Classification d’Images Sentinel-2 par Méthodes de Machine Learning
تفاصيل العمل
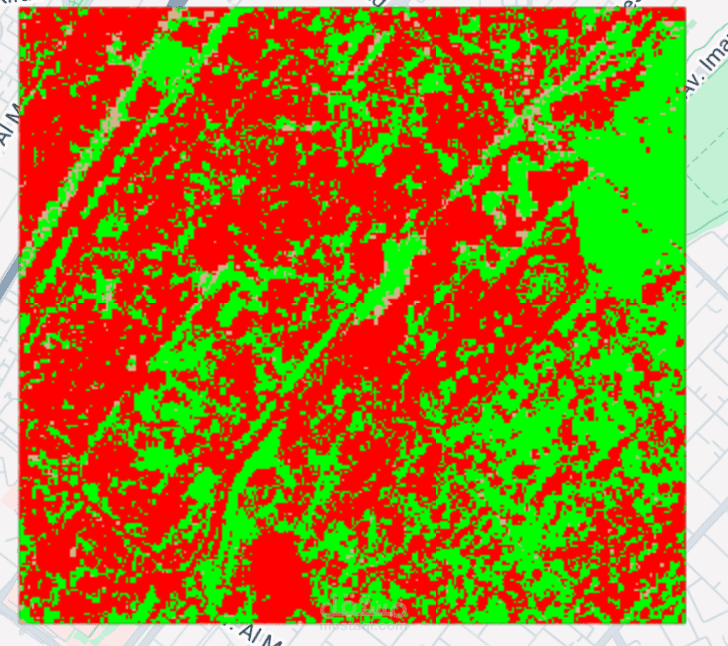
Description du projet : Classification d’images Sentinel-2 par méthodes de Machine Learning
Ce projet vise à produire une carte d’occupation du sol (ou de classes thématiques : urbain, végétation, eau, sols nus, cultures, etc.) à partir d’images Sentinel-2 (résolution 10–20 m) en appliquant des algorithmes de Machine Learning supervisés. L’objectif est de transformer des bandes spectrales et des indices (NDVI, NDBI, NDWI…) en une classification fiable, reproductible et facilement mise à jour.
Objectifs
Extraire et préparer des images Sentinel-2 sur une zone d’étude (Maroc ou autre).
Construire un jeu d’apprentissage à partir d’échantillons (polygones/points de référence) représentant chaque classe.
Entraîner et comparer plusieurs modèles de ML (ex. Random Forest, SVM, XGBoost, réseaux de neurones simples).
Générer la carte classifiée et évaluer sa qualité par des métriques (Accuracy, F1-score, matrice de confusion, Kappa).
Produire des cartes et statistiques exploitables (surfaces par classe, évolution temporelle si multi-dates).
Données et variables utilisées
Bandes Sentinel-2 (B2, B3, B4, B8 à 10 m, + bandes 20 m si utile).
Prétraitements : masquage nuages (QA60 / S2 Cloud Probability), mosaïque, reprojection, harmonisation temporelle.
Features :
bandes brutes,
indices spectraux (NDVI, NDWI, NDBI, SAVI…),
texture (optionnel) et/ou statistiques locales,
variables multi-dates (séries temporelles) pour mieux distinguer cultures/sols.
Méthodologie (workflow)
Collecte et nettoyage : sélectionner des images sans nuages, découper sur la zone, filtrer/masquer nuages.
Échantillonnage : constitution de données terrain (vérité-terrain) : points/polygones par classe, équilibrage des classes.
Entraînement ML : apprentissage supervisé (souvent Random Forest comme baseline robuste).
Classification : application du modèle sur toute l’image pour obtenir une carte pixel-par-pixel.
Post-traitements : filtrage spatial (majority filter), suppression du “bruit sel-poivre”, regroupement de classes si nécessaire.
Validation : split train/test, validation croisée, matrice de confusion, analyse des erreurs.
Outils possibles
Google Earth Engine (rapide pour Sentinel-2 + RF/SVM + séries temporelles).
Python (Rasterio, GDAL, scikit-learn, xgboost, geopandas) ou plateformes SIG (QGIS + plugins).
Production finale : GeoTIFF/COG, couche raster dans QGIS/ArcGIS, ou publication web (WMS/WMTS).
Résultats attendus
Une carte classifiée prête à l’usage.
Un rapport d’évaluation (métriques + discussion sur les confusions entre classes).
Des statistiques (surface par classe, éventuellement évolution entre années/saisons).
Une méthodologie reproductible (pipeline clair, paramètres, données d’entraînement documentées).
Si tu me dis la zone, les classes visées (ex : urbain/eau/végétation/sol nu/cultures) et si tu travailles sur GEE ou Python, je peux te proposer une version “fiche projet académique” + un plan de rapport + un workflow très concret.