NLP_Sentiment140_CNNxGloVe
تفاصيل العمل
مشروع لتحليل المشاعر النصية باستخدام تقنيات التعلم العميق، يهدف إلى تصنيف النصوص إلى إيجابية أو سلبية بدقة عالية. تم الاعتماد على مجموعة بيانات Sentiment140 مع اختيار عينة متوازنة لضمان عدالة عملية التدريب بين الفئات المختلفة.
شمل العمل تنفيذ مرحلة معالجة بيانات متكاملة، تضمنت تنظيف النصوص، إزالة الكلمات غير المؤثرة، وتحويل الكلمات إلى تمثيلات رقمية باستخدام نماذج جاهزة مثل FastText و GloVe لتعزيز فهم النموذج للمعاني اللغوية.
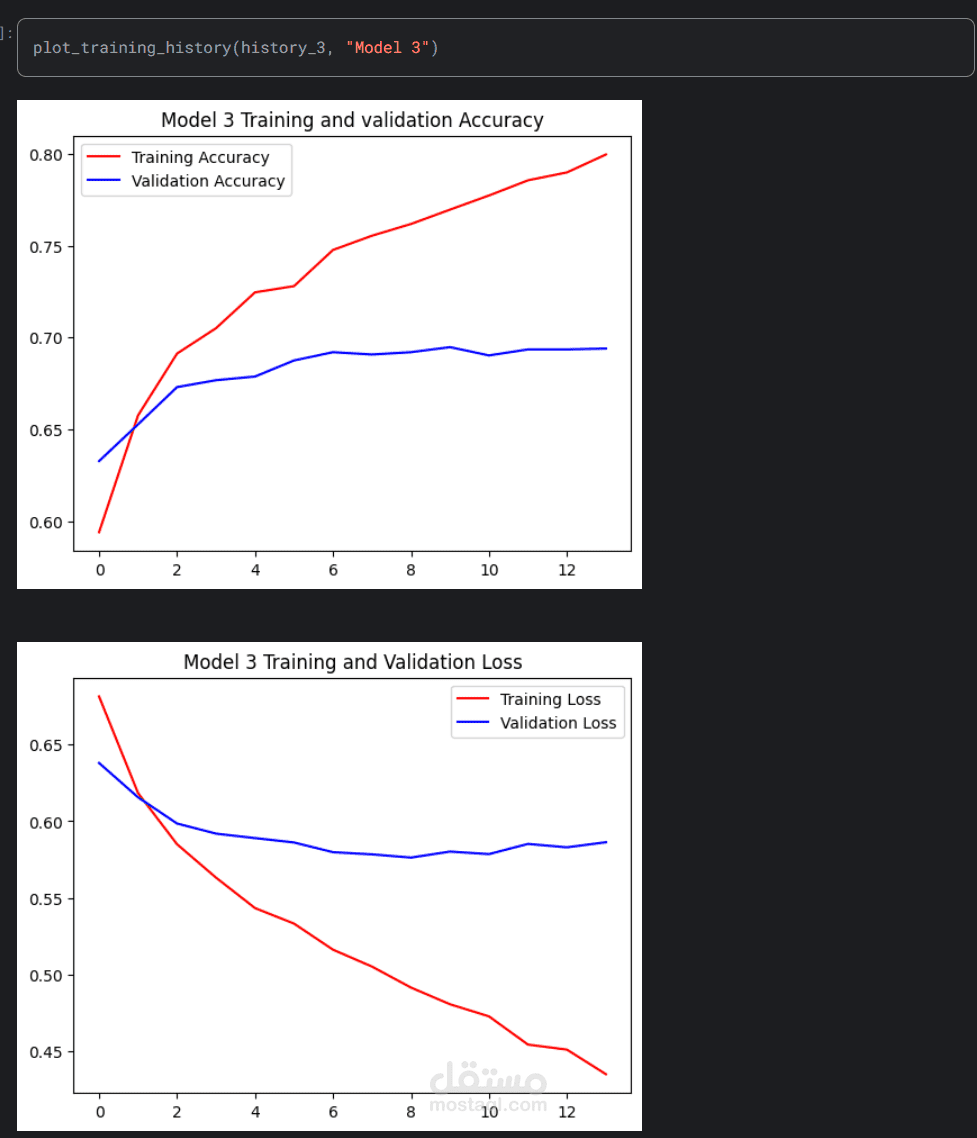
تم تصميم وبناء وتدريب عدة نماذج شبكات عصبية تلافيفية (CNN) باستخدام TensorFlow/Keras، مع تطبيق تقنيات تحسين الأداء مثل Dropout و Batch Normalization و ReduceLROnPlateau للحد من الإفراط في التعلم وتحسين نتائج النموذج.
