تحليل بيانات طبية وبناء نموذج تنبؤي (PIMA Diabetes Analysis)
تفاصيل العمل
مشروع متكامل لتحليل مجموعة بيانات PIMA Indians Diabetes للتنبؤ باحتمالية الإصابة بمرض السكري. يوضح المشروع مراحل علم البيانات (Data Science Pipeline) من البداية للنهاية.
ما قمت بتنفيذه:
معالجة البيانات (Preprocessing): التعامل مع القيم المفقودة (Missing Values) وتطبيع البيانات (Normalization).
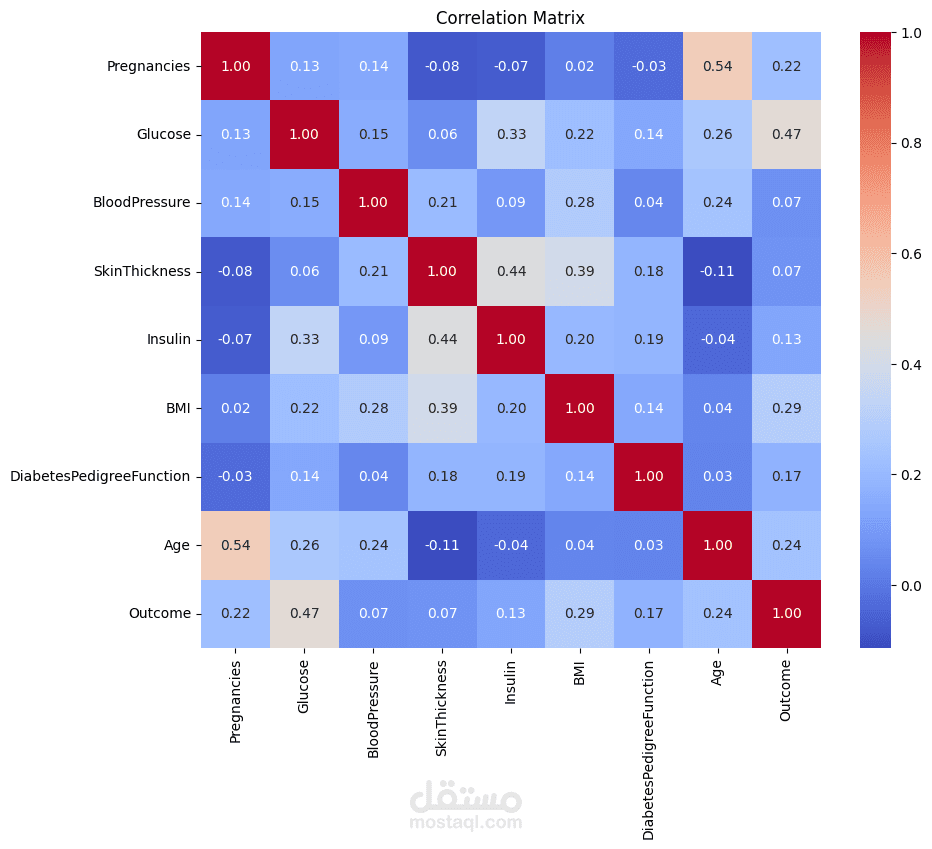
تحليل استكشافي (EDA): استخراج علاقات بين المتغيرات باستخدام الرسوم البيانية (Heatmaps & Histograms).
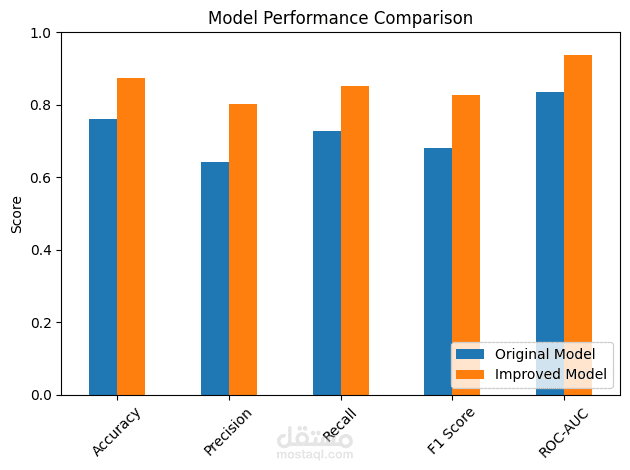
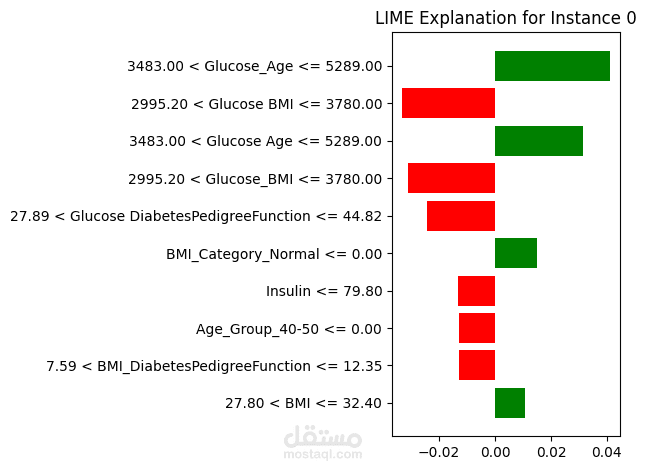
بناء النموذج: تدريب واختبار عدة خوارزميات (KNN, Decision Trees) واختيار الأفضل منها.
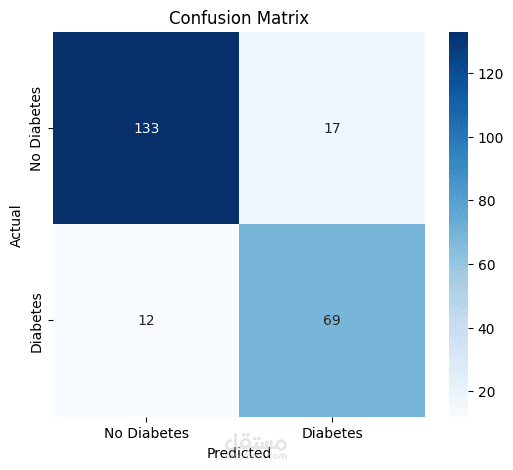
تقييم الأداء: استخدام مقاييس Precision, Recall, و F1-Score لضمان دقة النتائج.
التقنيات المستخدمة: Python, Pandas, Seaborn, Scikit-learn.