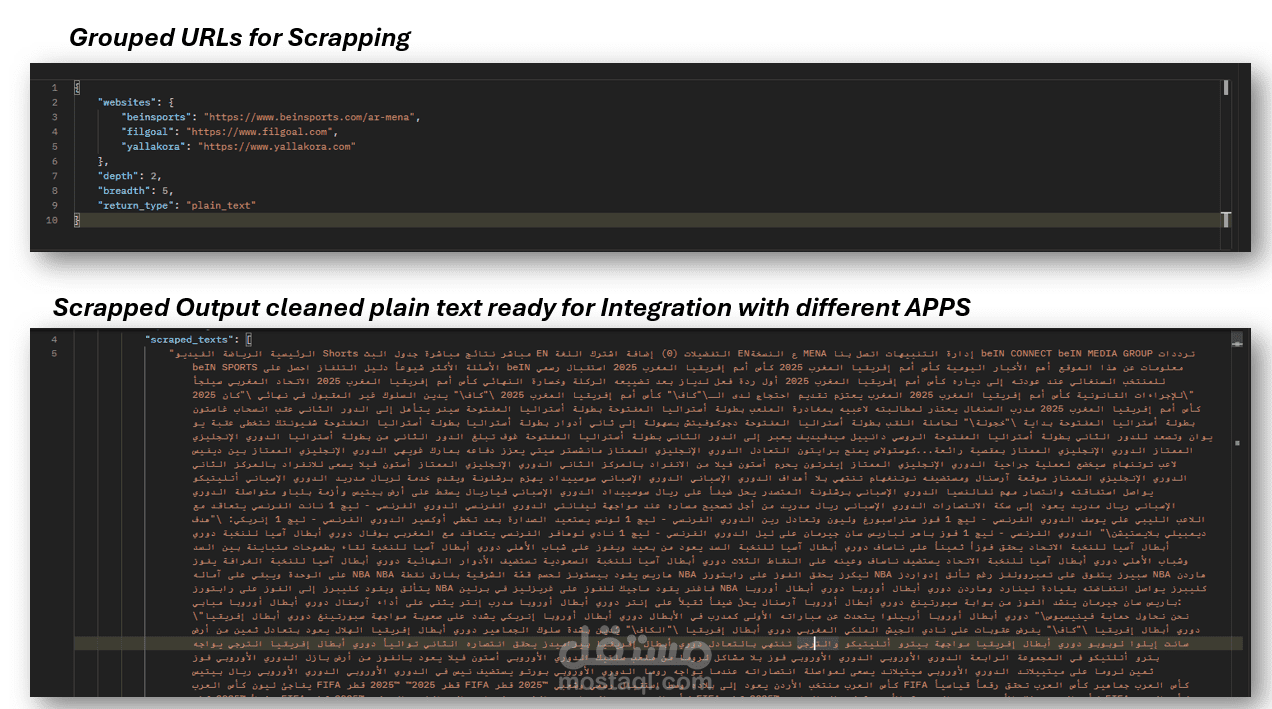
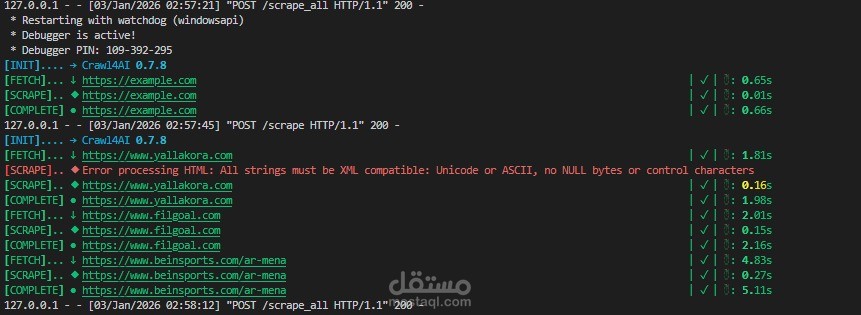
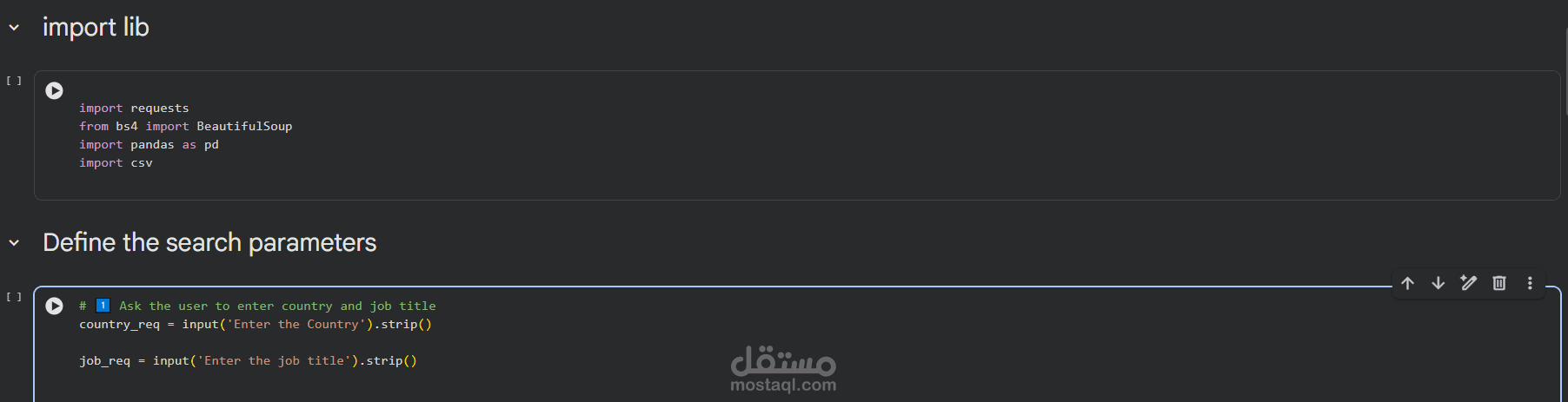
في هذا المشروع تم تنفيذ تطبيق Web Scraping متكامل لاستخراج البيانات من مواقع الويب بشكل آلي ومنظم، بهدف جمع وتحليل بيانات ذات قيمة تدعم اتخاذ القرار.
يقوم التطبيق بالبحث باستخدام كلمات مفتاحية محددة، ثم تصفية النتائج وفق معايير معيّنة مثل الموقع الجغرافي أو نوع المحتوى، وبعد ذلك استخراج البيانات الأساسية من الصفحات الرئيسية، بالإضافة إلى الدخول إلى الصفحات التفصيلية لكل عنصر لاستخلاص معلومات أكثر عمقًا.
تشمل البيانات المستخرجة عناصر رئيسية مثل:
العناوين
الجهات أو الشركات
المواقع الجغرافية
تواريخ النشر
نوع المحتوى
الروابط المباشرة
كما يقوم النظام بزيارة الصفحات الداخلية لكل نتيجة لاستخراج تفاصيل إضافية مثل المتطلبات أو الخصائص الخاصة، ثم تنظيم جميع البيانات في هيكل منظم باستخدام Pandas، مع تصديرها إلى ملف CSV جاهز للتحليل أو الاستخدام في أنظمة أخرى.
يوفر طريقة آلية لجمع البيانات من الويب بدلًا من العمل اليدوي
يساعد في بناء قواعد بيانات قابلة للتحليل
يمكن تطويره لاحقًا لإجراء تحليلات متقدمة أو بناء أنظمة توصية أو لوحات تحكم تفاعلية
مناسب لمشاريع تحليل البيانات، ذكاء الأعمال، وتطبيقات الذكاء الاصطناعي