DocuVisionLM - مساعد ذكي لفهم المستندات
تفاصيل العمل
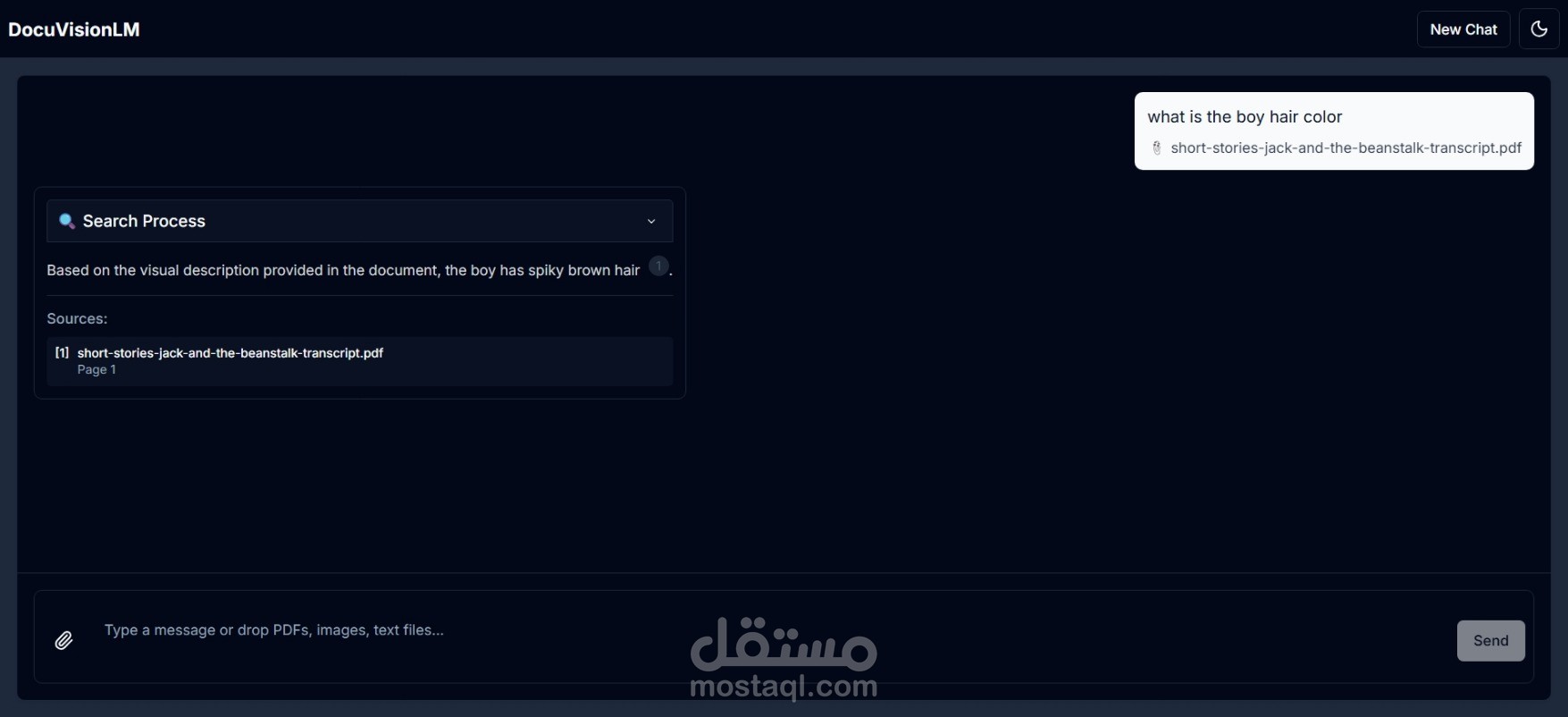
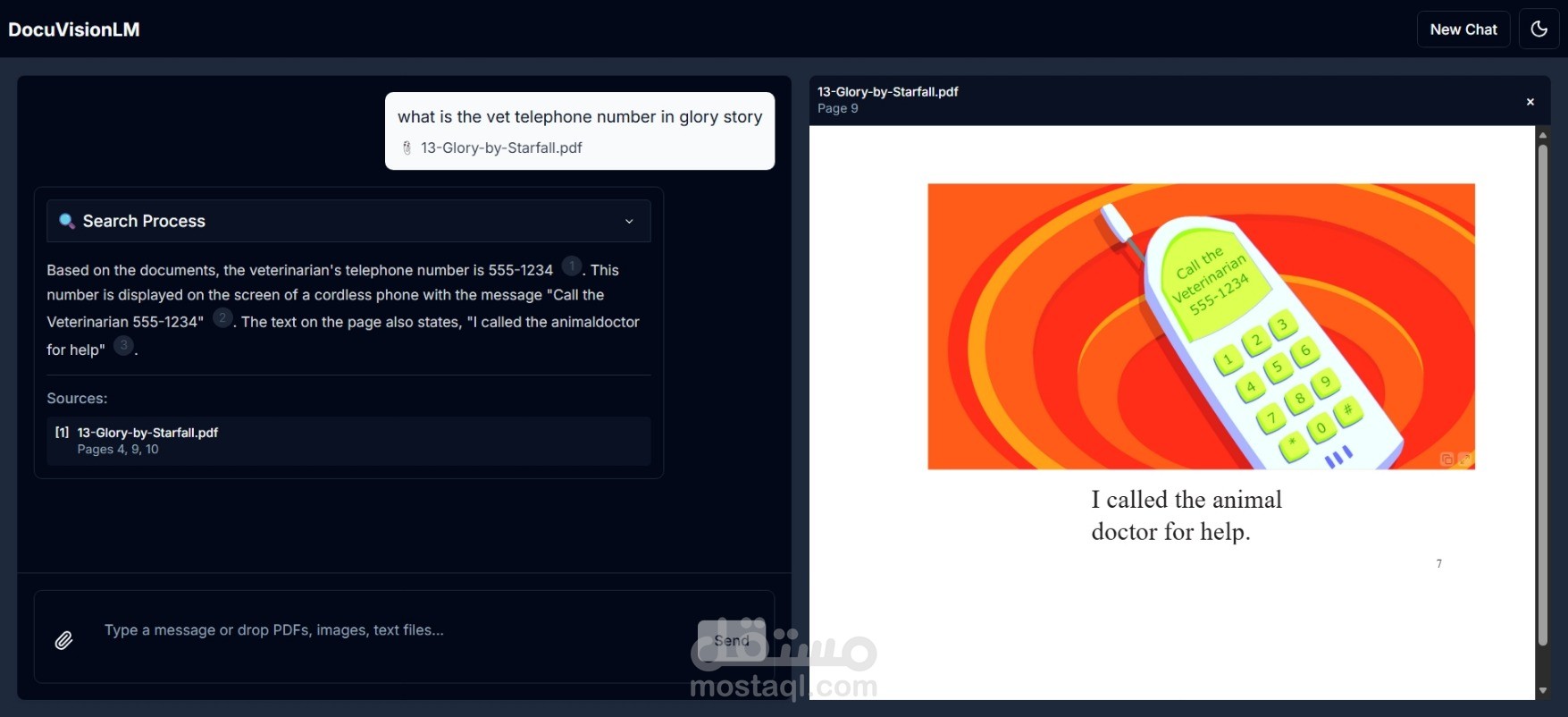
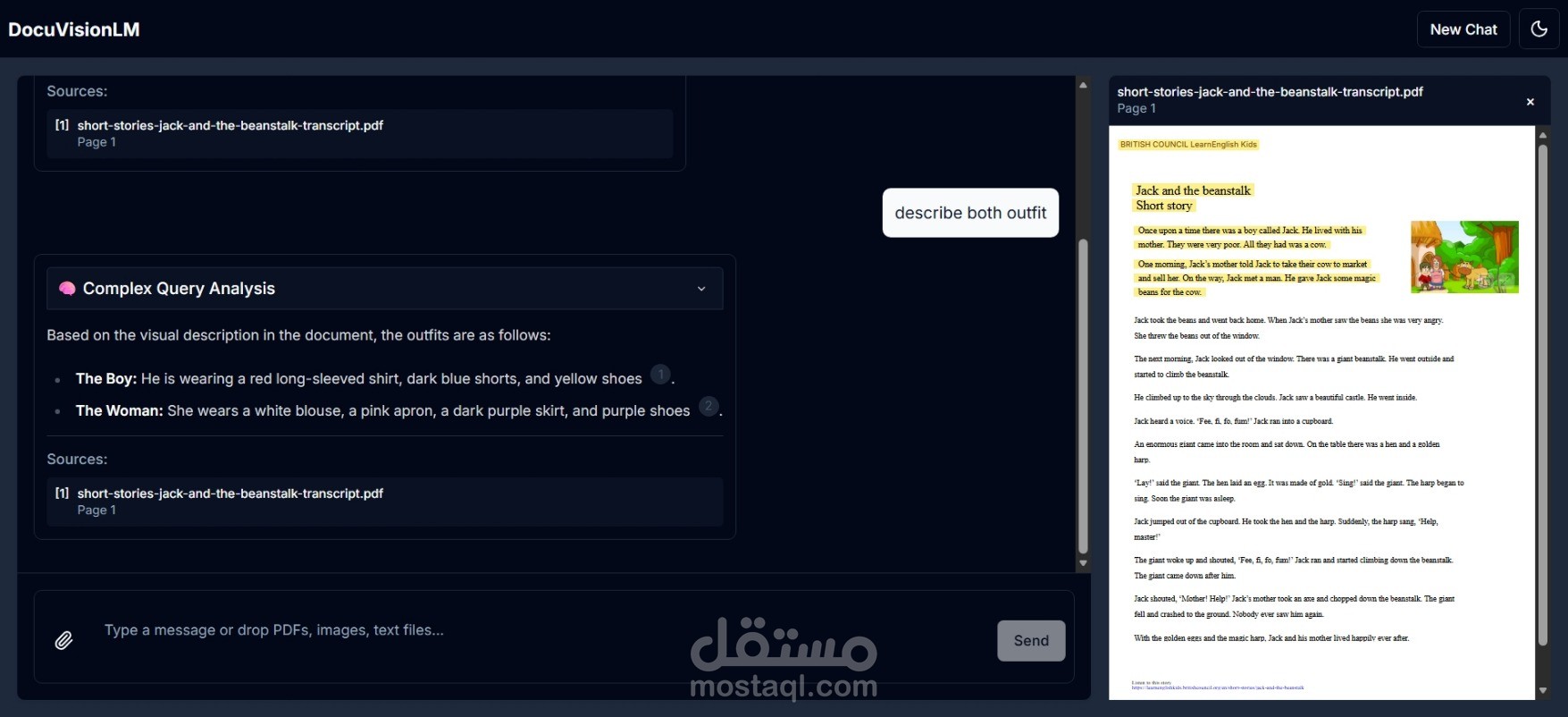
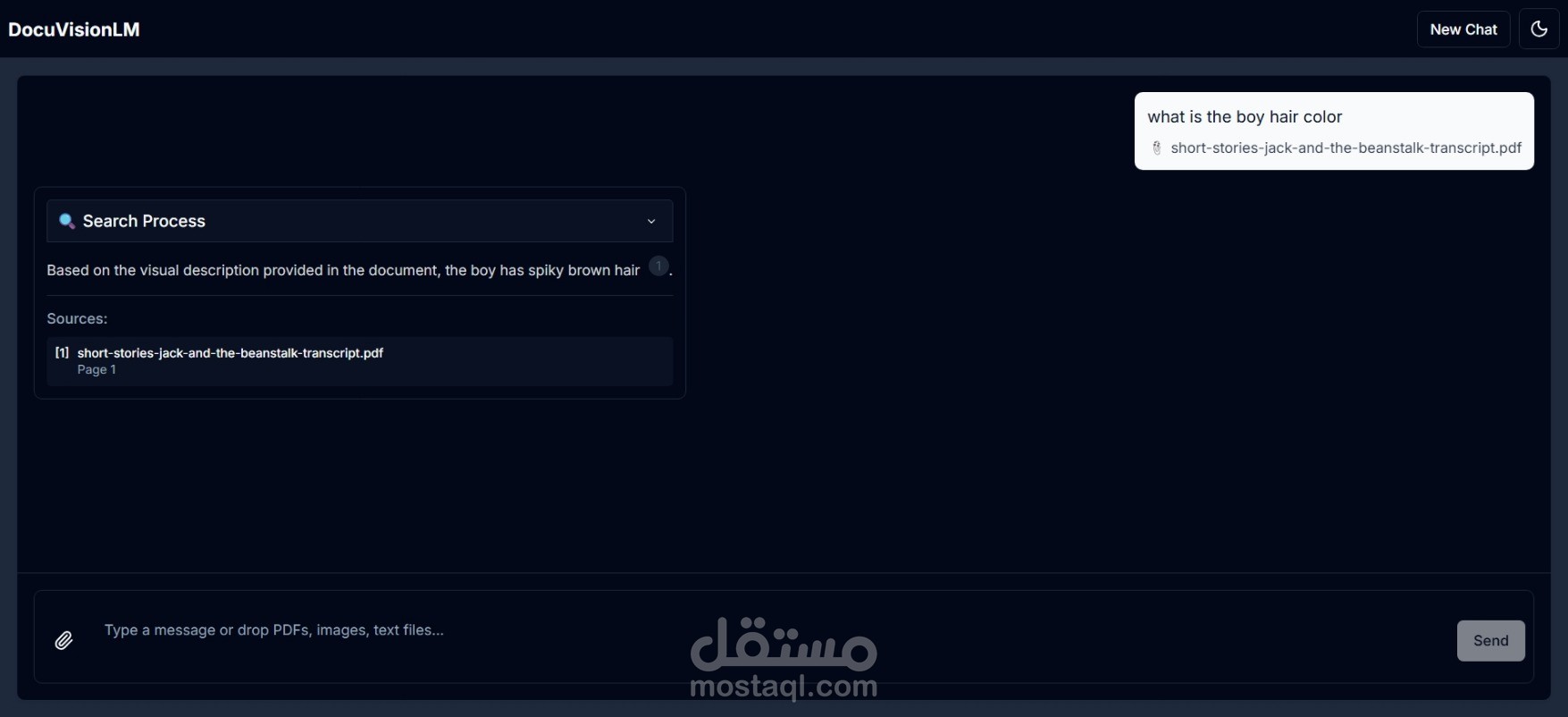
DocuVisionLM هو تطبيق ويب متقدم يجمع بين قوة الذكاء الاصطناعي والرؤية الحاسوبية لتحويل طريقة تفاعلك مع المستندات. مستوحى من NotebookLM من Google، لكن مع إضافة ميزة فريدة: القدرة على فهم وتحليل الصور والرسوم البيانية داخل المستندات.
