تحليل بيانات الطاقة لي مبنى كامل
تفاصيل العمل


وصف المشروع – Energy Consumption Prediction Pipeline
Energy Consumption Prediction Pipeline هو مشروع عملي في مجال تعلم الآلة (Machine Learning) يهدف إلى بناء خط معالجة بيانات (ML pipeline) قادر على التنبؤ باستهلاك الطاقة لأجهزة منزلية باستخدام بيانات بيئية ومستشعرات. المشروع مهيكل كـ Workflow كامل يتضمن ما يلي:
الهدف العلمي للمشروع
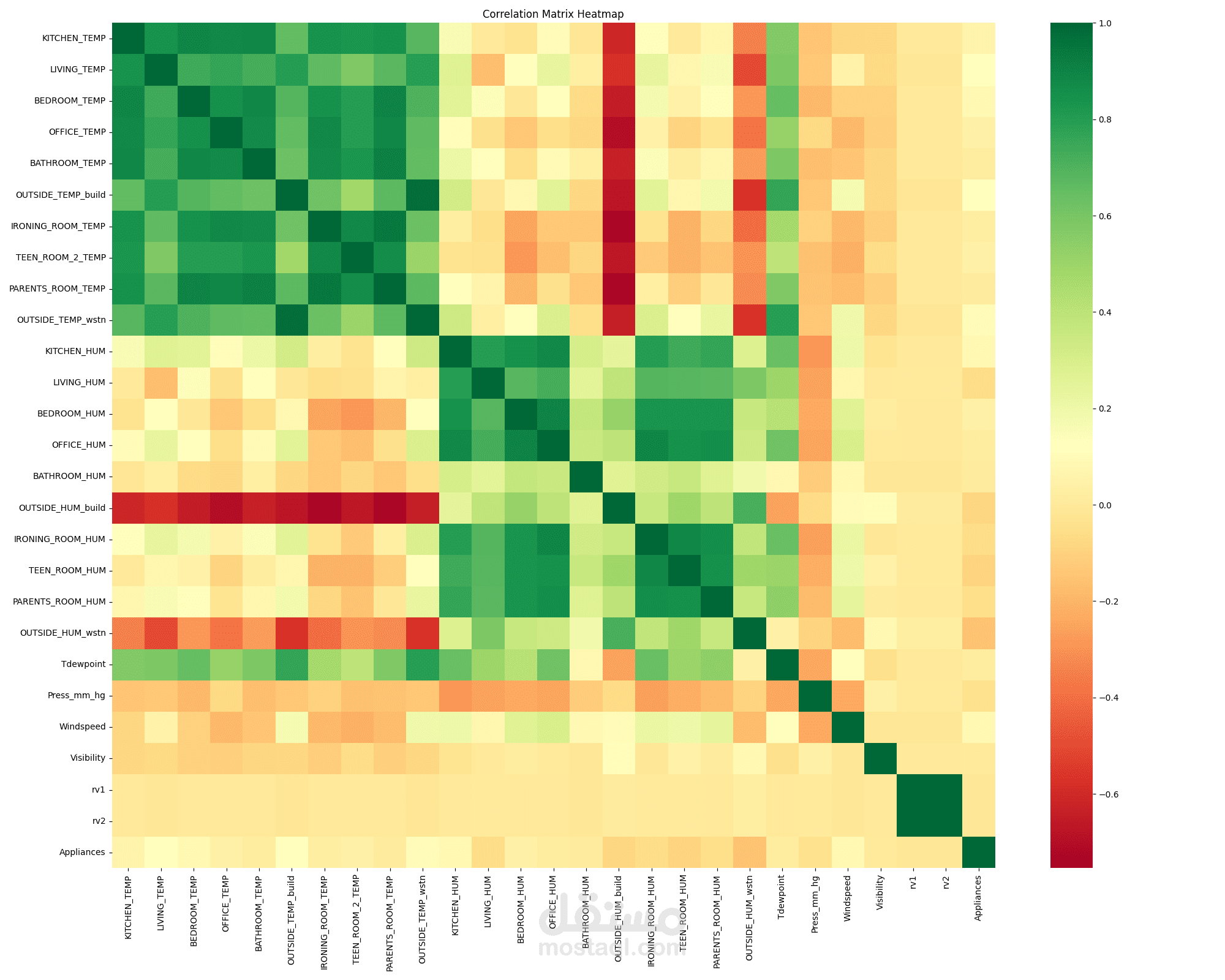
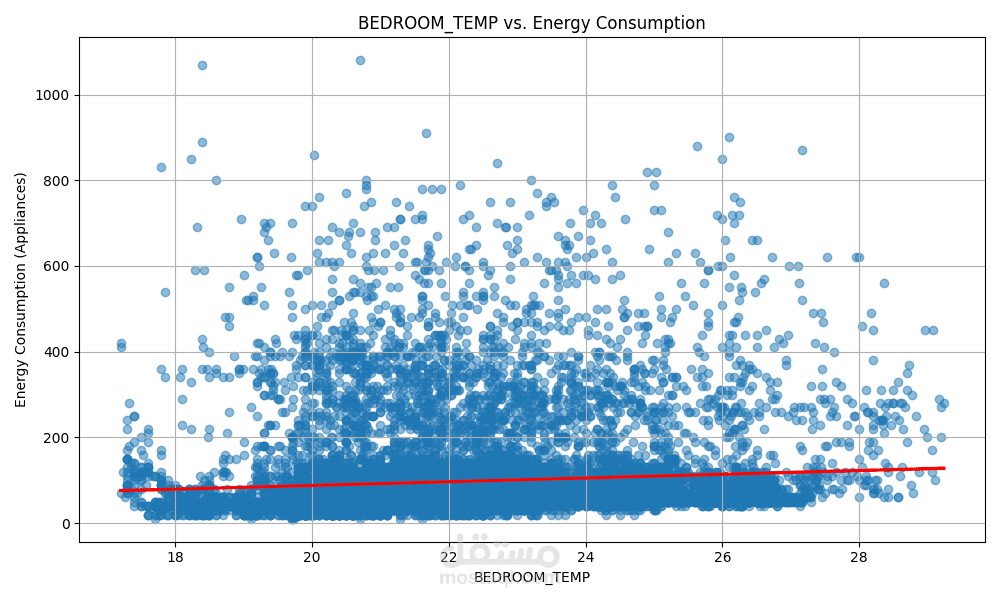
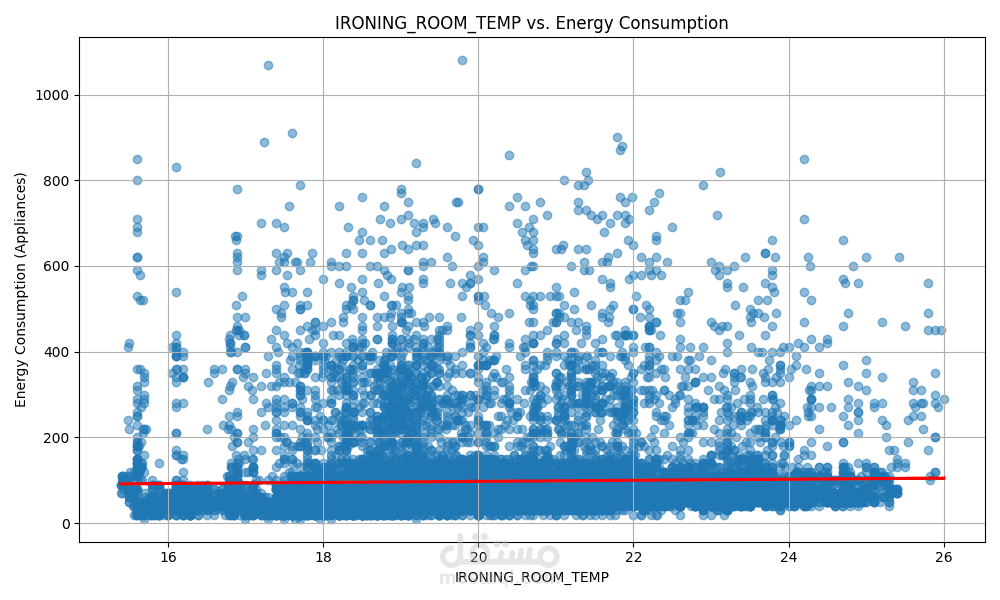
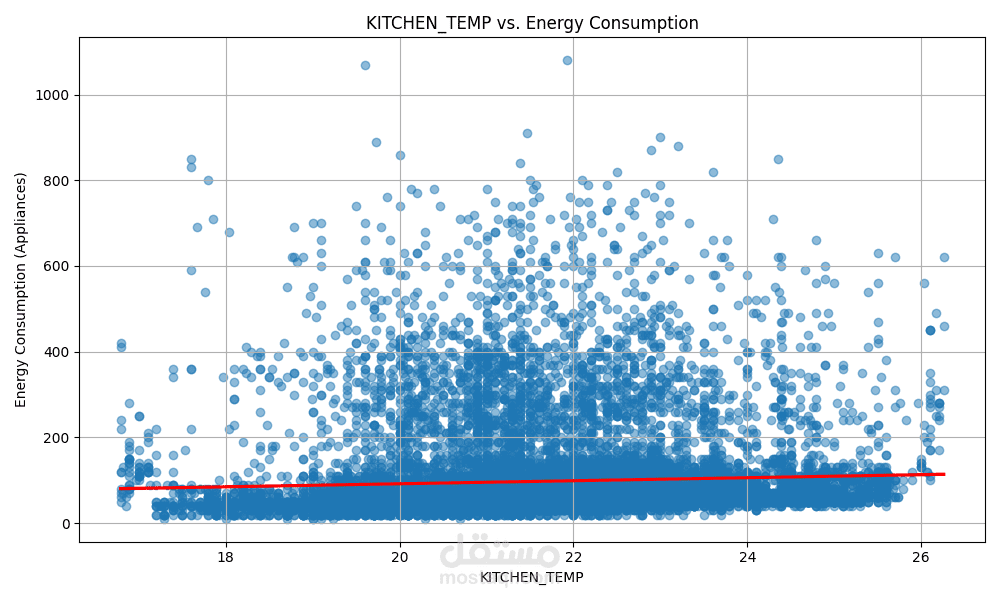
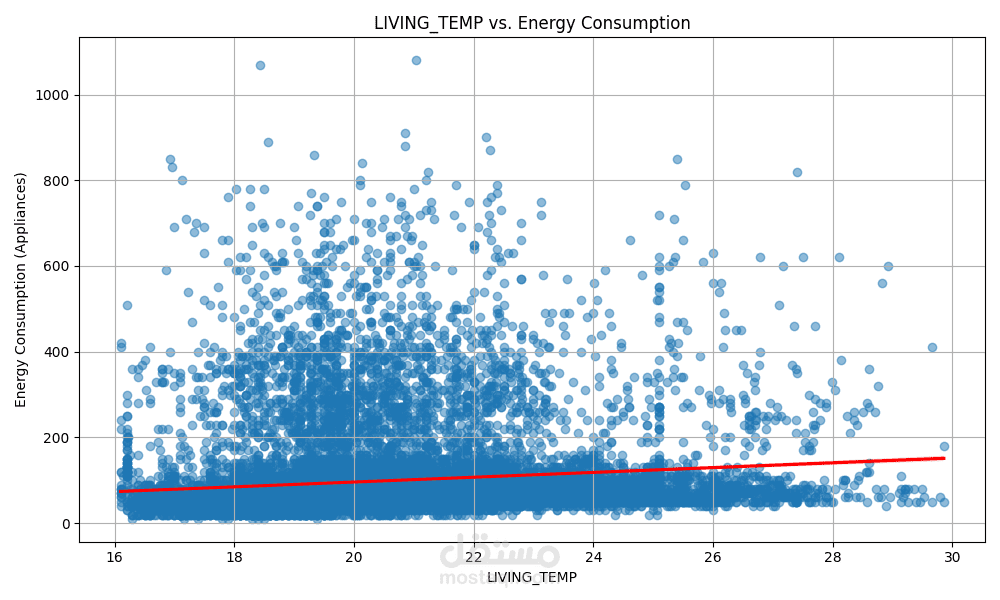
