التنبؤ بمعدل التبخر والنتح (Evapotranspiration) باستخدام الذكاء الاصطناعي والبيانات المناخية من قابس
تفاصيل العمل
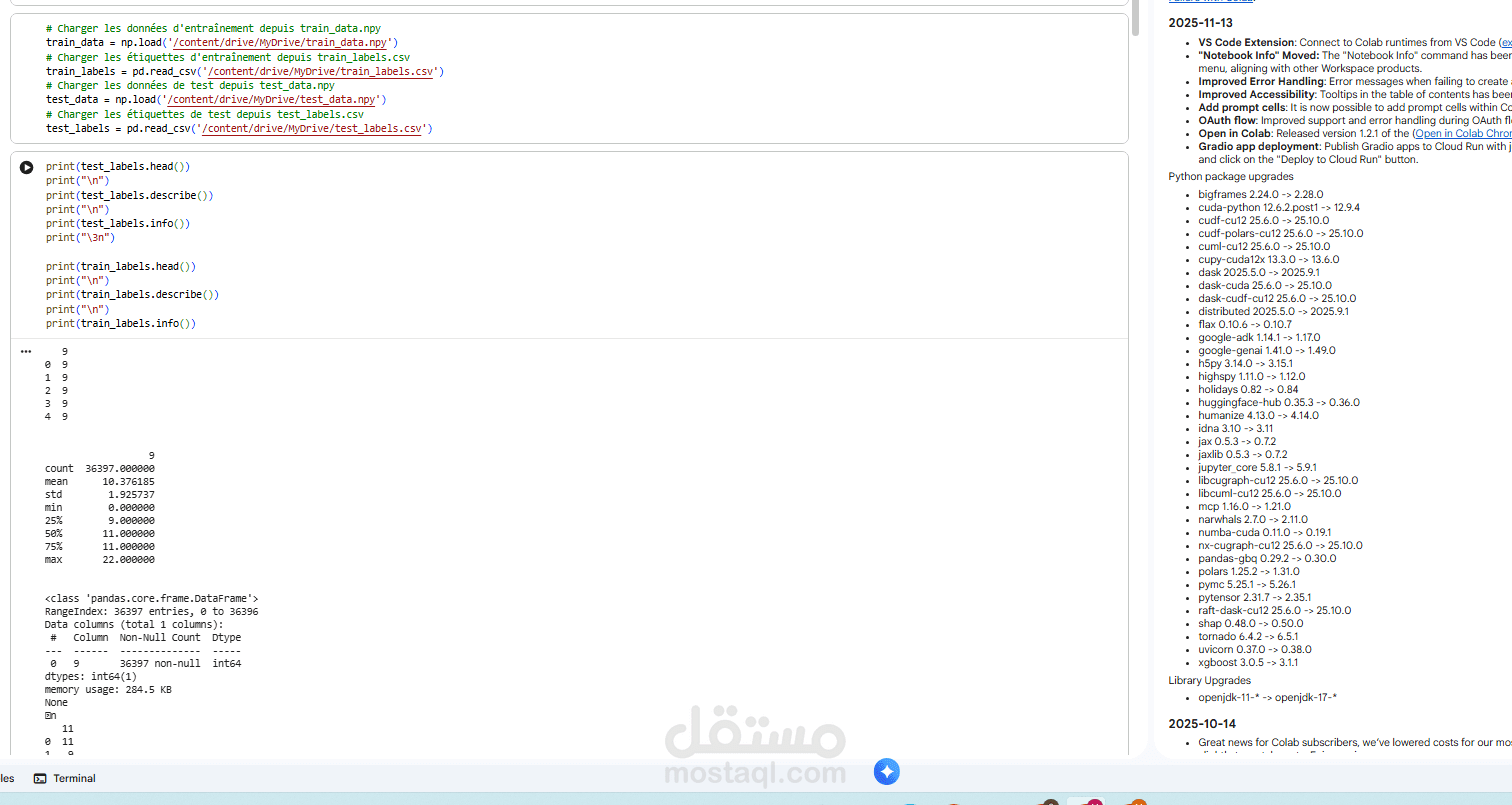
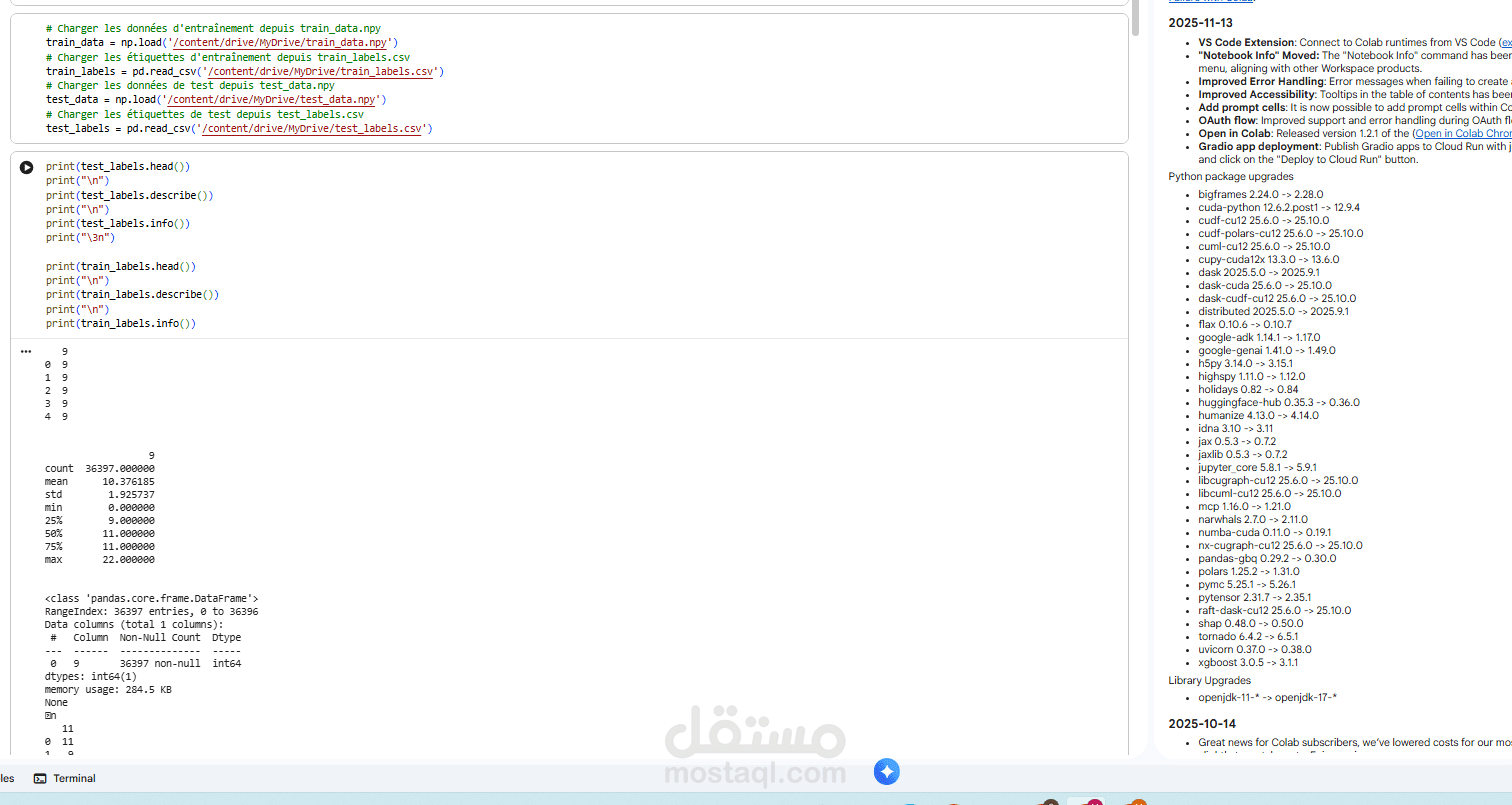
هذا المشروع (Projet IA) يركز على بناء نظام ذكاء اصطناعي للتنبؤ بمعدل التبخر والنتح (Ev0: Evapo-transpiration) باستخدام بيانات مناخية من محطة قابس (Gabes STATION AVFA – AgriDATA). النظام يستخدم 5 معلمات دخل للتنبؤ بـ Ev0 كمخرج.
المعلمات الدخل:
- T: درجة حرارة الهواء [°C].
-P: كمية الأمطار [mm].
- HR: الرطوبة النسبية [%].
- VV: سرعة الرياح [m/s].
- RS: الإشعاع الشمسي [W/m²].
الخطوات الرئيسية (Steps):
1. معالجة البيانات الأولية (Data pre-processing):
- تعبئة القيم المفقودة بالاستيفاء (interpolation).
- تطبيع البيانات (normalization) لإزالة تأثير الأبعاد بين العوامل المناخية، مما يسرع خوارزمية التدريب ويحسن الدقة.
2.التدريب (Training):
- إدخال البيانات المعالجة إلى شبكة النموذج (model network) مع تهيئة عشوائية للمعلمات.
- تحديد طول خطوة التنبؤ، تدريب بالدفعات (batching)، مقارنة القيم المتوقعة بالقيم الحقيقية.
- الاستمرار حتى ينخفض الخطأ إلى درجة معينة أو يصل عدد التكرارات المحدد.
