SmsClassifierNetwork
تفاصيل العمل
ملخص المشروع
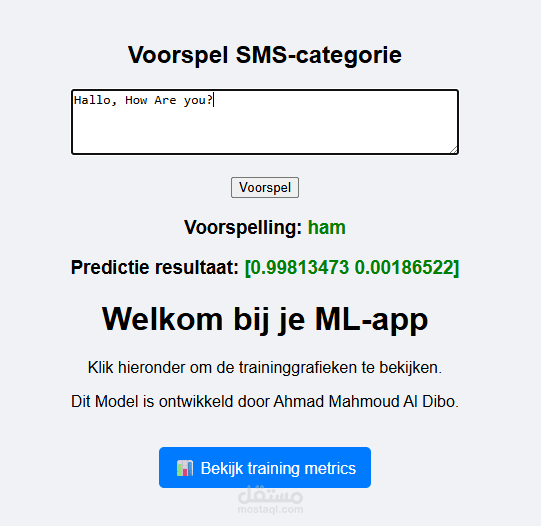
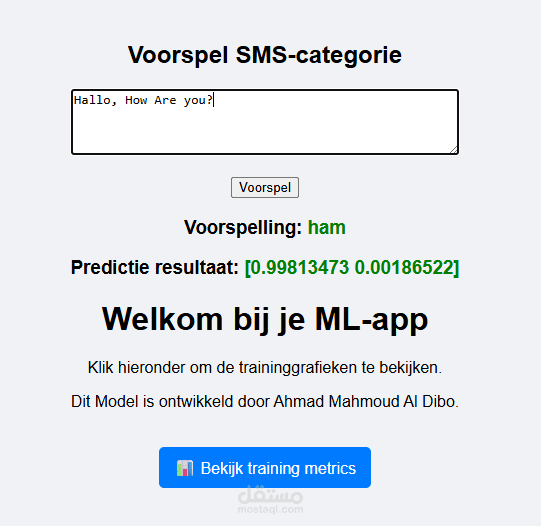
مشروع SmsClassifierNetwork هو نظام تصنيف نصي قائم على الشبكات العصبية المتكررة (LSTM) مُصمم لتصنيف رسائل SMS إلى فئتين أساسيتين:
Ham: الرسائل الطبيعية وغير الضارة
Spam: الرسائل غير المرغوب فيها أو المزعجة
الهدف العلمي والتقني
الهدف من المشروع هو معالجة النصوص الطبيعية (NLP) بهدف التدريب على تمييز الرسائل المزعجة من غيرها، وذلك عبر نموذج LSTM (Long Short-Term Memory)، وهو نوع من الشبكات العصبية المتكررة قادر على التقاط التتابع والسياق اللغوي داخل الرسائل — ما يجعل التصنيف أكثر دقة مقارنة بالطرق التقليدية فقط على أساس الكلمات الفردية.
الهيكل العام للنموذج
تمثيل الكلمات (Embeddings):
يتم استخدام تمثيلات كلمات مُدمجة مسبقاً (مثل GloVe) لتحويل الكلمات إلى متجهات عددية ذات معنى دلالي.
طبقة LSTM:
الشبكة المتكررة تعالج التسلسل النصي كاملاً، مما يساعد على استخلاص العلاقات بين الكلمات داخل الرسالة، وهو أمر مهم في مهام تصنيف النصوص.
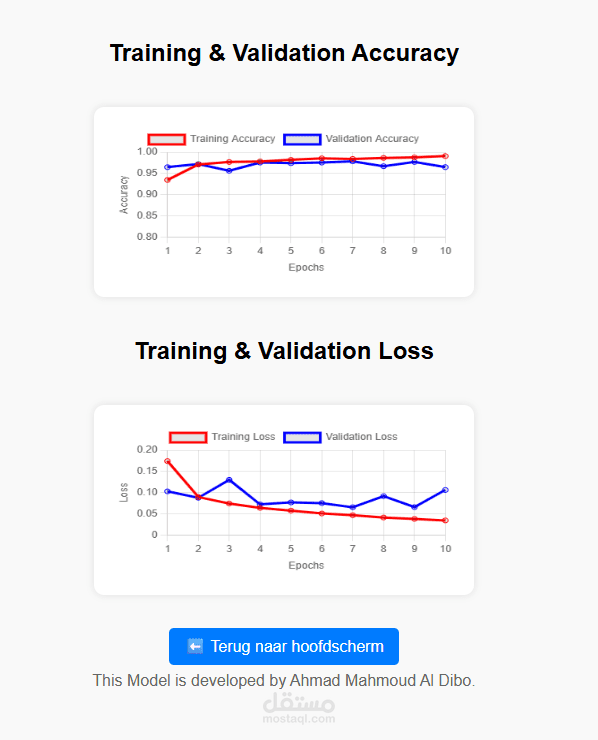
طبقة Dropout للتقليل من الإفراط في التعلّم (Overfitting):
تُستخدم لتقليل التعلّم الزائد على بيانات التدريب وتحسين التعميم على بيانات الاختبار.
طبقة المخرجات (Softmax):
تُحوِّل المخرجات إلى احتمالين (ham vs spam) باستخدام دالة softmax.
المدخلات والمخرجات النموذجية
المدخلات: نص رسالة SMS خام
المخرجات: احتمالات تنتمي لفئتي Ham أو Spam
طريقة التدريب: شبكات عصبية متكررة مع تمثيل مؤثر للغويات (مثل استخدام word embeddings).
أهمية وشمولية الحل
يُظهر المشروع فهمًا منهجيًا للتصنيف النصي باستخدام شبكات عميقة بدلاً من الطرق الإحصائية البسيطة (مثل TF-IDF + SVM/NB)، حيث أن LSTM يمكنه التعامل مع التسلسل والسياق داخل النصوص بشكل أفضل — وهو أمر أساسي في تعليم الآلة لمعالجة اللغة الطبيعية.
مجالات الاستخدام المحتملة
فلترة الرسائل في تطبيقات المراسلة
أنظمة كشف الاحتيال أو الرسائل المزعجة (Anti-Spam)
نماذج تعليم آلي للنصوص قابلة للتطوير في أنظمة الإنتاج