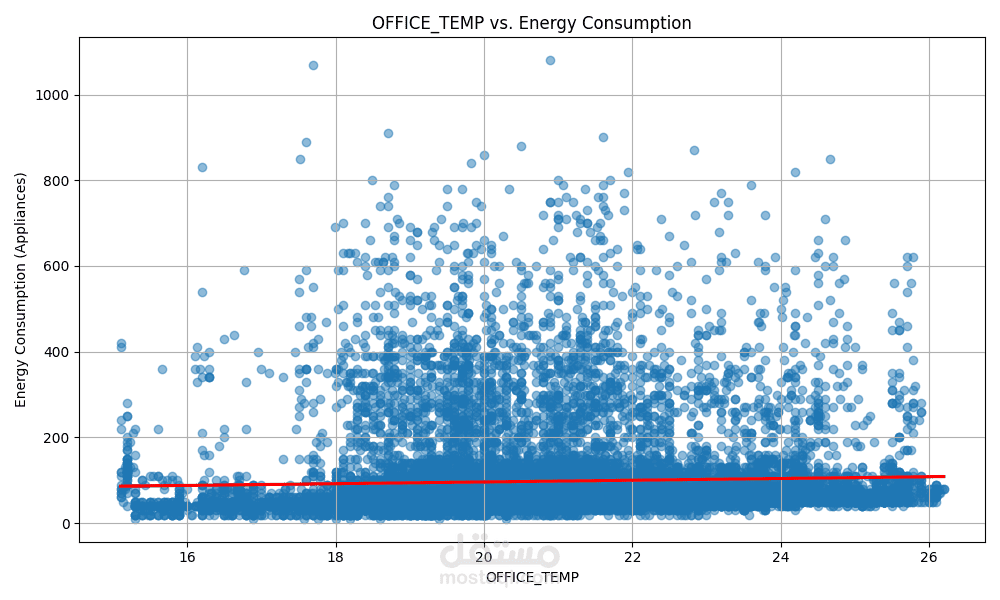
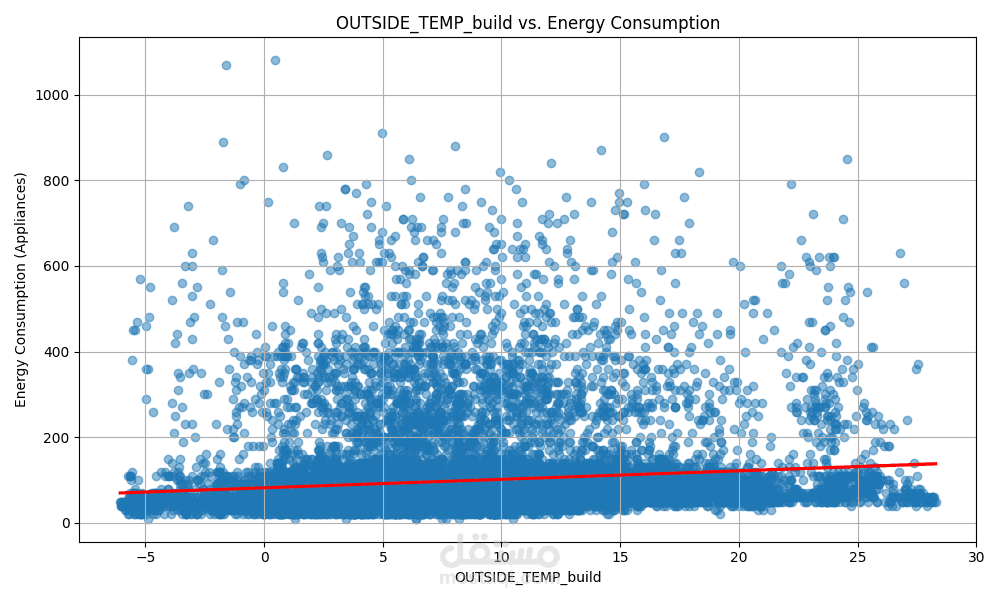
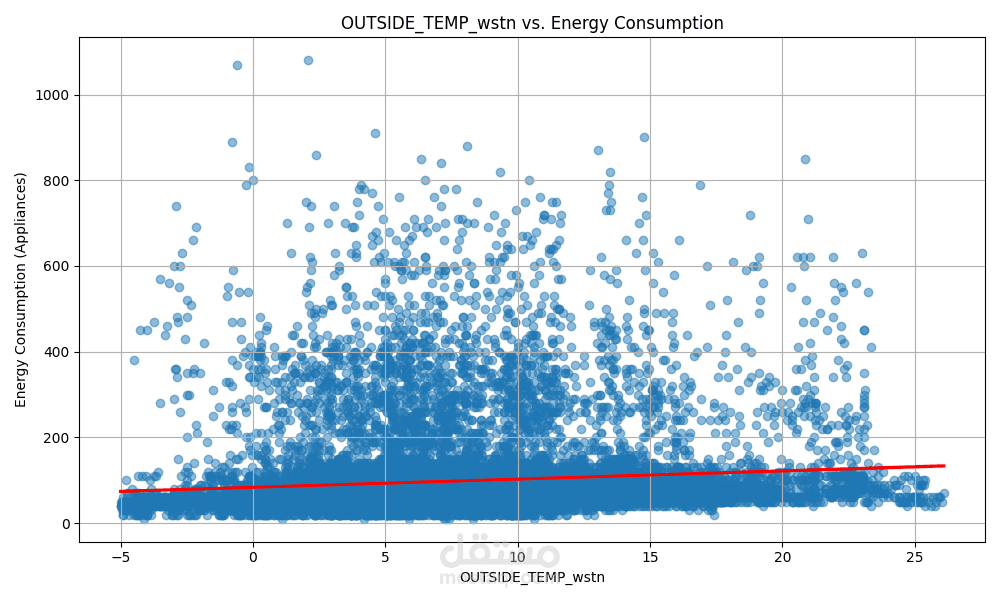
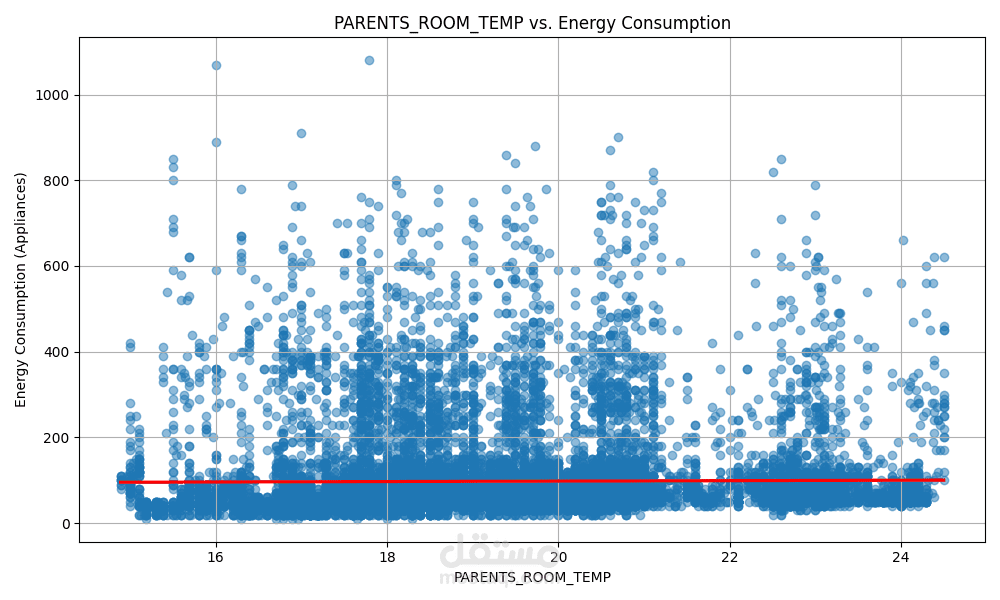
الهدف الأساسي هو التنبؤ بمستوى استهلاك الطاقة بناءً على ميزات متعددة مثل:
درجة الحرارة
الرطوبة
الضغط الجوي
قراءات أجهزة الاستشعار
باستخدام مجموعة من النماذج الإحصائية والخوارزميات التنبؤية، مع تحليل أداء كل نموذج لاختيار الأفضل منها.