المشكلة
كثير من الأحيان نحتاج للبحث في ملفات PDF طويلة أو مستندات معقدة تحتوي على صور ورسوم بيانية، لكن الأدوات التقليدية تتجاهل المحتوى البصري وتركز فقط على النص. هذا يعني فقدان معلومات مهمة موجودة في الصور والجداول.
الحل
بنيت DocuVisionLM ليكون مساعدك الذكي الذي:
يقرأ ملفات PDF ويفهم محتواها النصي والبصري
يحلل الصور والرسوم البيانية باستخدام Gemini Vision AI
يستخرج النصوص من الصور باستخدام OCR
يتيح لك المحادثة مع مستنداتك بشكل طبيعي
يعرض لك مصادر الإجابات مع إمكانية معاينة الصفحات الأصلية
التقنيات المستخدمة
Backend (Python/FastAPI):
معالجة المستندات باستخدام PyMuPDF المعروفة بسرعتها ودقتها في التعامل مع ملفات PDF
تحليل الصور بـ Gemini 2.5 Pro Vision
استخراج النصوص بـ Tesseract OCR
تخزين الملفات على AWS S3
Frontend (Next.js/TypeScript):
واجهة مستخدم عصرية وسريعة
محادثة تفاعلية مع المستندات
معاينة فورية للصفحات والاقتباسات
AI & Vector Search:
Gemini 2.5 Pro للمحادثة الذكية
PostgreSQL مع pgvector للبحث الدلالي
Text Embedding 004 لتحويل النصوص لـ vectors
الميزات الرئيسية
✨ فهم شامل للمستندات: يحلل النصوص والصور والجداول معاً
? بحث دلالي ذكي: يفهم سؤالك ويجد الإجابة حتى لو لم تكن الكلمات متطابقة
? محادثة طبيعية: اسأل أي سؤال عن مستنداتك بلغة عادية
? تحليل بصري: يفهم الرسوم البيانية والصور ويشرحها لك
? مصادر موثوقة: كل إجابة مرفقة بمصدرها من المستند الأصلي
⚡ أداء سريع: معالجة متوازية للصفحات والصور