تجميع dataset للأخبار مع نوع الخبر من عدة datasets
تفاصيل العمل
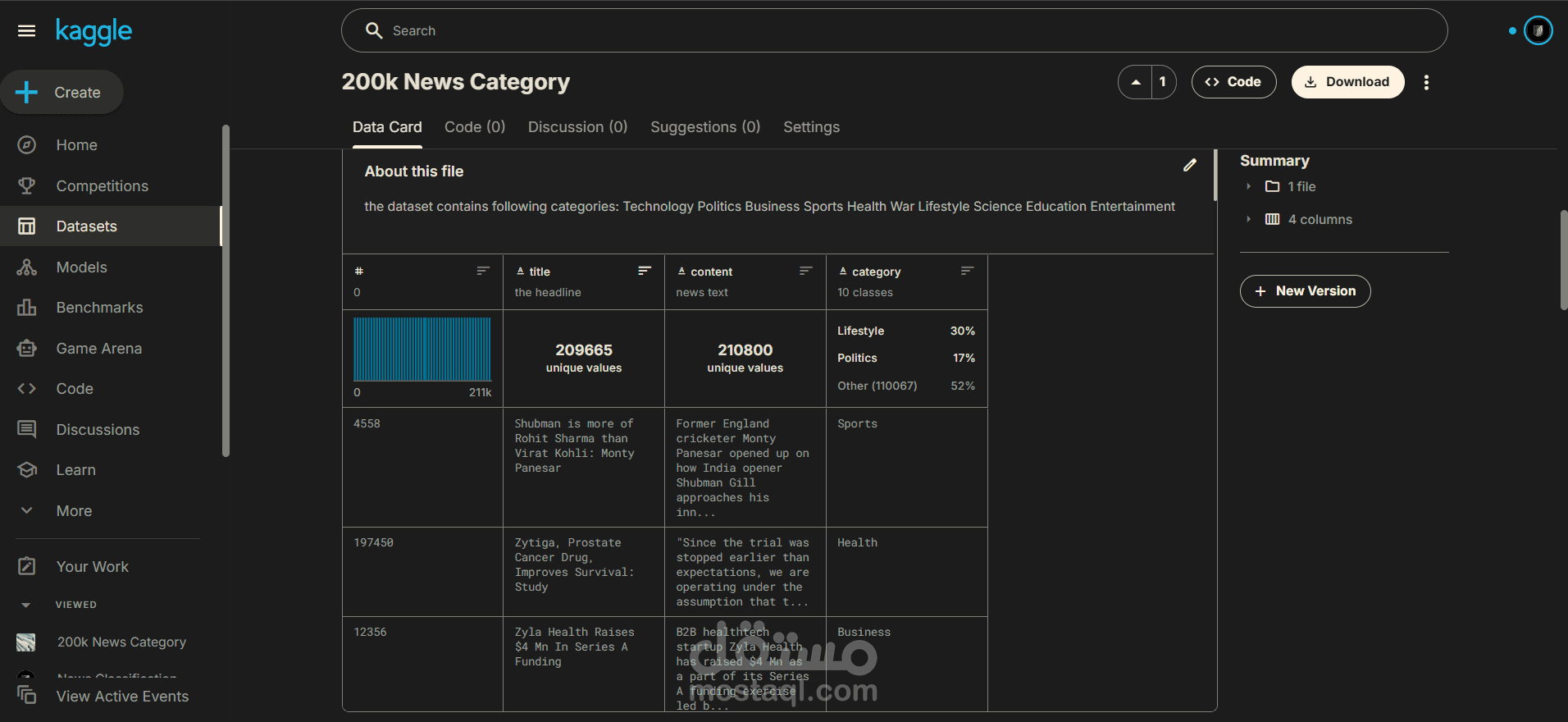
قمتُ بتنفيذ سلسلة من خطوات المعالجة المسبقة (Data Preprocessing) وتحليل جودة البيانات بهدف تجهيز داتاسيت الأخبار لاستخدامها في نموذج تصنيف نصوص. شملت المهام ما يلي:
دمج وتنظيف البيانات
توحيد عدة مصادر بيانات مختلفة في داتاسيت واحدة تضم أكثر من 200 ألف مقال إخباري.
توحيد أسماء الأعمدة لضمان اتساق البنية (title, content, category).
معالجة القيم المفقودة، إزالة الصفوف غير الصالحة، وتحويل أنواع البيانات حسب الحاجة.
استخراج ميزات نصية (Feature Engineering)
إنشاء متغير لعدد الأحرف في كل مقال (Character Length).
تطوير دالة Tokenization لاستخراج الكلمات من المحتوى النصي.
حساب عدد الكلمات في المقال (Word Count) باستخدام دالة مخصّصة.
تحويل النصوص إلى صيغة مناسبة للمعالجة مثل lowercase وإزالة العناصر غير النصية.
تحليل جودة المحتوى النصي
فحص التوزيع العام لطول المقالات وعدد الكلمات لضمان عدم وجود انحرافات مؤثرة.
التحقق من وجود مقالات قصيرة جداً أو غير مرغوبة قد تؤثر على أداء نموذج التصنيف.
تجهيز البيانات لتصبح جاهزة للخطوات التالية مثل التنظيف المتقدم، إزالة الضجيج، أو إنشاء تمثيلات عددية (embeddings).
تهيئة البيانات للنماذج
تجهيز الداتاسيت بعد preprocessing لتكون جاهزة للتغذية في خوارزميات تصنيف الأخبار.
ضمان صياغة البيانات بصيغة معيارية قابلة لإعادة الاستخدام في تجارب النماذج المختلف