المكوّنات التقنية الأساسية
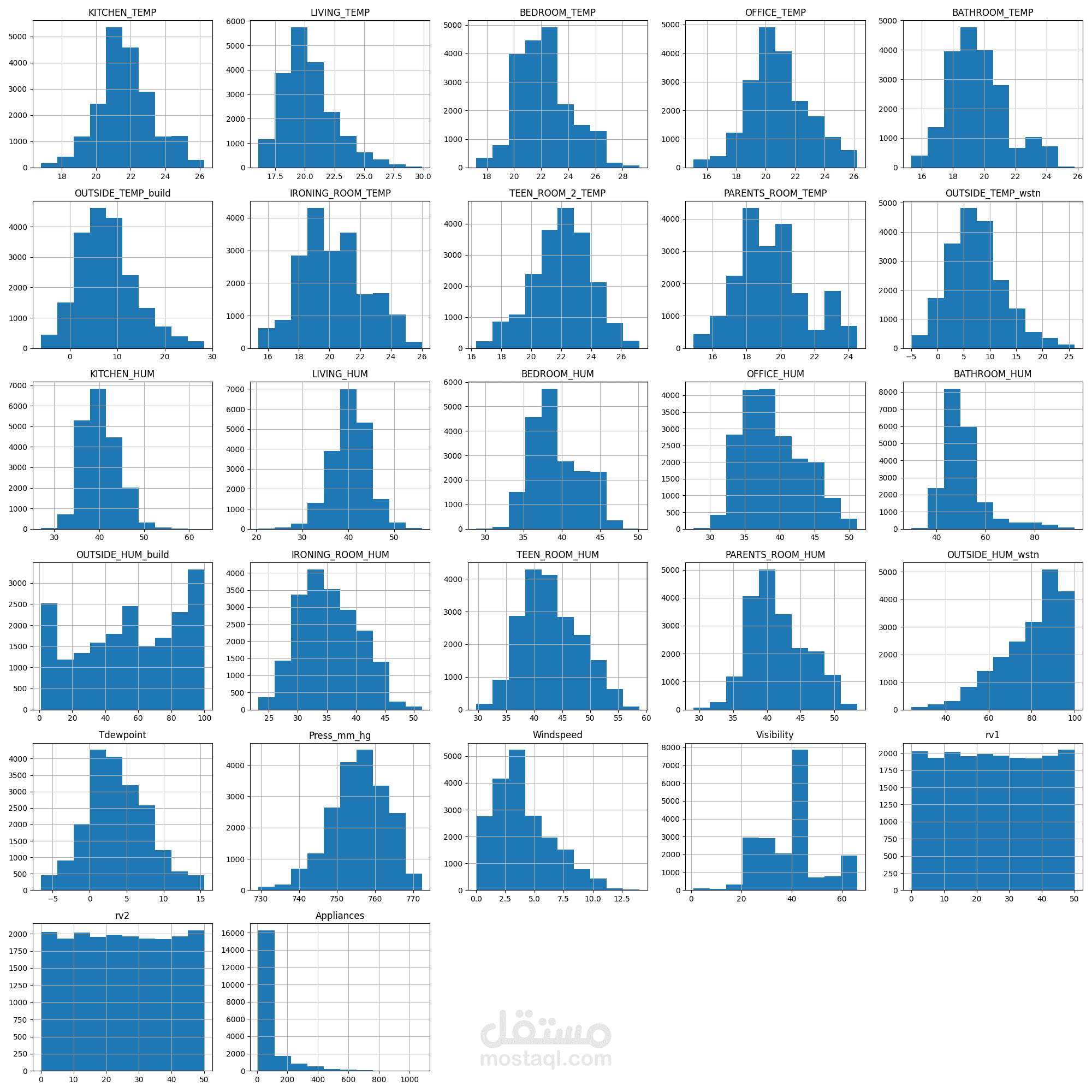
معالجة البيانات (Data Preprocessing):
تنقية البيانات من القيم الشاذة باستخدام IQR method.
