نظام ذكي للتنبؤ بأمراض القلب باستخدام تعلم الآلة (Machine Learning)
تفاصيل العمل
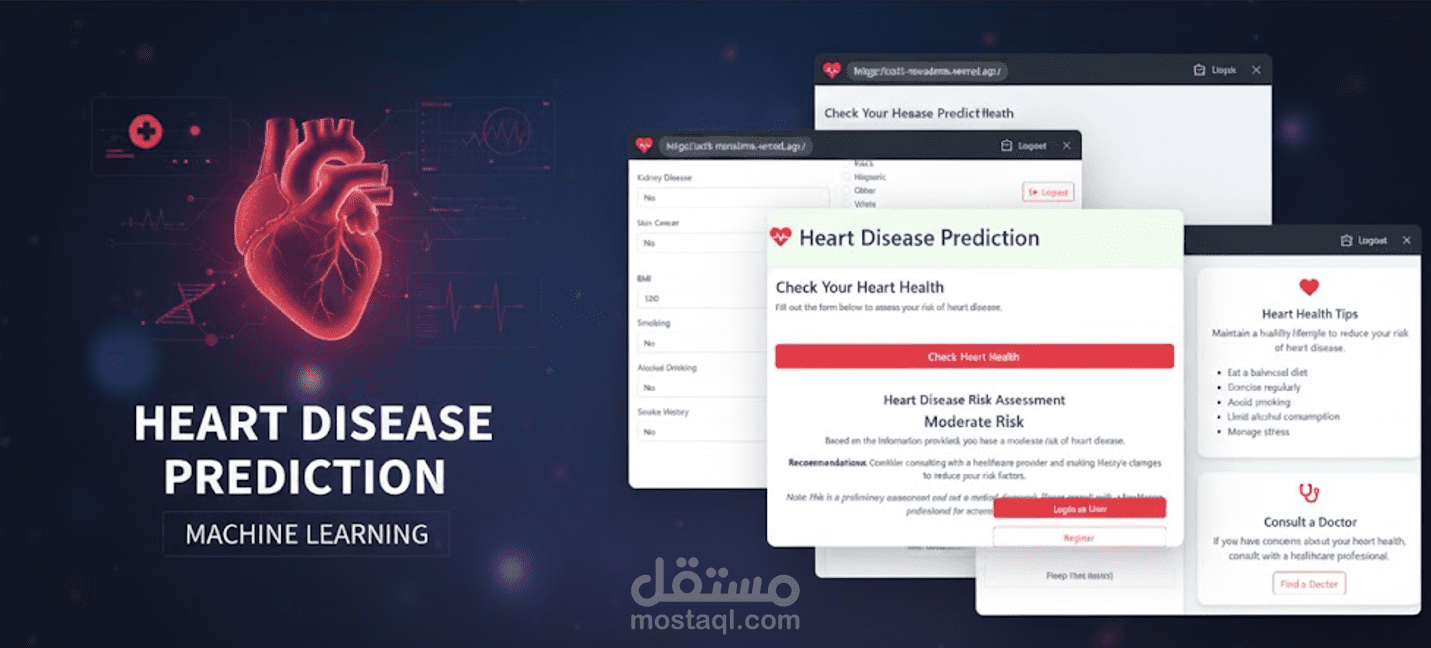
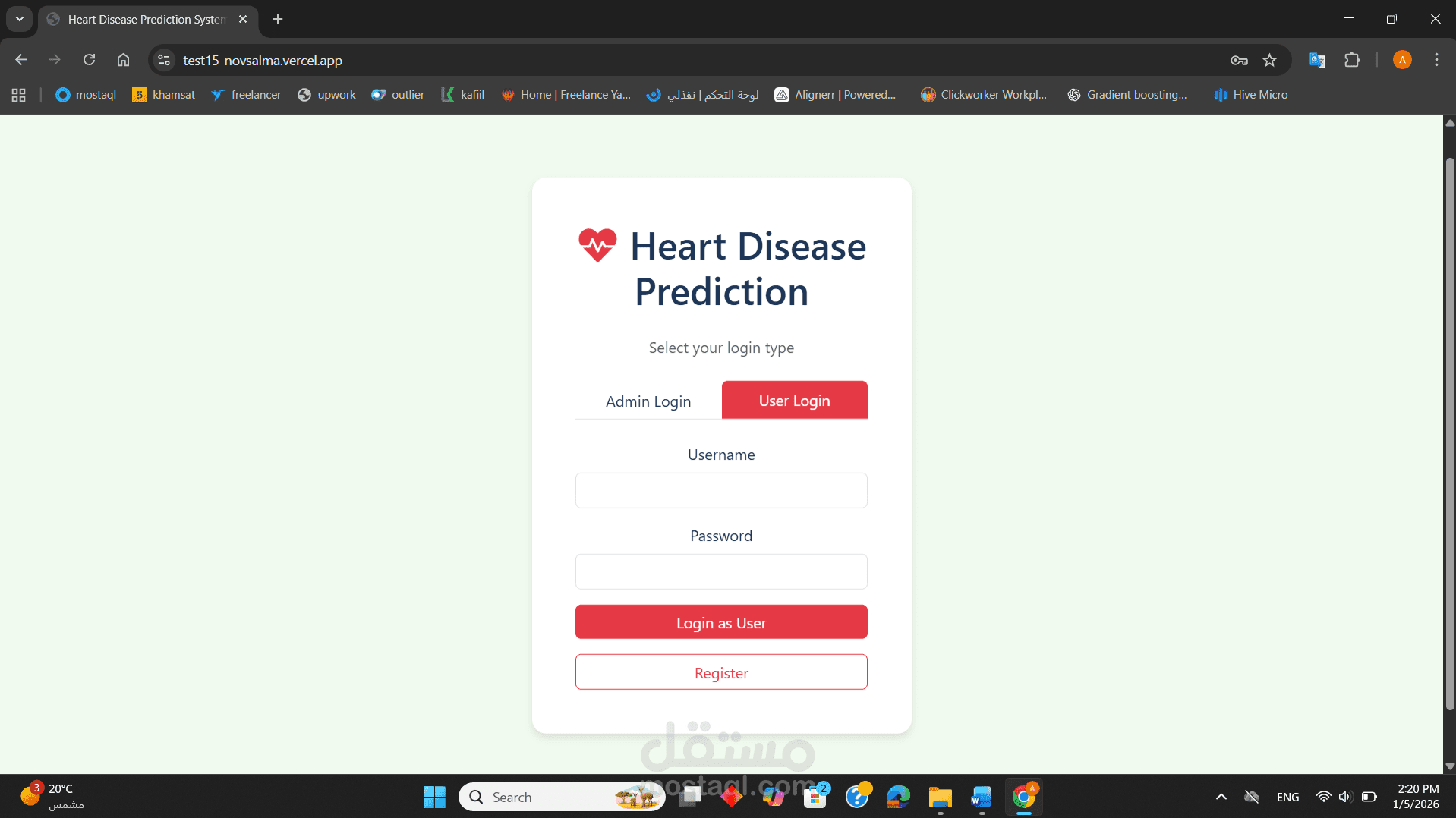
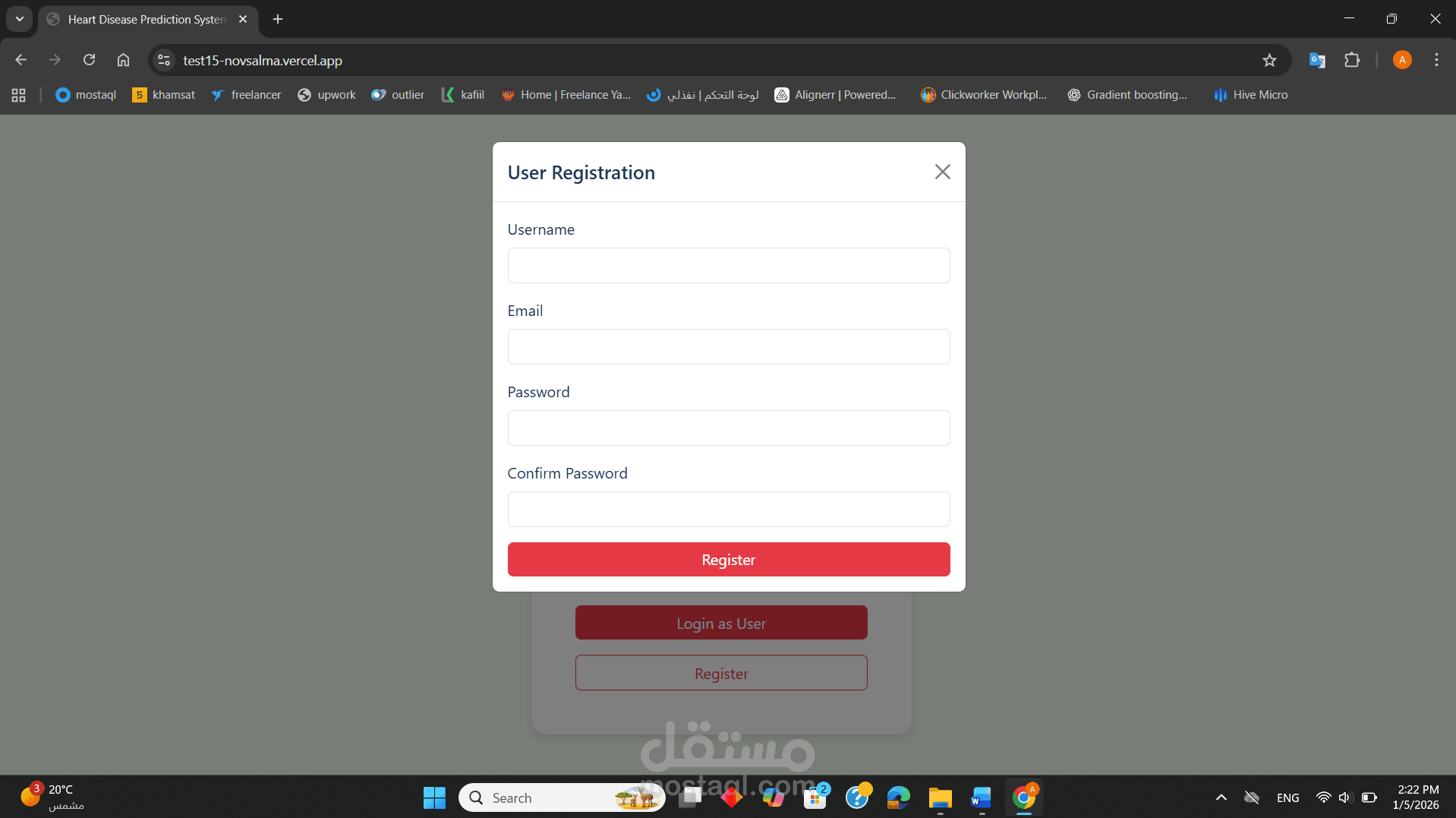
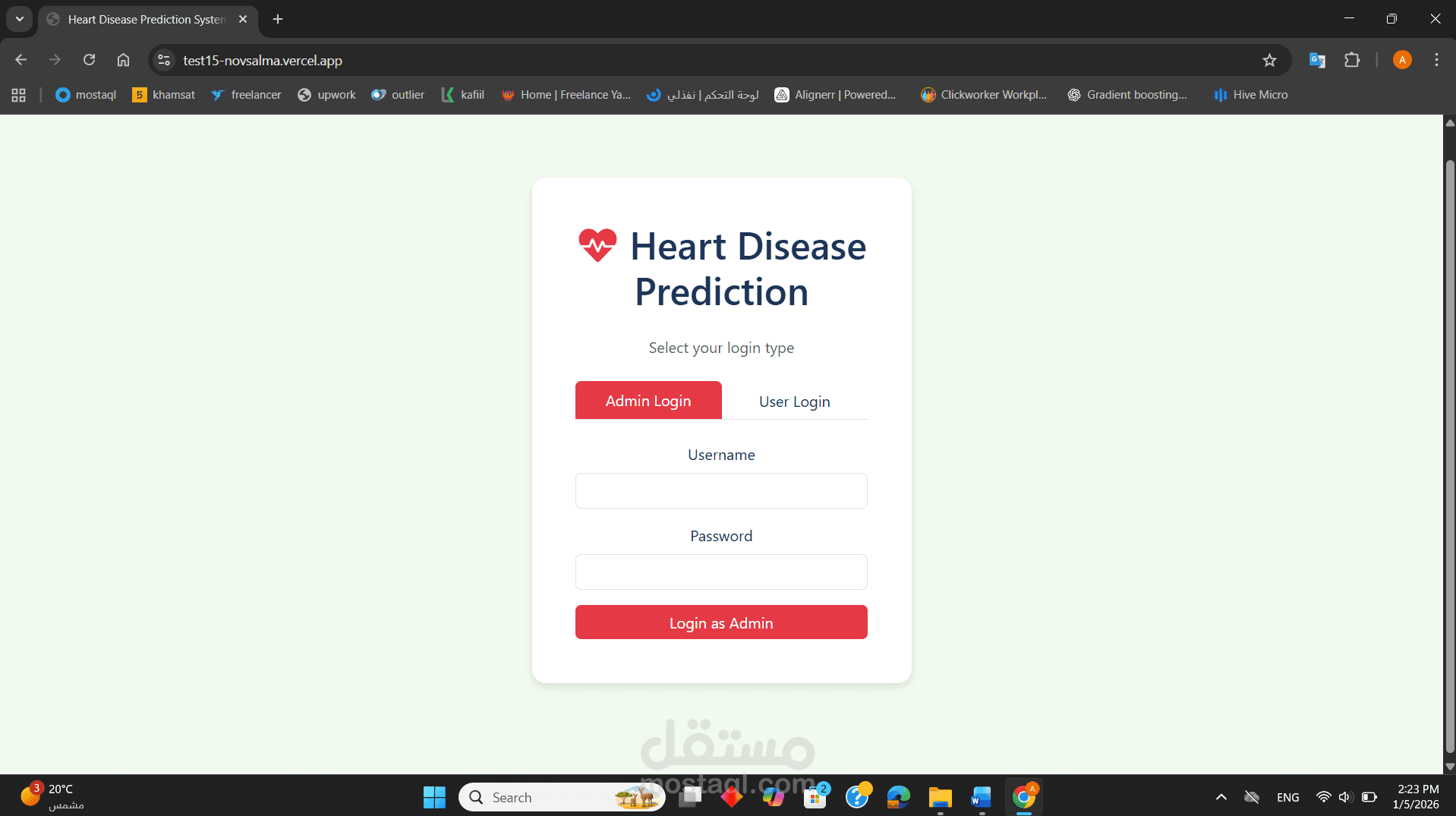
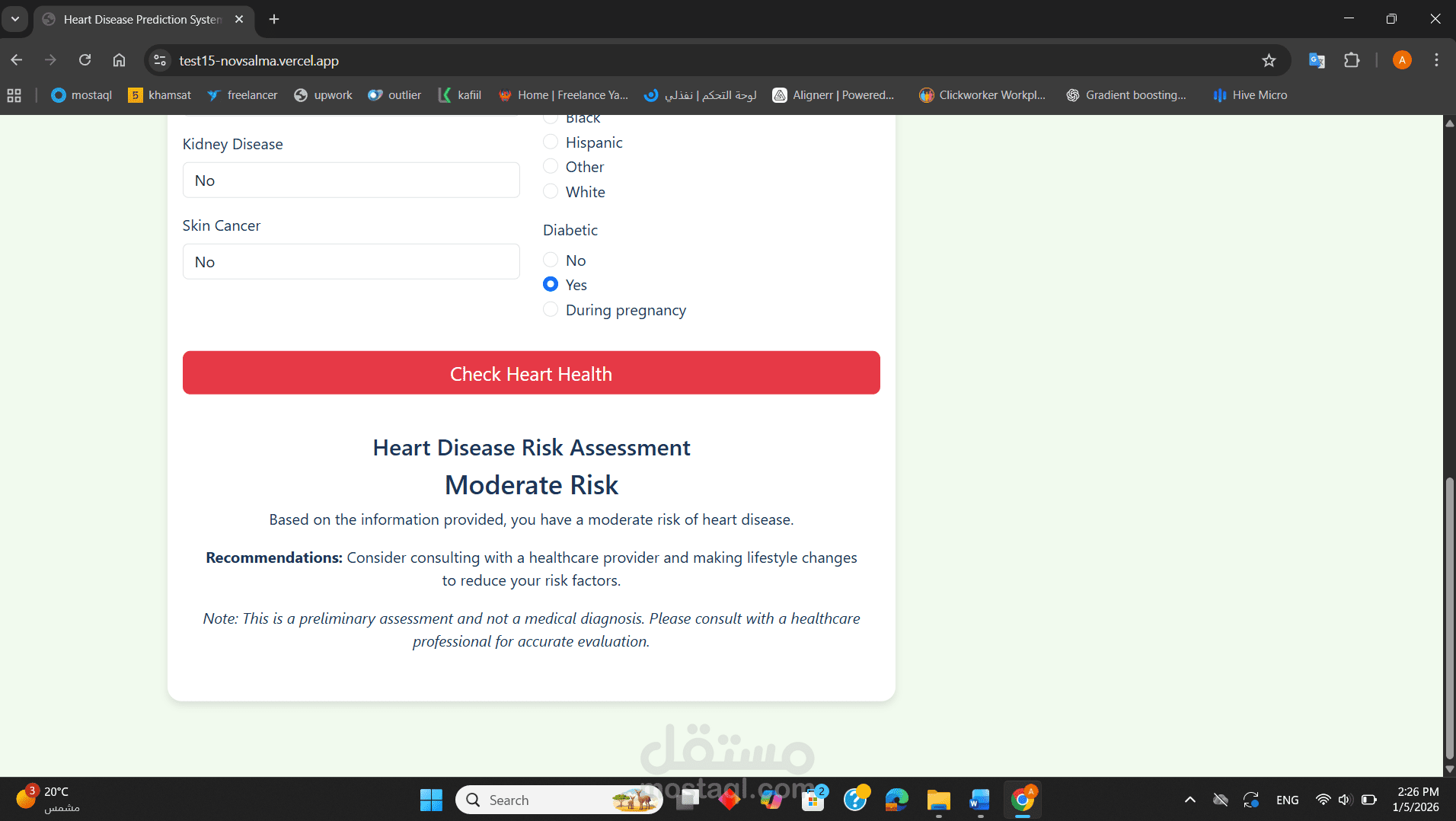
قمت بتطوير نظام متكامل لتحليل البيانات الطبية والتنبؤ باحتمالية الإصابة بأمراض القلب بناءً على السلوكيات الصحية والمؤشرات الحيوية. المشروع