3. التطبيق على البيانات الاختبارية:
- استخدام العينة التدريبية لتشغيل النموذج، ثم إدخال عينة الاختبار إلى النموذج المدرب جيدًا.
4. رسم المنحنيات:
- رسم منحنيات تغير المتغيرات الدخل.
5. حساب المقاييس:
- حساب جذر متوسط مربع الانحراف (RMSE) للمعلم Ev0 المتوقع.
6. تقييم النموذج:
- تقييم المصنف المدرب بناءً على مجموعة الاختبار.
- رسم منحنيات تغير دالة الخسارة (loss function).
مقياس التقييم الرئيسي:
- RMSE (Root-Mean-Square Error): مقياس شائع لقياس الفرق بين القيم المتوقعة والقيم المرصودة. يُحسب كجذر مربع متوسط مربعات الفروقات.
- الصيغة: rmse = math.sqrt(mean_squared_error(y_test, pred)).
- يُستخدم لتقييم دقة النموذج في التنبؤات.
وصف البيانات:
-ملف التدريب: "train_data.npy" (البيانات).
- علامات التدريب: "train_labels.csv".
- ملف الاختبار: "test_data.npy".
- علامات الاختبار: "test_labels.csv".
تنسيق التقديم (Submission Format):
- يجب أن يحتوي الملف على عمودين: Id (الفهرس من مجموعة الاختبار) و EVo[mm] (القيم المتوقعة).
هذا المشروع يهدف إلى تطبيق تقنيات الذكاء الاصطناعي (ربما شبكات عصبية) للتنبؤ المناخي، مع التركيز على معالجة البيانات والتقييم الدقيق. مناسب لمجالات الزراعة والمناخ.