Podcast Listening Time Prediction
تفاصيل العمل

The steps I followed on this dataset were:
1. Importing libraries and Data overview
2. Handling missing values by using an iterative imputer from Sklearn, then checking Duplicates
3. Checking outliers (there were no outliers; they are all real data)
4. Visualizing the DataFrame
5. Dropping the string "Episode" from the episode title, then encoding by using (OneHotEncoder, OrdinalEncoder)
6. Splitting Data (KFold), Followed by Scaling/Normalization (StandardScaler)
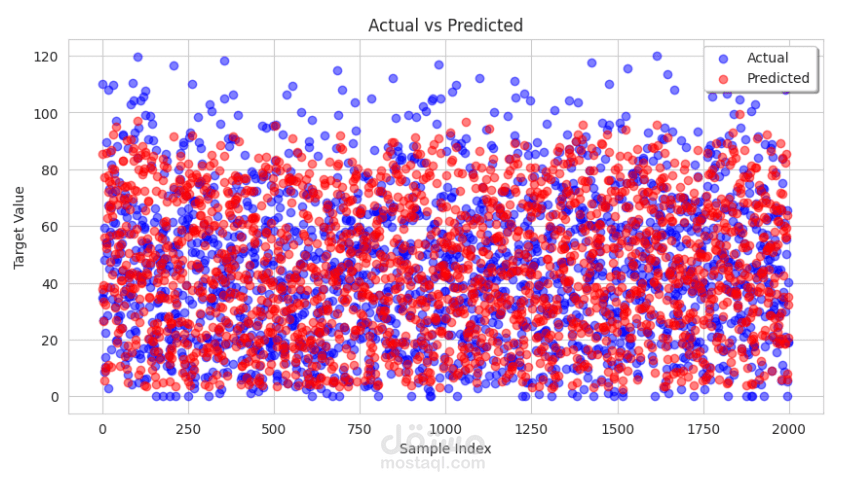
7. 15 machine learning models (regressors) were applied, and Grid Search was done for the best model R^2 result. Then the final model was used for GradientBoostingRegressor.
8. Deployment by using gradio
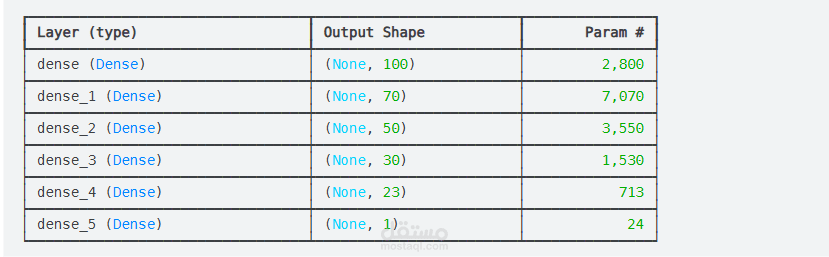
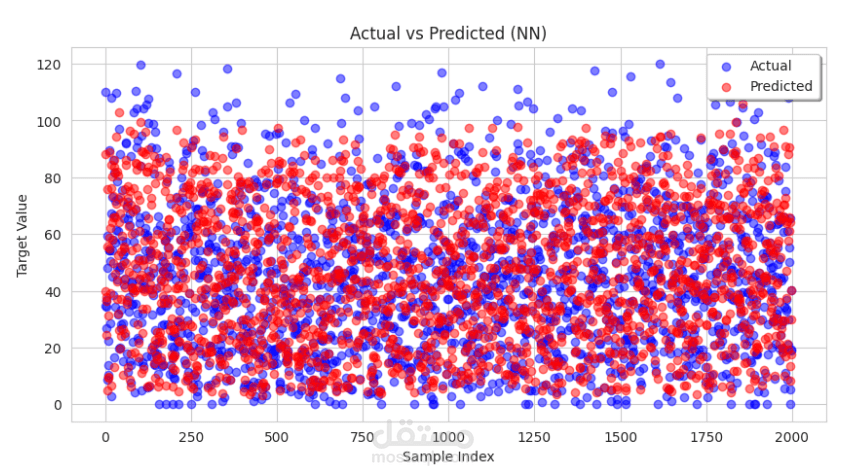
9. Neural Network with activation by ReLU, optimizers by Adam