مشروع تحليل وتصنيف البيانات باستخدام خوارزميات تعلم الآلة المتقدمة (End-to-End Classification Project)
تفاصيل العمل
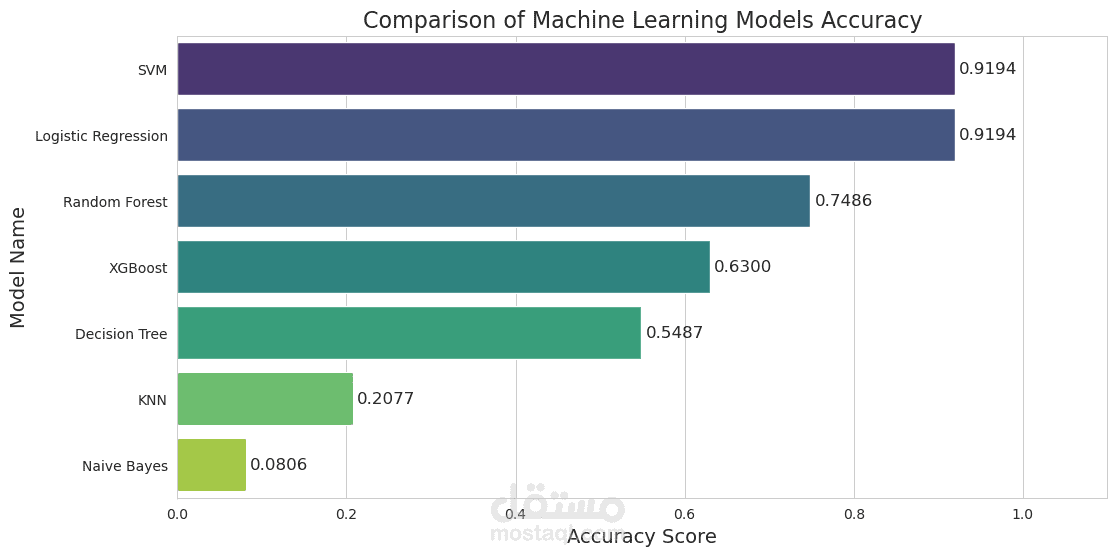
في هذا المشروع، قمت ببناء نظام ذكاء اصطناعي متكامل يهدف إلى تصنيف البيانات والتنبؤ بالنتائج بدقة عالية، حيث قمت بتطبيق دورة حياة كاملة لمشروع Data Science:
1. معالجة وتجهيز البيانات (Data Preprocessing):
التعامل مع البيانات غير المتوازنة (Imbalanced Data) باستخدام تقنيات Resampling لضمان حيادية الموديل.
تطبيق الـ Feature Scaling باستخدام StandardScaler لتحسين أداء الخوارزميات الحساسة للمسافات.
2. بناء النماذج (Modeling): قمت بتطبيق ومقارنة 7 خوارزميات مختلفة للوصول لأفضل أداء ممكن:
Linear Models: Logistic Regression
Probabilistic Models: Naive Bayes
Distance-based: K-Nearest Neighbors (KNN) & SVM
Tree-based: Decision Tree
Ensemble Methods: Random Forest & XGBoost
3. تحسين الأداء (Optimization):
استخدام Cross-Validation لتحديد أفضل Hyperparameters (مثل اختيار أفضل قيمة K في موديل KNN بدقة).
4. التقييم والمقارنة (Evaluation):
تقييم النماذج باستخدام مقاييس: Accuracy, Precision, Recall, F1-Score.
تحليل النتائج عبر Confusion Matrix.
إنشاء رسوم بيانية (Bar Charts) للمقارنة المباشرة بين دقة جميع النماذج وتحديد الأفضل بينهم.
الأدوات المستخدمة: Python, Scikit-Learn, Pandas, NumPy, XGBoost, Seaborn.