ليس مجرد "كود برمجى"، بل هو دراسة تحليلية شاملة تهدف إلى دعم اتخاذ القرار الطبي المبكر.
رابط المشروع للاطلاع عليه : https://test15-novsalma.v...
أبرز ما يميز المشروع:
تحليل البيانات الاستكشافي (EDA): استخدام مكتبات Seaborn و Plotly لإنشاء رسوم بيانية تفاعلية تكشف العلاقة بين المتغيرات (مثل تأثير التدخين، العمر، ومؤشر كتلة الجسم على صحة القلب).
معالجة البيانات المتقدمة: التعامل مع البيانات المفقودة، وتعديل القيم الشاذة (Outliers)، واستخدام تقنية SMOTE + ENN لحل مشكلة عدم توازن الفئات (Class Imbalance) لضمان دقة التنبؤ للحالات المصابة فعلياً.
بناء النماذج المقارنة: تم اختبار عدة خوارزميات مثل Logistic Regression و Random Forest و Gradient Boosting.
نشر النموذج (Deployment): تم تطوير تطبيق ويب تفاعلي باستخدام Vercel للسماح للمستخدمين بإدخال بياناتهم والحصول على تنبؤ فوري.
?️ تفاصيل تقنية (أضفها في قسم المهارات أو داخل الوصف)
1. مرحلة معالجة البيانات (Preprocessing)
Handling Imbalance: استخدمت تقنيات BorderlineSMOTE لرفع كفاءة النموذج في التعرف على فئة المصابين.
Feature Engineering: تحويل البيانات النصية إلى أرقام باستخدام One-Hot Encoding و Ordinal Encoding لضمان فهم النموذج للترتيب المنطقي (مثل الفئات العمرية).
Scaling: تطبيق RobustScaler و StandardScaler لضمان عدم تأثر النموذج بالقيم المتباينة.
2. النتائج والتقييم (Model Results)
بناءً على ملفاتك، تفوق نموذج Gradient Boosting و Random Forest في تحقيق توازن ممتاز بين الدقة (Accuracy) والاستدعاء (Recall).
Accuracy: تقريباً 85% - 92% (حسب النتائج النهائية).
Recall: تم التركيز عليه لضمان عدم تفويت أي حالة إصابة محتملة.
3. الأدوات المستخدمة:
Languages: Python.
Libraries: Pandas, Scikit-learn, Imbalanced-learn, XGBoost, SHAP (لشرح قرارات النموذج).
Visualization: Matplotlib, Seaborn, Plotly.
Deployment: Vercel.