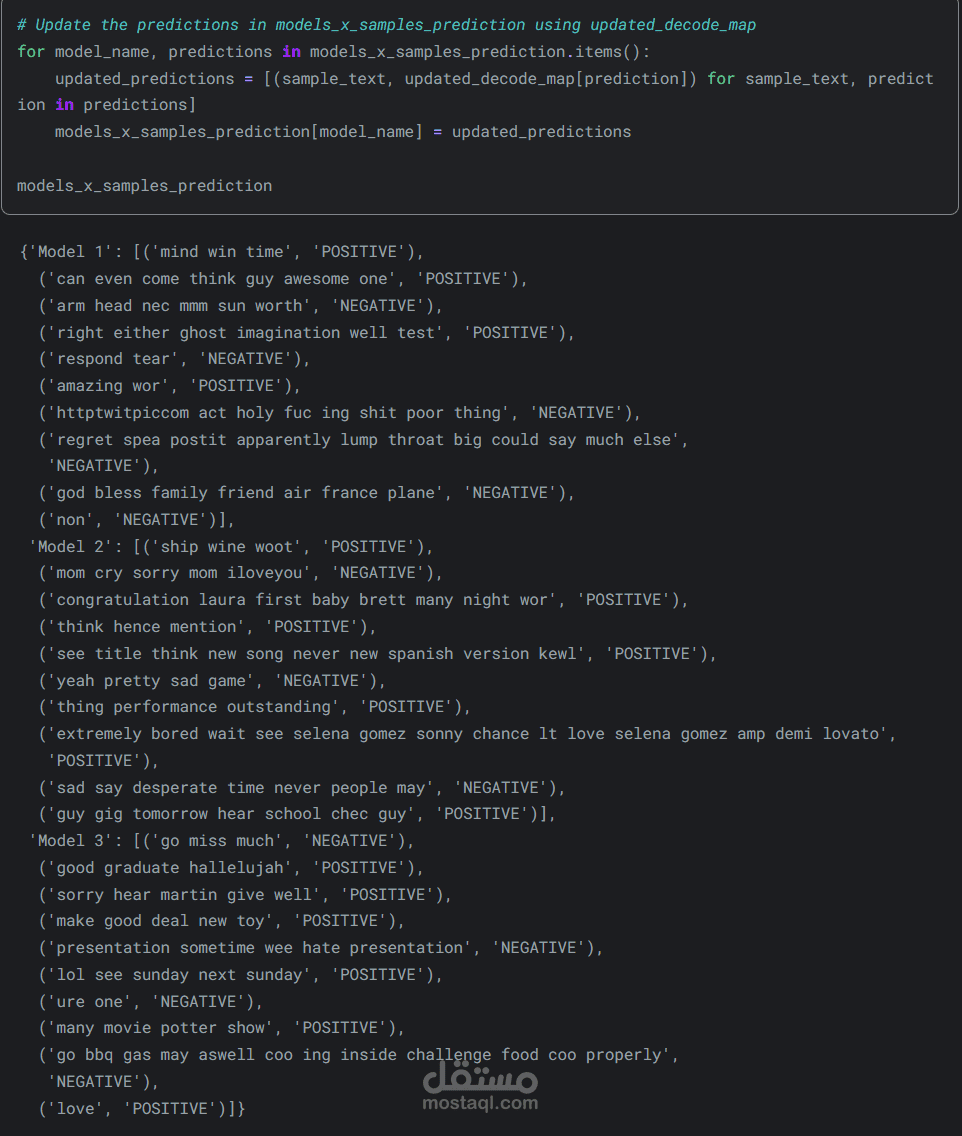
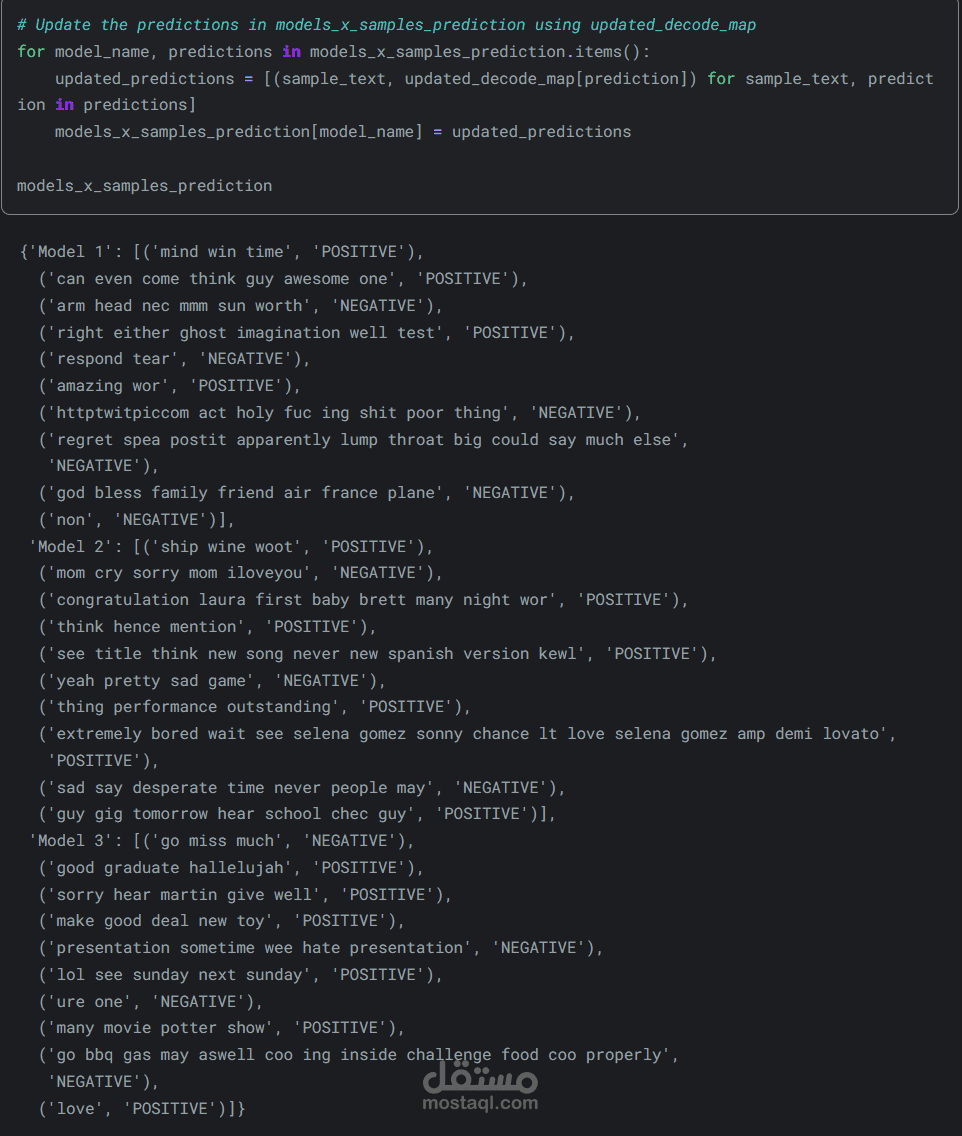
بعد التدريب، تم تقييم النماذج ومقارنة أدائها بناءً على دقة التصنيف، حيث حقق أفضل نموذج أعلى نسبة دقة. كما تم اختبار النماذج على بيانات جديدة لمقارنة التنبؤات بالقيم الفعلية، مما وفر رؤية واضحة وواقعية لأداء النموذج.