استخراج وتحليل بيانات ضخمة من مواقع معقدة (Advanced Web Scraping & Data Mining)
تفاصيل العمل


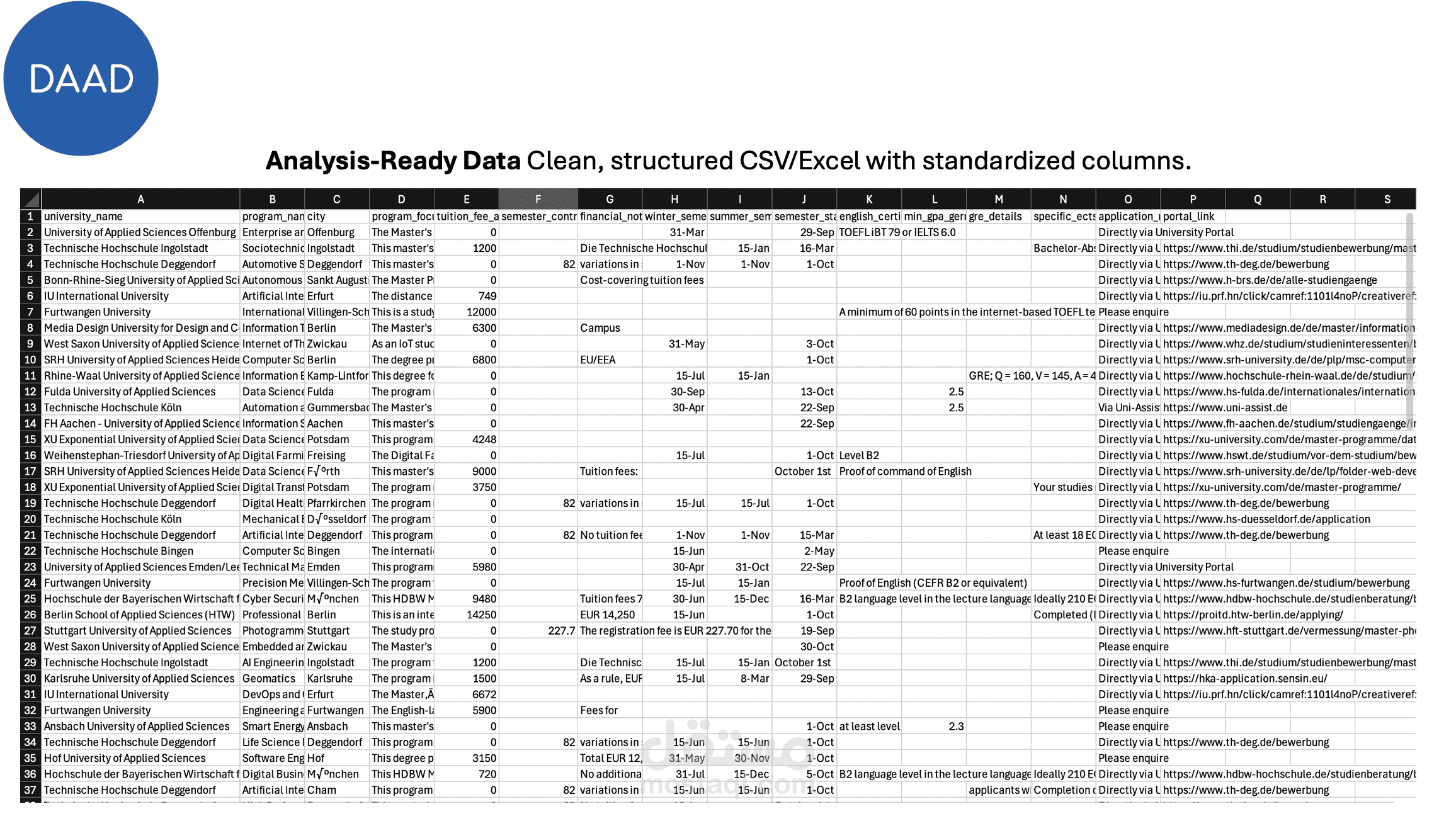
في هذا المشروع، قمت بدمج قوة Python مع نماذج الذكاء الاصطناعي (Google Gemini AI) لاستخراج وتحليل قاعدة بيانات أكاديمية ضخمة من موقع DAAD، تحتوي على آلاف البرامج الدراسية.
المشكلة الرئيسية لم تكن في سحب الصفحات، بل في أن البيانات كانت "غير مهيكلة" (Unstructured Text) ومكتوبة بصيغ عشوائية لا يمكن معالجتها بالطرق التقليدية.
الحل التقني الذي قدمته:
- المعالجة بالذكاء الاصطناعي (AI Parsing): قمت بربط السكربت بنموذج Gemini AI لقراءة النصوص المعقدة، وفهم سياقها، ثم استخراج المعلومات الدقيقة (مثل الرسوم الدراسية، المواعيد النهائية، ومتطلبات اللغة) وتحويلها إلى هيكل JSON موحد.
- دقة بيانات فائقة: بفضل الـ AI، تمكنت من تنظيف حقول معقدة وتوحيد تنسيقها (Normalization) بدقة يستحيل الوصول إليها باستخدام الـ Regex العادي.
- الأتمتة الكاملة: النظام يعمل بشكل آلي بالكامل؛ يسحب الصفحة، يرسل البيانات للـ AI للمعالجة، ثم يخزن النتيجة النهائية في ملف Excel منظم.
النتيجة: تحويل آلاف الصفحات الفوضوية إلى ملف بيانات (Dataset) نظيف تماماً، بأعمدة معيارية جاهزة للتحليل واتخاذ القرار.