Telecom Customer Churn Prediction & Segmentation
تفاصيل العمل
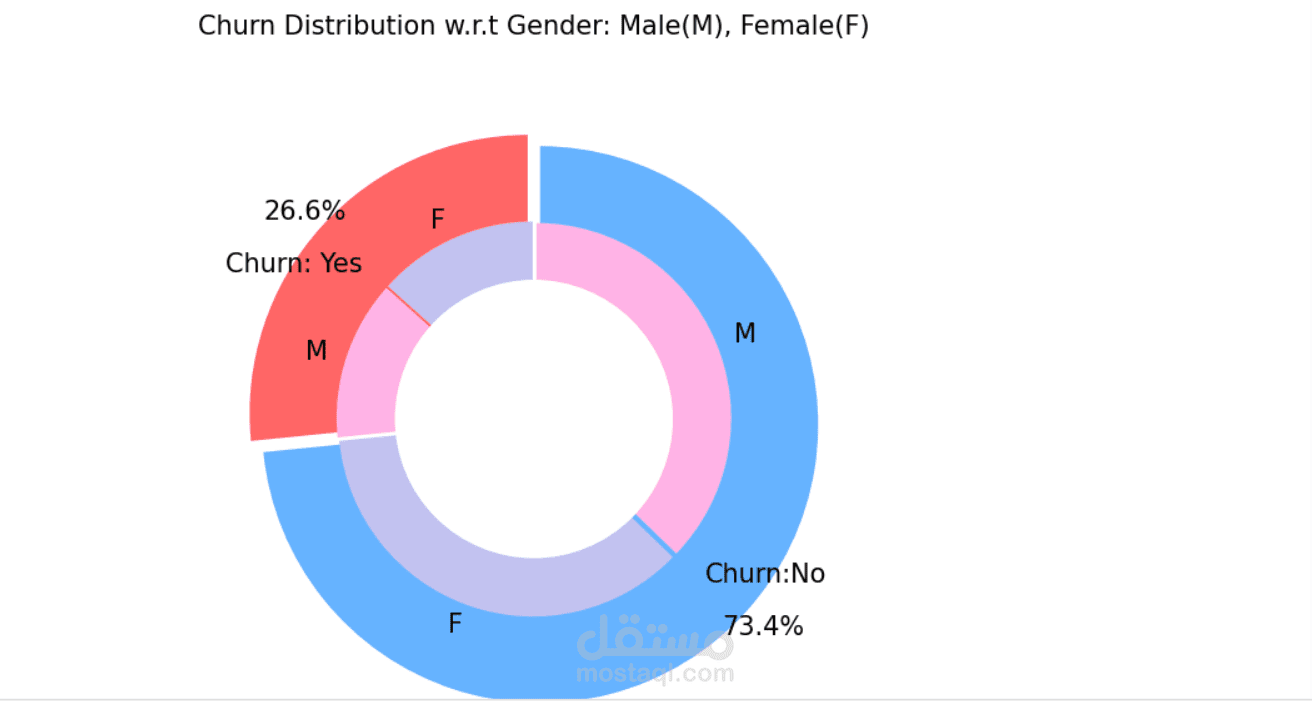
This project focused on predicting customer churn and segmenting customers to help businesses understand retention risks and behavioral patterns. I used Python along with Pandas, NumPy, Matplotlib, Scikit-learn, and Seaborn to handle the entire pipeline from data analysis to modeling and clustering.
I began by cleaning the dataset and performing Exploratory Data Analysis (EDA) to understand which factors had the strongest influence on churn. Through visualizations and statistical summaries, I identified key indicators such as contract type, tenure, and monthly charges. For example, customers with month-to-month contracts and higher monthly charges showed a significantly higher churn rate. These insights helped guide feature selection for the predictive model.
For churn prediction, I built a machine learning model using Gradient Boosting, which is effective at handling nonlinear relationships and interactions between features. After tuning the hyperparameters, the model achieved an accuracy of 84%, demonstrating strong predictive performance. I evaluated the model using metrics such as accuracy, precision, recall, and the confusion matrix to ensure balanced predictions across classes.
Beyond prediction, I performed customer segmentation using both K-Means and Hierarchical Clustering. These clustering methods helped identify patterns in customer behavior, such as high-value long-term customers or new subscribers at high risk of leaving. To make the clusters easier to visualize, I used PCA (Principal Component Analysis) to reduce the dimensionality of the dataset. This allowed me to create 2D visualizations that clearly showed how different customer groups were separated.
Overall, this project demonstrated my ability to perform data cleaning, EDA, predictive modeling, clustering, dimensionality reduction, and visualization, all within a practical customer analytics context.