تحليل skewness وتطبيق PowerTransformer.
تطبيع البيانات وتقسيمها إلى بيانات تدريب/اختبار.
تدريب النماذج وتقييمها:
يتم تدريب نماذج متعددة شائعة في التنبؤ مثل:
الانحدار الخطي (Linear Regression)
Ridge و Lasso
Random Forest
Gradient Boosting
SVR و XGBoost
ويتم حساب مقاييس الأداء مثل R²، RMSE، MAE لاختيار النموذج الأكثر كفاءة.
هيكلة المشروع:
src/: كود الخوارزميات والمنطق
data/: البيانات الخام والمعالجة
notebooks/: تحليل تجريبي واستكشافي
reports/: نتائج ورسوم بيانية لتقييم النماذج
تنظيم وتشغيل:
ملف main.py ينسّق العملية كاملة: تحميل البيانات، معالجة، تدريب النماذج، اختيار الأفضل، وتوليد التقارير.
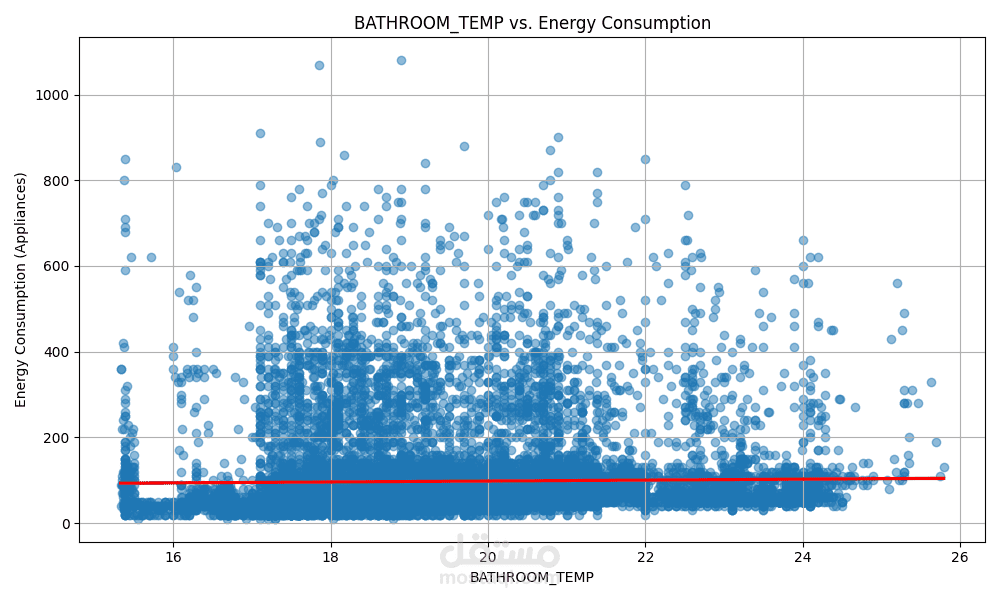
النتائج والمخرجات
نماذج متدربة مخزّنة كملفات Pickle
تقارير رسومية لنتائج النماذج
ملف CSV يحتوي على التنبؤات النهائية
تقييم علمي لأداء كل نموذج تنبؤي مستخدم في المشروع
التقنيات المستخدمة
Python 3.10+ مع مكتبات علم البيانات الشائعة:
pandas و numpy لمعالجة البيانات
scikit-learn و XGBoost لبناء وتقييم النماذج
matplotlib للرسوم البيانية