US Air Quality Index
تفاصيل العمل
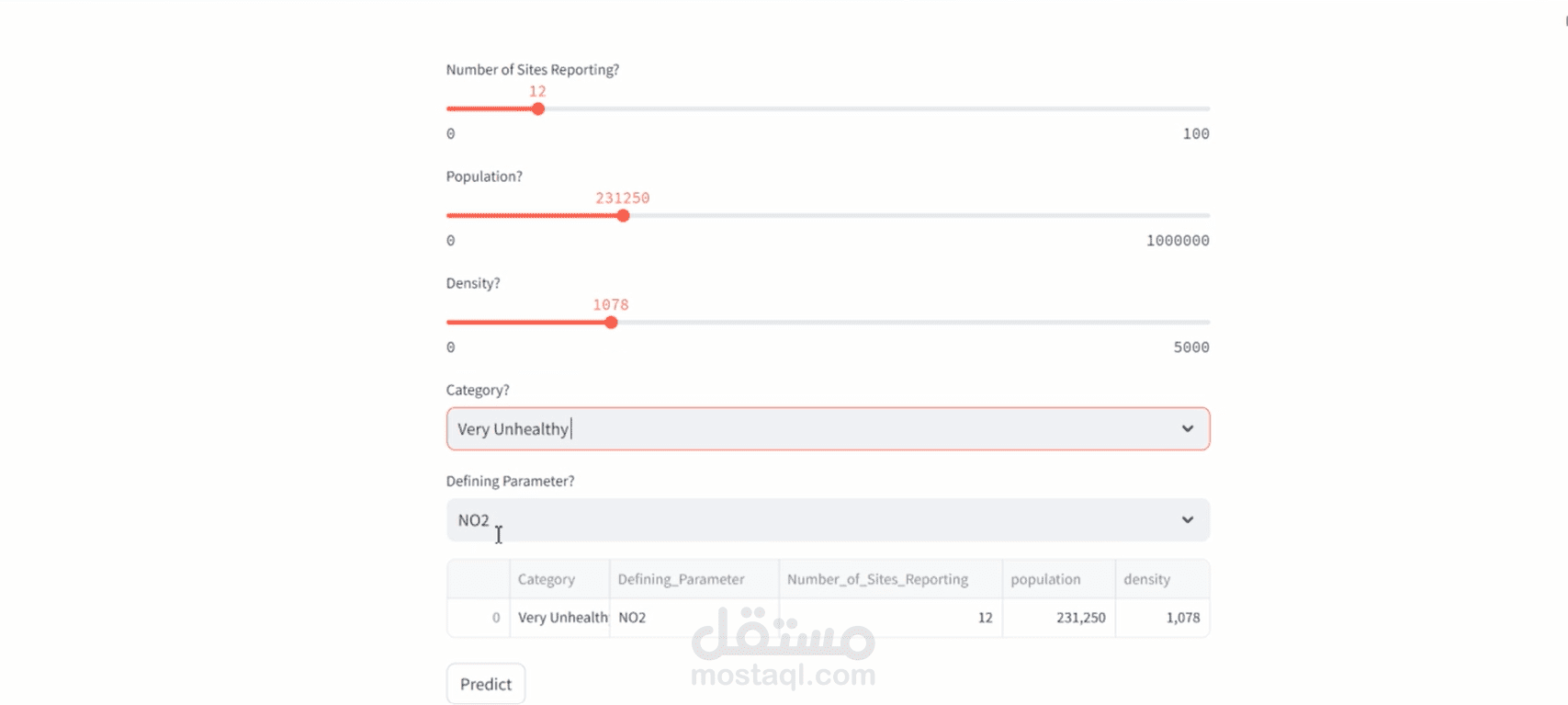
My project focused on analyzing and predicting the US Air Quality Index (AQI) using historical environmental datasets. The main goal was to understand air quality trends and build a predictive model that could estimate AQI levels based on key environmental factors.
I started by collecting and cleaning the data using Pandas and NumPy, making sure the dataset was consistent, properly formatted, and ready for analysis. I conducted exploratory data analysis (EDA) with Matplotlib and Seaborn, creating visualizations to identify pollution trends, seasonal patterns, and correlations between AQI and features such as temperature, humidity, and particulate matter levels. These visualizations were essential for understanding the underlying behavior of the data and for selecting meaningful features.
For the predictive component, I built machine learning models using Scikit-learn. I began with a Linear Regression model, which achieved around 86% accuracy. From there, I improved the model by performing feature selection, removing irrelevant or redundant variables, and applying hyperparameter tuning to optimize performance. I also experimented with more advanced models such as XGBoost, which provided better handling of nonlinear relationships and feature interactions.
To make the project interactive and accessible, I deployed the final model using Streamlit and hosted it on Streamlit Cloud. The web app allowed users to explore visualizations, adjust inputs, and receive real-time AQI predictions. This deployment demonstrated how data science can move from offline analysis to a fully functional application that others can interact with easily.
Overall, the project showcased my skills in data cleaning, analysis, visualization, machine learning, model optimization, and real-world deployment, resulting in a complete end-to-end data science workflow.